ai-intro
目标:
- 机器优势:机器的计算速度和准确性好。
- 目标:从数据中提取知识。不用预编码,构建模型,提取目标特征(学习经验,语言文本/图像音视频),解决问题/预测/决策辅助/模拟生成,扩展人的智能。
人工智能 Artificial Intelligence >> 机器学习 Machine Learning >> 深度学习 Deep Learning:
- 人工智能:感知、推理、行动、适应的程序
- 机器学习:用大量数据和算法训练机器学习规律。
- 深度学习:模拟人脑,用多层(分而治之)神经网络从大量数据中学习。生成、处理复杂数据结构,如图像、声音、文本。
训练:从数据中学习,以最大限度地减少其预测与实际结果之间的误差。但避免过度学习,要有泛化能力,以便可以对新的、看不见的数据做出准确的预测。
应用场景:
自动化与效率优化:替代重复性劳动或优化资源分配。例如:
- 制造业用机器人手臂实现流水线自动化;
- 物流行业通过路径优化算法降低运输成本。
模式识别与预测:通过机器学习算法(如线性回归、神经网络)分析历史数据,识别隐藏规律并预测未来趋势。例如: - 金融领域预测股价波动、信用风险评估;
- 医疗领域通过影像数据预测疾病进展(如肺癌早期筛查)。
决策支持与智能分析:基于数据生成决策建议,辅助人类判断。例如: - 电商平台根据用户行为推荐商品(如亚马逊的 “购买此商品的顾客还购买”);
- 城市交通管理通过实时流量数据调整红绿灯时长。
复杂问题建模与模拟生成:处理传统方法难以解决的非线性问题。例如: - 气候模型模拟全球变暖趋势;
- 蛋白质结构预测(如 AlphaFold 解决生物学难题)。
本质:从数据到价值的转化路径
- 数据驱动决策替代经验驱动:例如:披萨店老板通过销售数据的线性回归模型(而非主观经验)预测夏威夷披萨销量,减少顾客等待时间(对应文档案例)。
- 处理 “不确定性” 问题:传统方法难以量化的变量(如用户偏好、天气影响)可通过 AI 建模。例如:
- 电影公司用自然语言处理分析社交媒体舆情,预测新片票房;
- 物流公司用强化学习应对实时路况变化,动态调整配送路线。
- 突破人类认知边界:处理海量数据或复杂关系,发现人类难以察觉的规律。例如:
- 基因测序数据的 AI 分析加速新药研发;
- 天文观测数据的机器学习处理,发现新星系或行星。
模型
flowchart LR
subgraph 数据准备
A1[数据收集]
A2[数据预处理:归一化-量纲;标准化-符合分布]
A3[训练集、验证集、测试集分割]
A4[模型构建:
1. 定义模型(假设函数)
2. 定义损失函数(评估模型好坏)
3. 优化参数(寻找最优解) ]
end
subgraph 模型训练
B1[模型训练]
B2[前向传播-预测值,计算损失;反向传播-梯度下降,参数更新]
B3{验证集性能达标?}
end
A1 --> A2 --> A3 --> A4
A4 --> B1
B1 --> B2 --> B3
B3 -- 否 --> B1
B3 -- 是 --> 模型微调flowchart LR
subgraph 模型微调
C1[模型微调]
C2[使用特定任务数据进行微调]
C3{微调后性能达标?}
end
subgraph 模型固化与部署
D1[模型固化]
D2[模型测试、部署]
end
subgraph 推理与监控
E1[接收新输入数据;数据预处理;模型推理;输出预测结果]
E2[监控与反馈]
E3{性能下降?}
E4[模型重新训练或微调]
end
C1 --> C2 --> C3
C3 -- 否 --> C2
C3 -- 是 --> D1
D1 --> D2
D2 --> E1
E1 --> E2 --> E3
E3 -- 是 --> E4将模型比作一个数学函数:
- 训练:调整函数参数(如 y=ax+b 中的 a,b),使得输入 x 能准确预测 y。
- 推理:固定参数 a,b,直接计算新输入 x′ 对应的 y′=ax′+b。推理改变的是输入到输出的映射过程,而非模型本身。
推理模型:慢思考(思路):背景,要/不要,目标
指令模型:快思考(操作):prompt
| 决策顺序 | 是否关键 |
|---|---|
| 1. 选定任务类型⭐ | 必须 |
| 2. 选定损失函数⭐ | 最关键 |
| 3. 适配输出层激活函数 | 必须 |
| 4. 选择优化器 | 推荐 Adam |
| 5. 设置评估指标 | 视需求而定 |
| 损失函数,是预测与真实标签之间的差异,是模型训练的目标函数。其他参数(如激活函数、优化器、评价指标等)会根据损失函数和任务类型进行适配。 |
常见任务与损失函数对应关系(推荐组合)
根据任务类型(分类、回归)、输出形式(概率分布、数值)、标签格式(one-hot、整数、连续值)来决定
| 任务类型 | 输出层激活函数 | 损失函数 | 标签格式 | 推荐优化器 | 推荐评估指标 |
|---|---|---|---|---|---|
| 二分类 | sigmoid |
binary_crossentropy |
0/1 或 [0,1], [1,0] |
Adam / SGD | accuracy, precision, recall |
| 多分类(≥3类) | softmax |
categorical_crossentropy |
one-hot 编码 | Adam / SGD | accuracy |
| 多分类(整数标签) | softmax |
sparse_categorical_crossentropy |
整数(如 0, 1, 2) | Adam / SGD | accuracy |
| 回归任务 | linear |
mse(均方误差) |
连续值 | Adam / SGD | mae, mse |
| 带类别权重的分类 | softmax |
categorical_crossentropy + class_weight 参数 |
one-hot | Adam | accuracy, f1-score(需自定义) |
| 如何确定这些组合? |
- 官方文档推荐
- Keras/TensorFlow 官方文档对每种损失函数都提供了适用场景说明。
- 示例:Keras Losses
- 论文或教程参考
- ImageNet/CIFAR 等标准数据集上常用组合
- Kaggle 比赛中常见做法
- 学术论文中描述的实验设置
- 经验法则
- 分类任务 →
crossentropy - 回归任务 →
mse或mae - 图像分类 →
Adam+crossentropy+accuracy - 数据不平衡 → 加入
class_weight参数调整类别权重
问题分类:
graph TD
A[确定问题类型] --> B{有标签数据,有明确的目标值?}
B -->|是| C[监督学习]
B -->|否| D[非监督学习/强化学习]
%% 监督学习分支
C --> E{任务类型?}
E -->|分类| F[分类模型:识别
例1:情感分析(正面/负面)
例2:账户风险等级(高/中/低)]
E -->|回归| G[回归模型:预测
例1:大促销量预测(对于不同促销/广告投放方案)
例2:房价线性回归]
E -->|排序/推荐| H[排序模型]
%% 非监督学习分支
D --> I{任务类型?}
I -->|聚类/降维| J[非监督模型:聚类,挖掘无标签数据的隐藏分组
例:复购行为的用户群体特征;
降维,异常检测:识别离群数据
例:信用卡欺诈交易识别]
I -->|与环境交互| K[强化学习模型:动态决策优化
条件:需定义状态-动作-奖励机制
路径优化场景
例1:交通信号控制优化
例2:物流配送路线规划
资源调度场景
例1:电商动态定价策略
例2:云计算服务器资源分配
交互决策场景
例1:自动驾驶车辆控制
例2:游戏AI策略生成]
%% 分类模型细分
F --> L{数据规模与复杂度?}
L -->|小规模/线性| M[逻辑回归/SVM线性核]
L -->|中规模/非线性| N[随机森林/XGBoost]
L -->|大规模/图像/语音| O[CNN/Transformer]
%% 回归模型细分
G --> P{是否有时序依赖?}
P -->|否| Q[线性回归/梯度提升树]
P -->|是| R[ARIMA/LSTM/Prophet]
%% 非监督模型细分
J --> S{任务目标?}
S -->|分组| T[K-means/DBSCAN]
S -->|降维/特征提取| U[PCA/自编码器]
%% 强化学习细分
K --> V{状态空间维度?}
V -->|低维| W[Q-learning]
V -->|高维| X[DQN/PPO]
%% 特殊数据类型分支
A --> Y{数据是否含特殊结构?}
Y -->|时序数据| R
Y -->|图结构| Z[GCN/GNN]
Y -->|多模态数据| AA[CLIP/多模态Transformer]
模型训练
房价预测场景(涉及概念:参数、导数、梯度、梯度下降)
1.目标锚定:让预测值接近真实值
- 场景:用房屋面积
、房间数 预测房价 ,假设线性关系。 - 模型:
( 是特征权重, 是偏置)。 - 参数向量:
,目标是找到最优 ,让 尽可能接近真实房价 。
2.量化误差:定义损失函数如均方误差(MSE)
- 问题:如何衡量“预测值与真实值的差异”?
- 距离表达,向量视角,若将真实值
和预测值 视为向量,则欧氏距离: ,几何意义是两点在空间中的直线距离。 - 欧式距离满足:
- 消除误差正负抵消:欧氏距离通过平方运算将误差转为非负值,确保所有偏差被 “累加” 而非 “抵消”(如预测误差 -5 和 +5 相加为0,无法反映真实偏差)。
- 将误差向量聚合成标量:用单个数值衡量模型整体表现,欧氏距离将
维误差向量压缩为一个标量值,便于通过优化算法(如梯度下降)最小化该值。 - 良好的数学性质(可导性): 优化算法需计算导数(梯度)来指导参数更新,欧氏距离的平方形式(即均方误差)具有连续可导性,且导数形式简单,便于高效计算。
- 改进欧式距离 ->均方误差MSE = 欧氏距离的平方除以样本数:
( 是样本数, 是第 套房的数据) - 使得均方误差 MSE 满足:
- 标准化差异:除以
消除样本量影响,使不同数据集的误差可比;
- 标准化差异:除以
- 结果:
越小,说明 越接近 ,模型越优。 -> 最小化损失函数
3.分析参数影响:偏导数 -> 梯度
- 问题:参数
怎么变,才能让 减小的最快? - 工具:偏导数,衡量“单个参数变化时,损失的变化率”。
- 以
为例,求偏导数: - 意义:
- 若
: 增大 → 上升(需减小 来降损失); - 若
: 增大 → 下降(需增大 来降损失)。
- 若
- 以
- 问题:模型有多个参数(
),如何综合它们的影响? - 工具:定义梯度=损失函数
Loss相对于各参数的偏导数。梯度定量描述该参数发生微小变化时,损失函数会如何变化(变化的速率和方向),是参数对损失函数瞬时影响的数学度量,是优化算法(如梯度下降↓)用来最小化↓损失函数的核心信息。 - 本质:梯度是“多元函数变化率的合力方向”,是损失变化最快的方向。
- 证明:梯度方向是“损失变化最快的方向”:梯度方向是损失函数增长最快的方向,反方向则是损失下降最快的方向,可最快(用最快速度)逼近损失的局部最小值。
- 工具:方向导数(函数沿任意方向的变化率)+ 向量点乘。
- 定义:参数沿单位向量
方向变化时,损失的变化率(方向导数)为: ( 是 与 的夹角, 是梯度的模长) - 结论:
- 当
( 与 同向): ,方向导数最大 → 梯度方向是损失上升最快的方向; - 当
( 与 反向): ,方向导数最小 → 梯度反方向是损失下降最快的方向。
- 当
- 定义:参数沿单位向量
4.优化参数策略:
Stochastic Gradient Descent,SGD,随机梯度下降
- 问题:知道“损失下降最快的方向”后,如何用它优化参数?
- 方法:梯度下降,沿梯度反方向逐步调整参数,迭代公式:
( 是学习率,控制每一步更新的“步长”) - 迭代逻辑(房价场景):
- 初始化:随机选
,此时预测误差大( 大); - 算梯度:用
计算 ,找到“当前最陡下坡方向”; - 更参数:沿梯度反方向走一步(
),损失下降; - 重复:直到梯度趋近于
(损失无法再显著下降)。
- 初始化:随机选
5.收敛终点:梯度为0时的最优解
- 现象:当
时,梯度反方向的“下坡力”消失,参数更新幅度趋近于 。 - 本质:此时到达损失函数的“谷底”(假设是凸函数,如线性回归的MSE),损失无法再减小。
- 结果:
,模型预测值接近真实房价,训练完成。
6.评估
最终推导链(嵌入细节版)
每一步都紧扣房价场景,从“想预测准”的朴素目标,到用数学工具(导数、梯度)分析优化方向,再到用梯度下降策略逼近最优解,逻辑环环相扣。这样就能彻底理解:参数向量是优化对象,导数是“微观调整依据”,梯度是“宏观变化方向”,梯度下降是“高效优化策略”,最终实现预测值接近真实值的目标。
一些参数
激活函数:
- ReLU函数 √:
,只有激活(值非0),才会把值传递到下一层网络; - Sigmoid/Tanh:决定神经元输出的强度(或是否输出有效信号),影响信息如何传递到下一层。Sigmoid函数,
,输出范围(0,1),常用于二分类输出层,但存在梯度消失问题(饱和区域梯度趋近于0)
优化器的学习率调度(Learning Rate Scheduling)
- 衰减策略:如线性衰减(
),初期大学习率快速收敛,后期小学习率精细调整。 - 预热(Warmup):先增大学习率再衰减,避免初始阶段梯度不稳定。
批量大小(Batch Size)
- 小批量(如32-256):梯度含噪声,可跳出局部极小值,但训练速度慢。
- 大批量(如8k-64k):梯度更稳定,但易过拟合,需配合学习率放大策略。
评估指标
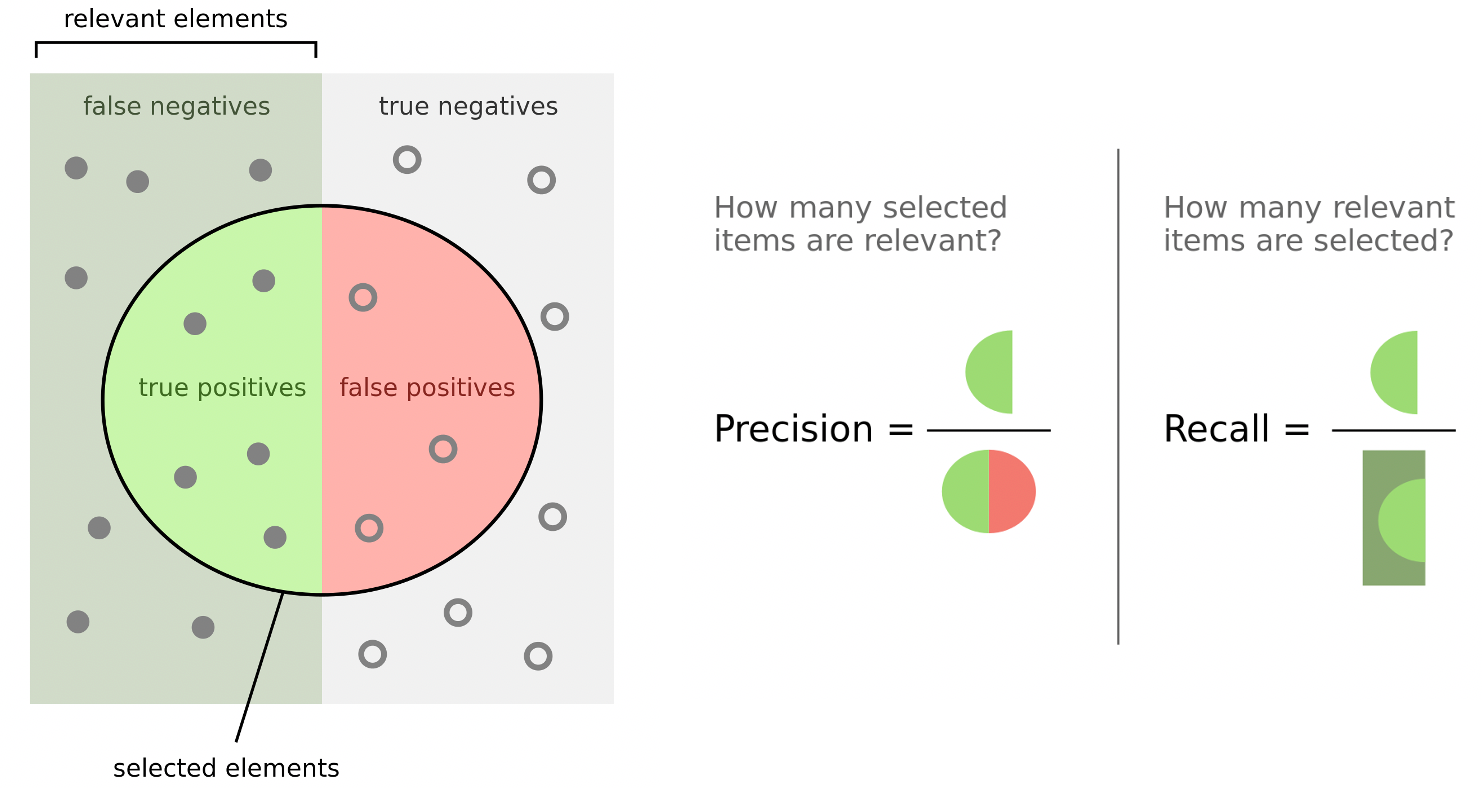
- 圆内,selected element:识别的文本块;true positives(左亮绿):正确识别;false positives(右红):错误识别为正相关,实际为负相关
- 左侧,relevant elements:相关的文本块;false neratives(左灰绿):错误识别为负相关,实际为正相关;
准确率 accu =
圆内,“How many selected items are relevant?”(在项目中的被选择部分,有多少是相关的?)
- 精确率 Precision =
,真正,识别√为正相关 - Precision ↑越高,说明模型(预测为正类)的可靠性↑越强。
左侧,“How many relevant items are selected?”(在项目中的相关部分,有多少被选择了?)
- 召回率 Recall =
- Recall ↑越高,说明模型(对正类样本)的识别能力↑越强。
- 平衡模型 “选得准”(精确率)和 “选得全”(召回率)的能力。考虑这两个比例,当且仅当精确率和召回率都较高时,F1 分数才会高。
- 调和平均的特性使其对较低的一方更敏感
- 若精确率=1.0(完美),但召回率=0.1(很差),则
(极低)。 - 若精确率=0.5,召回率=0.5,则
(中等)。
- 若精确率=1.0(完美),但召回率=0.1(很差),则
- F1的最优解:当精确率=召回率时,F1达到最大值,且 精确率=召回率的值越大,F1越大。例如:
- 若精确率=0.8,召回率=0.8,则
。
- 若精确率=0.8,召回率=0.8,则
问题
优化失败:
梯度消失/爆炸:深层网络中梯度反向传播时逐渐减小(消失)或增大(爆炸),可通过残差连接(ResNet)、梯度裁剪(Clipping)缓解。
- 消失:浅层网络参数更新缓慢,深层参数几乎不更新,模型表现为 “只学浅层特征,深层特征无效”。
- 爆炸:参数更新幅度剧烈,导致模型输出值溢出(如 NaN),训练过程崩溃。
- 鞍点(Saddle Point):梯度为0但非极值点,可通过动量法(Momentum)、自适应学习率(如Adam)逃离。
| 方法 | 原理 | 适用场景 |
|---|---|---|
| 残差连接(ResNet) | 通过短路连接( |
深层CNN(如ResNet、DenseNet) |
| 梯度裁剪(Gradient Clipping) | 设定梯度阈值(如" |
循环网络(RNN/LSTM) |
| 合适的激活函数 | ReLU系列(ReLU/Leaky ReLU)导数在正数区域为1,避免梯度衰减;Swish等平滑激活函数减少梯度消失 | 全连接层、CNN |
| Batch Normalization | 归一化各层输入,稳定激活函数梯度范围 | 各类神经网络 |
| 权重初始化策略 | Xavier/Glorot初始化(适配线性激活)、Kaiming初始化(适配ReLU),控制初始权重尺度 | 网络初始化阶段 |
| LSTM/Gated RNN | 门控机制(遗忘门、输入门)控制梯度流动,缓解RNN中的梯度消失 | 序列建模任务 |
graph TD
A[训练损失高] --> B{测试损失是否高?}
B -->|是| C[模型偏差,模型无法拟合数据的真实规律:增加模型复杂度/验证集和测试集分布一致]
B -->|否| D[优化问题,模型可以拟合,但未找到最优参数:调整学习率,自适应学习率(如Adam)/权重初始化/数据归一化和标准化]
E[训练损失低] --> F{测试损失是否高?}
F -->|是| G[过拟合,模型过度训练学习到噪声,泛化能力差:数据增强/正则化]
F -->|否| H[模型良好]过拟合问题。模型可能会过度学习训练数据中的噪声和特殊细节,导致在测试数据上表现不佳。表现为,模型在训练集上损失低,但在测试集上损失高。解决方法:
- 增加训练数据量或数据增强(如图像翻转、旋转)。
- 正则化(在损失函数中添加参数平方和(L2)或绝对值和(L1),迫使参数趋近于0)、Dropout(随机丢弃部分神经元,避免神经元间过度依赖)。
- 早停(Early Stopping):当测试集损失不再下降时停止训练。
L1倾向于产生稀疏参数(部分权重为0),L2使权重整体更小,前者适用于特征选择,后者适用于防过拟合。
L1正则化
- 原理:在MSE损失函数中加入参数向量
的绝对值之和,公式为:
其中是正则化强度超参数,控制对参数的约束程度。 - 效果:倾向于使部分参数变为0,从而实现特征选择。例如在房价模型中,可能将与房价无关的特征对应的权重置0,简化模型结构。
L2正则化(权重衰减) - 原理:在MSE中加入参数向量的平方和,公式为:
,系数 是为了求导方便。 - 效果:使参数值趋近于0但不会为0,通过压缩参数的大小,降低模型对单一特征的依赖,避免参数过大导致模型过于复杂。例如,防止某个特征的权重过大,使得模型过度关注该特征而忽略其他特征。
以L2正则化为例,在反向传播计算梯度时,正则化项也会对梯度产生影响: - 原始MSE梯度:对
求偏导(以房价模型为例): - 加入L2正则化后的梯度:
- 梯度分量叠加:正则化项
对 求导后,产生新的梯度分量 ,并与原始梯度相加。 项使得 每次更新时都会额外减去一个与自身成正比的值,从而迫使 逐渐向0收缩,实现对参数的约束。
多层神经网络:
- 向前传播,预测,为反向传播提供中间结果和损失值。将输入数据从输入层逐步传递到输出层,计算出预测值。
- 每一层中:
- 线性计算:对输入数据进行线性变换,公式为
,即输入数据 与对应权重 相乘后求和,再加上偏置 。 - 激活函数:激活函数是将输出值映射到一个区间(满足任务输出要求如概率、归一化值),使模型学习/拟合数据中的非线性关系(如分段函数),逼近任意连续函数。
- 线性计算:对输入数据进行线性变换,公式为
- 逐层传递:将上一层激活后的输出作为下一层的输入,重复上述线性计算和激活函数运算,直至数据传递到输出层,得到最终的预测值。
- 计算损失:在输出层得到预测值后,将预测值与真实标签对比,计算损失函数(如均方误差 MSE),用于衡量模型当前预测的准确性 。这一步是为后续反向传播提供优化目标。
- 每一层中:
- 反向传播,“学习”,更新参数,使模型在后续前向传播中能输出更准确的预测。基于前向传播计算的损失,从输出层向输入层反向传递误差,计算损失函数对每个参数(权重和偏置)的梯度,进而更新参数。
- 计算梯度:从输出层开始,根据损失函数对输出层的梯度(如
),结合前向传播中保存的中间变量,利用链式法则逐步计算出损失对每一层参数的梯度。例如在房价案例中,计算出输出层的梯度后,进一步计算隐藏层的梯度 ,以及对权重和偏置的梯度 、 、 、 。 - 参数更新:根据计算得到的梯度,使用梯度下降公式
对每一层的权重和偏置进行更新。如在 update_parameters函数中,通过减去学习率与梯度的乘积,同时更新隐藏层和输出层的参数、 、 、 。 - 循环迭代:完成一次反向传播和参数更新后,再次进行前向传播计算新的预测值和损失,然后继续反向传播更新参数,不断重复这个过程,直至模型收敛(损失不再显著下降) 。
- 计算梯度:从输出层开始,根据损失函数对输出层的梯度(如
模型评估与选择:
- k折交叉验证:数据集分为k份,每次用k-1份训练、1份验证,重复k次取平均,避免单次验证集划分偏差。
- 适用于数据量有限时,通过交叉验证更可靠地评估模型泛化能力,多次取平均,降低偶然误差。
- 混淆矩阵:用于评估分类模型表现,尤其是在不平衡数据集上,展示真实标签与预测标签的对比情况。
- 训练集与测试集分布匹配。若训练集为2020年数据,测试集为2021年数据,可能因分布差异导致“不匹配”,需确保数据分布一致(如按时间顺序划分)。
机器学习训练营 | python入门到进阶 | :
LLM学习笔记:最好的学习方法是带着问题去寻找答案 | 腾讯技术工程 | 2025年05月12日 17:35:从使用到浅层原理
datawhale-AI3-reasoning
huggingface.co/spaces/open-llm-leaderboard-CSDN博客
- https://huggingface.co/open-llm-leaderboard
大模型技术体系开源影响力评估方法及榜单首次发布_大模型 体系贡献度评估-CSDN博客 | | curtime: 2025-05-10T21:45:32+08:00 - https://github.com/brucecui0120/OSIR-LMTS
基础
一、数学基础技术
核心作用:为模型构建提供理论支撑与算法推导工具
| 技术方向 | 关键内容 | 应用场景 | |
|---|---|---|---|
| 线性代数 | 矩阵运算、特征分解(PCA/SVD)、向量空间变换 | 降维、特征表示、神经网络权重更新 | |
| 概率论与统计 | 概率分布(高斯/伯努利)、贝叶斯推断、假设检验、最大似然估计,探索性数据分析(EDA) | 生成模型(VAE)、不确定性建模、模型评估 | |
| 微积分 | 梯度计算、链式法则、凸优化理论(梯度下降/牛顿法) | 模型参数优化、损失函数最小化 | |
| 信息论 | 熵、交叉熵、互信息 | 损失函数设计(如CE Loss)、特征选择 |
二、算法基础技术
核心作用:构成模型架构的底层算法模块
- 传统机器学习算法
- 分类与回归:
- 线性模型(LR)、决策树(CART)、支持向量机(SVM)、K近邻(KNN)
- 技术特点:依赖人工特征工程,适用于中小规模数据
- 聚类与降维:
- K-means、层次聚类、PCA、t-SNE
- 典型应用:数据预处理、可视化、无监督表征学习
- 深度学习基础模块
- 神经元与网络层:
- 全连接层(FC)、激活函数(ReLU/Sigmoid)、归一化层(BatchNorm)
- 核心逻辑:模拟生物神经元的信息传递与非线性变换
- 基础架构组件:
- 卷积层(CNN):局部连接+权重共享,提取空间特征
- 循环层(RNN):隐藏状态传递,处理时序依赖
- 注意力机制(Attention):动态加权关键信息,如Transformer的自注意力
三、数据处理技术
核心作用:保障数据质量与模型输入适配性
| 技术类型 | 关键技术 | 实施场景 |
|---|---|---|
| 数据预处理 | 数据清洗(去噪/缺失值处理)、特征标准化(Z-score)、归一化(Min-Max) | 所有模型的输入阶段 |
| 特征工程 | 特征选择(卡方检验/RFE)、特征提取(词袋模型/TF-IDF)、特征变换(one-hot编码) | 传统机器学习、NLP基础任务 |
| 数据增强 | 图像:旋转/翻转/噪声添加;文本:同义词替换/掩码;时序:时间偏移 | 解决数据量不足、提升模型泛化能力 |
四、优化与训练技术
核心作用:保障模型收敛与性能优化
-
损失函数体系:
- 分类任务:交叉熵损失(CE Loss)、焦点损失(Focal Loss)
- 回归任务:均方误差(MSE)、平均绝对误差(MAE)
- 生成任务:对抗损失(GAN Loss)、变分下界(ELBO)
-
优化算法:
- 基础算法:随机梯度下降(SGD)、动量梯度下降(Momentum)
- 自适应算法:Adam(结合动量与自适应学习率)、RMSprop
- 技术演进:从单步更新到二阶优化(如L-BFGS),提升收敛效率
-
正则化技术:
- L1/L2正则化(防止权重过大)、Dropout(随机失活神经元)、早停(Early Stopping)
- 核心目标:缓解过拟合,提升模型泛化能力
五、评估与解释技术
核心作用:量化模型性能并增强可解释性
-
性能评估指标:
- 分类:准确率(Acc)、精确率(Precision)、召回率(Recall)、F1值、AUC-ROC
- 回归:均方误差(MSE)、决定系数(R²)
- 生成:FID(特征距离)、IS(初始得分)
-
模型解释技术:
- 局部解释:LIME(局部可解释模型无关解释)、SHAP值(基于博弈论的特征归因)
- 可视化解释:CNN的类激活映射(CAM)、注意力权重热力图
六、工程化支撑技术
核心作用:实现模型从研发到落地的工程化流程
- 框架与工具:
- 深度学习框架:PyTorch/TensorFlow(模型构建与训练)、JAX(加速计算)
- 自动化工具:MLflow(实验管理)、DVC(数据版本控制)
- 部署优化:
- 模型压缩:剪枝(Pruning)、量化(Quantization)、知识蒸馏(KD)
- 推理加速:TensorRT(NVIDIA优化)、ONNX Runtime(跨平台部署)
七、技术演进脉络与交叉融合
- 从传统到深度:
- 传统机器学习依赖“特征工程”,深度学习通过“端到端学习”自动提取特征
- 模块融合案例:
- CNN+RNN:用于视频分析(CNN提取空间特征,RNN处理时间序列)
- Transformer+GAN:如DALL·E(自注意力机制结合生成对抗训练)
- 新兴基础技术:
- 神经符号系统(融合神经网络与符号逻辑)、神经辐射场(NeRF,3D场景表示)
总结:基础技术的层级关系
数学理论(线性代数/概率) → 算法设计(模型架构) → 数据处理(输入适配)
↓ ↓ ↓
优化训练(参数更新) → 评估解释(性能验证) → 工程化(落地部署)
这些基础性技术构成了机器学习与深度学习的“基础设施”,无论是序列模型、CNN还是生成模型,其核心创新均基于对上述技术的组合与改进。例如,Transformer的自注意力机制本质是“加权求和”(线性代数)与“Query-Key-Value映射”(算法设计)的结合,而GPT的训练则依赖大规模数据增强、自适应优化算法(如AdamW)等工程化技术的支撑。
CRT
定义:
CTR,Click-Through Rate,点击(通过)率,广告展示→点击的转化率。
CTR = 点击次数 / 曝光次数 × 100%。广告展示 1000 次,被点击 20 次,则 CTR=2%。
┌──────────────────────────────────────────────────────────────┐
│ 数据层挑战 │
│ ┌────────────┐ ┌─────────────┐ ┌──────────────┐ │
│ │ 冷启动处理 │ │ 噪声过滤 │ │ 多源特征融合 │ │
│ │ (相似性迁移)│ │ (孤立森林) │ │ (内容+用户+外部)│ │
│ └────────────┘ └─────────────┘ └──────────────┘ │
├──────────────────────────────────────────────────────────────┤
│ 模型层架构 │
│ ┌────────────┐ ┌─────────────┐ ┌──────────────┐ │
│ │ 时序模型 │ │ 非线性模型 │ │ 模型簇管理 │ │
│ │ (LSTM+ATT) │ │ (LightGBM) │ │ (按视频类别) │ │
│ └────────────┘ └─────────────┘ └──────────────┘ │
├──────────────────────────────────────────────────────────────┤
│ 工程层优化 │
│ ┌────────────┐ ┌─────────────┐ ┌──────────────┐ │
│ │ 分布式训练 │ │ 实时更新 │ │ 模型轻量化 │ │
│ │ (Spark+Flink)│ │ (FTRL在线) │ │ (知识蒸馏) │ │
│ └────────────┘ └─────────────┘ └──────────────┘ │
└──────────────────────────────────────────────────────────────┘
↓
┌──────────────────┐ ┌─────────────────┐ ┌──────────────┐
│ 评估指标体系 │ │ 业务价值落地 │ │ 伦理合规 │
│ (MAE/RMSE) │ │ (降本/增效) │ │ (联邦学习) │
└──────────────────┘ └─────────────────┘ └──────────────┘
业务意义:衡量广告 / 推荐内容的吸引力,辅助内容创作者、平台运营者和广告投放者做出更科学的决策。
- ->金主:优化广告内容、发布时间,广告投入产出;
- ->流量平台:广告定价;资源分配;推荐内容排序
目标:点击率预测,评估广告有效性
- 将预测问题转化为 “用户是否点击” 的二分类问题,输出 0(不点击)或 1(点击)。
- 优先选分类模型:若业务目标是排序(如推荐、广告),且数据标签为 0/1 点击标记,分类模型更高效。
- 考虑回归模型:若需精确的点击率数值(如预算规划),或数据标签为点击频率(如 10 次曝光中 3 次点击),回归模型更合适。
准确性:
- 短期预测(未来 1-24 小时):MAE(平均绝对误差)控制在实际点击量的 10%-15% 以内,例如预测 10 万点击量的视频,误差不超过 1.5 万。
- 中长期预测(未来 7-30 天):MAE 控制在 20%-30%,侧重趋势判断(如 “爆款” 或 “冷门” 的方向预测)。
实时性: - 离线建模:每日全量更新模型的训练时间不超过 2 小时(处理亿级历史数据)。
- 在线预测:单视频点击量查询响应时间 < 50ms,支持百万级 QPS(每秒查询次数)。
业务价值: - 资源优化:通过点击量预测降低 CDN 带宽成本 10%-20%(避免过度扩容)。
- 变现提升:广告投放 ROI 提升 15%-25%(精准选择高点击视频)。
评估指标体系 - 核心指标:MAE、RMSE(均方根误差)、MAPE(平均绝对百分比误差)。
- 辅助指标:预测值与实际值的相关性系数(Pearson 系数 > 0.8)、分位数误差(如 90% 的视频预测误差 < 20%)。
华为 https://github.com/reczoo/FuxiCTR
简介:广告行业中那些趣事系列52:一个超好用的CTR开源项目FuxiCTR | 数据拾光者 | 2022年04月11日 09:00:导读:本篇从理论到实践介绍了华为CTR开源项目FuxiCTR。首先是背景介绍,然后重点详解开源项目FuxiCTR,最后分别简单介绍了传统CTR模型发展进程和深度学习CTR模型发展进程。对CTR模型感兴趣小伙伴可以一起沟通交流。
使用:配置数据集(特征处理)和模型(训练、评估)
- 模型效果也需结合业务场景、特征工程质量及在线 A/B 测试结果综合评估
模型:
集成学习框架:“时序模型+特征工程模型” √
- 时序部分:点击量存在强时序规律(如每日 / 每周的流量高峰),但传统线性模型无法捕捉复杂周期(如每月 15 日发工资后的流量波动)。
- 解决:用 LSTM+Attention 或 Transformer 模型,通过位置编码捕捉点击量的时间周期性(如日/周/月波动),结合傅里叶变换分解周期成分。
- 深度学习模型:自动学习高阶特征交互(如 DeepFM、xDeepFM);
- 注意力机制:动态关注重要的特征组合(如 AutoInt、DIN);
- 特征部分:点击量与特征间可能存在非线性关系,(如 “视频时长> 10 分钟” 时点击量先增后减),且特征交互复杂(如 “美女标签 + 搞笑内容” 的点击量增益高于单独标签),冗余或冲突。
- 解决:用 XGBoost/LightGBM 等树模型,通过梯度提升,根据特征重要性排序筛选关键特征,通过特征交叉(如 “热点标签 + 周末”)捕捉非线性和特征交叉(如视频标签、发布时间、创作者粉丝量),或用 DeepFM 等深度学习模型自动学习交叉特征。
- 集成方式:加权融合两者输出,权重通过交叉验证确定。
模型优化与评估:
- 模型融合:为提升预测精度,可将多个弱监督模型组合成一个强监督模型,如采用Bagging、Boosting或Stacking等集成学习方法。以Stacking为例,先使用多个不同的基础模型(如LR、GBDT、LightGBM)进行预测,再将这些基础模型的预测结果作为新特征,输入到另一个模型(如逻辑回归)中进行二次训练。
- 超参数调优:运用网格搜索、随机搜索、贝叶斯优化等方法,寻找模型的最优超参数组合,提升模型性能。例如,使用贝叶斯优化算法,通过建立目标函数的概率模型,迭代地寻找最优超参数。
- 评估指标选择:采用准确率、召回率、F1值、AUC(曲线下面积)、对数损失等指标评估模型性能。AUC用于衡量模型对正负样本的区分能力,对数损失用于评估模型预测概率的准确性 。
数据预处理:
- 数据清洗:采用异常值检测方法(如孤立森林算法)识别并处理异常数据,依据业务逻辑和数据分布特征填补缺失值,例如用均值、中位数或模型预测值填充。
- 归一化:借助最大最小归一化方法,将数据映射到0-1范围,消除量纲影响。
- 标准化:对特征分布进行变换,使其满足正态分布等特定分布,助力模型收敛。
- 非线性变换:运用如平方、开根号、对数等变换,提升特征的非线性表达能力。
特征工程:生成视频发布后的时间间隔、近7天平均观看次数等时序特征;对类别型特征(如视频标签、作者ID)进行独热编码、Label Encoding或Embedding编码;通过特征交叉(如“视频标签”与“发布时间”交叉)创造新特征,增强模型对复杂关系的学习能力。
| 编码方式 | 核心思想 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 独热编码 | 离散类别 -> 二进制向量 | 简单直观:无需训练,直接映射类别到向量。 正交性:向量间相互独立(内积为 0),避免模型误判类别间的顺序关系。 |
维度灾难:词汇表规模 语义缺失:无法表达词语间的语义关联(如"apple"与"fruit"的关系)。 |
小类别数、离散标签 |
| 标签编码 | 用连续整数表示类别(如0,1,2) | 维度低 | 引入顺序假设、语义无关 | 决策树等不敏感模型 |
| 词嵌入 | 低维稠密向量表示语义关联 | 捕捉语义关系、维度可控 | 需大量数据训练 | NLP、文本分类 |
| 二进制编码 | 用二进制位组合表示类别(如3类→2位) | 维度低于独热编码 | 引入位间依赖、语义解释难 | 类别数较多且无语义关系 |
多源特征融合:
分类特征(离散值):需根据类别数量选择One-Hot或Embedding处理。
- 稠密分类特征(类别数少,通常<100):One-Hot编码(直接展开为0/1向量)。
- 如用户性别=男/女/其他(3类),编码为
[1,0,0]/[0,1,0]/[0,0,1]; - 设备类型=手机/平板/电脑(3类);
- 视频标签粗分类=热点/教程/娱乐(3类)
- 如用户性别=男/女/其他(3类),编码为
- 稀疏分类特征(类别数多,通常>1000):Embedding降维(映射为低维稠密向量);
- 广告组ID,通过Item2Vec训练为128维向量,广告组A的Embedding为
[0.2, -0.5, 0.1, ...])。 - 视频标签关键词:假设关键词库有10万词,通过Word2Vec训练为64维向量(如“热点”的Embedding为
[0.3, 0.1, -0.4, ...])。 - 用户地域(城市):假设覆盖1000个城市,通过Embedding降为32维向量(如“北京”的Embedding为
[0.7, 0.2, -0.1, ...])。
连续值特征(数值型):需分桶或归一化处理。观看次数、点赞数、评论数、分享数,完播率,视频时长
- 广告组ID,通过Item2Vec训练为128维向量,广告组A的Embedding为
- 分桶:按数值区间分桶(离散化),增强模型鲁棒性。
- 视频时长(秒):分桶为
[0-5, 6-30, 30+],转化为类别特征,短视频,中视频,长视频。增强模型迁移性 - 价格(元):分桶为
[0-100, 100-500, 500+],避免连续值过拟合。 - 硬离散化:启发式规则,将连续值强行划分到某个固定桶中(如年龄 20 岁属于 [10,25] 桶),仅使用该桶对应的一个 embedding 向量;
- 软离散化:而 Key - Value Memory,Key 是预设的桶索引(或概念桶的标识),Value 是每个桶对应的 embedding 向量,不再局限于单一桶,而是通过权重向量让连续值同时 “关联” 多个 embedding 向量,实现 “软划分”。 例如:年龄 20.5 岁,可能以 0.7 的权重关联 [10,25] 桶的 embedding,以 0.3 的权重关联 [26,35] 桶的 embedding,最终向量是两者的加权和,更贴近特征真实分布。推荐系统(十) 「知识梳理」CTR模型中连续特征加入方法 | 缄默笔记 | 2022年03月13日 09:00
- 视频时长(秒):分桶为
- 归一化后输入:标准化消除量纲(
(x-mean)/std)或归一化符合特定分布均衡((x-min)/(max-min))。- 用户互动率:点赞数/观看次数(范围0-1,直接使用)。
- 视频完播率:完播用户数/总观看用户数(范围0-1,直接使用)。
- 封面图视觉特征(通过CNN提取):1. 降维:通过 PCA、全连接层等方法将高维特征映射到低维空间(如 2048→128 维),保留主要视觉信息。2. 归一化:标准化特征值(如减去均值、除以标准差),确保各维度权重均衡,避免模型偏向某一特征。
序列特征(时序行为序列):需Embedding后聚合。 - 用户历史行为序列:元素Embedding后求和/平均/加权聚合。
- 用户历史点击广告序列:如
[广告组A, 广告组B, 广告组C],每个广告组Embedding后求和(假设Embedding维度128,求和后为128维向量)。 - 用户观看视频标签序列:如
[热点, 娱乐, 热点],每个标签Embedding后平均(假设Embedding维度64,平均后为64维向量)。
- 用户历史点击广告序列:如
- 内容关联序列:元素Embedding后结合时序权重聚合。
- 视频相关推荐序列:如
[视频X, 视频Y, 视频Z],每个视频通过CNN提取特征后,按点击时间加权求和(最近点击的视频权重更高)。
时序特征(时间相关衍生特征):捕捉周期性或趋势
- 视频相关推荐序列:如
- 时间点特征:
- 发布时间:分解为为时间维度离散特征如“周几”(1-7)、“小时”(0-23)、“是否周末”(0/1)。
- 当前日期:分解为“当年第几天”(1-365)、“当月第几天”(1-31)、“是否节假日”(0/1)。
- 时间序列统计特征,时间序列统计特征
- 历史点击量滑动平均:过去7天点击量的平均值(如
(点击量1+点击量2+...+点击量7)/7)。 - 点击量增长率:过去7天点击量较前7天的增长率
(当前7天均值-前7天均值)/前7天均值。 - 周期性偏移:工作日与周末的点击量差异(如周末点击量均值-工作日点击量均值)。
交叉特征(组合特征):不同特征交叉组合,捕捉特征间的交互关系
- 历史点击量滑动平均:过去7天点击量的平均值(如
- 分类×分类:One-Hot交叉或Embedding点积。
- 用户性别×广告组类别:如“男性+科技类广告组”,编码为One-Hot组合或Embedding点积。
- 地域×视频标签:如“北京+热点视频”,通过FM模型自动学习交叉权重。
- 分类×连续:分桶后交叉或直接组合。
- 设备类型×视频时长:如“手机+长视频(>300秒)”,分桶后交叉为新类别。
- 广告组类别×价格分桶:如“高端广告组+高价商品(>500元)”,增强稀疏特征表达。
- 类别:用户性别:男/女/其他三类。类别数目比较少,这类属于稠密特征,稠密特征一般通过one-hot编码处理。广告ad所属的广告组特征类别数目非常大,通常达到几十万种,这类属于稀疏特征,embedding(如 Word2Vec、Item2Vec)将高维稀疏向量转化成低维稠密向量。
- 用户特征:观看用户的地域、设备类型、历史互动行为(点赞/分享率)。
- 内容特征:视频时长、标签关键词(如“热点”“教程”)、封面图视觉特征(通过CNN提取)。
准确性要求:
迁移学习与领域适配:
- 跨场景迁移:若缺乏某类视频的历史点击数据,可从相似领域迁移知识,例如:用电影预告片点击数据预训练模型,再微调至短视频场景。
- 领域适配技术:使用对抗训练(Domain Adversarial Training)减少不同视频类型间的分布差异,提升模型泛化能力。
冷启动问题(新视频预测)
- 解决方案:
- 基于内容相似性:找到相似历史视频的点击模式,迁移预测(如“科技类新视频”参考同类旧视频的初期点击曲线)。
- 多任务学习:联合训练点击量预测与视频分类任务,通过分类信息弥补新视频的时序数据缺失。
实时性要求:
大量数据实时流式处理:日均处理亿级视频的点击日志(如 YouTube 每日新增视频超 500 万条)处理;热门视频的点击量可能在短时间内激增(如 1 小时内从 1 万增至 10 万),需实时更新预测。
- 模型,“在线学习+增量更新”:使用在线学习 FTRL(Follow-The-Regularized-Leader)算法,支持实时接收新点击数据并增量更新参数,适合点击量实时波动场景。
- 框架:结合Flink/Kafka流处理引擎,结合特征分桶(如按视频类别分桶处理)提升并行效率,实现分钟级数据更新和模型迭代。
- 优势:快速响应突发流量(如热点事件导致点击量激增),避免重新训练全量数据的延迟。
实时预测与缓存策略:
- 分层预测架构:
- 粗粒度预测:先预测未来24小时点击量区间(如10万-20万),用于流量预估。
- 细粒度预测:临近时间点(如未来1小时)再精细化预测,减少计算开销。
- 缓存机制:对热门视频的预测结果缓存至Redis,响应时间从秒级降至毫秒级,支持百万级QPS查询。
可用性要求:
部署成本与效果平衡
- 模型部署:将训练好的模型部署到生产环境中,可以使用TensorFlow Serving、PyTorch Serving等工具进行模型的部署和服务化。这些工具提供了高效的模型推理接口,支持多模型管理和硬件加速。
- A/B测试驱动: 先在小流量场景验证模型迭代效果(如提升5%预测准确率的同时,计算资源增加不超过10%),再全量部署。
- 前提:开发基线模型(如逻辑回归);迭代优化模型(如换用神经网络),每次仅改变一个变量(如学习率、特征); 用于验证效果
- 离线与在线结合: 夜间用全量数据离线训练高精度模型,白天用在线学习保持模型实时性,降低GPU资源成本。
监控与自动调优
- 模型健康度监控:
- 实时监测预测误差(如MAE,预测准确率、召回率、F1值,超过阈值时触发警报)。
- 分析特征漂移(如某类标签视频点击量突然下降,提示数据分布变化)。
- 监控与维护:建立模型监控体系,实时监测模型的,当指标出现异常波动时及时报警并进行模型更新。定期收集新数据,重新训练模型,以适应数据分布的变化。
- 自动超参数调优:使用Ray Tune/AutoML工具,基于历史性能数据自动搜索最优参数(如LSTM层数、学习率衰减策略),减少人工调优成本。
- 并行训练:利用分布式计算加速大规模训练(如 Parameter Server)。
大规模并发与资源优化
- 模型轻量化: 使用知识蒸馏(如Teacher-Student架构),将复杂模型(如Transformer)压缩为轻量级模型(如MobileNet+LSTM),减少参数量,部署至边缘服务器。
- 量化技术+剪枝:将模型参数从32位浮点数转为8位整数,减少内存占用和计算量。
- 分布式推理:
采用TensorFlow Serving/KFServing分布式部署,通过负载均衡将预测请求分发至多台服务器,支持万级并发。
业务与伦理难点
用户行为博弈:
- 创作者可能通过 “标题党”“诱导点击” 等方式干扰点击量规律,导致模型预测偏差。
- 解决方案:引入反作弊特征(如跳出率、完播率),区分 “有效点击” 与 “无效点击”。
隐私与数据合规:
- 用户地域、设备等特征可能涉及隐私,需在合规前提下使用(如欧盟 GDPR 要求)。
- 解决方案:采用联邦学习(Federated Learning),在各设备本地训练模型,仅上传加密后的特征参数。
五、总结
工业级视频点击量预测需从“模型精度、工程效率、成本控制”三维度设计方案:
- 模型层:集成时序与非时序模型,结合迁移学习解决冷启动。
- 工程层:通过流处理、分布式推理、模型轻量化支持大规模实时预测。
- 运营层:依赖自动化监控与A/B测试持续优化,平衡效果与资源成本。
最终目标是在保证预测准确率的前提下,实现系统的高可用性和可扩展性。
搜索
搜索算法
TF-IDF
简单实用
TF-IDF 算法是基础,用于信息检索 Information Retrieval,文本挖掘 Text Mining,自然语言处理 Natural Language Processing。
目前也有深度学习为基础的文本表达和算分 Weightin。
TF-IDF 来自 向量空间模型 Vector Space Model,把查询关键词和文档表达成向量,用向量运算表达向量间关系,如计算相关度,用余弦相似性 Cosine Similarity、点积 Dot Product 这样的一个值来表达,可以从线性代数或几何的角度解释计算合理性。
词汇表/单词表Vocabulary 的长度就是关键词和文档的向量维度,可以用1表达单个词的出现,0表达未出现,这是给维度赋值 Weighting 的最简单方法。
更复杂的赋值方法,TF Term Frequency,单词频率,计算关键词中某个单词在文档中出现的次数。TF的假设是,关键词的单词比其他单词更重要,文档的重要程度(相关度)与单词在文档中出现的次数成正比。
问题是,一些连接词 如 The,An,常出现但相关度不大。则用 IDF Inverse Document Frequency,逆文档频率=1/DF,惩罚 Penalize 出现在太多文档中的单词,DF值越大越不重要。
用 TF · IDF (点积)表达某个查询单词在一个文档中的重要性,叫做相关度打分Scoring。
算法变种
- 虽然文档含关键词的次数表达了相关度,但这样的关系很难说是线性的,次数超过阈值,则相关性不大。则引入 log,对数函数,对 TF 进行变换,这是一个不让TF 进行线性增长的技巧。如用 1+log(TF) 代替 TF,既保存相关性的区分度,又不至于线性增长
- 考虑到长文档和短文档,对TF进行标准化 Normalization,消除计量单位引起的差别,特别是对文档的最大TF值进行标准化
- IDF 同样要考虑到非线性增长和标准化。
- 同样,关键字和文档也要标准化,使得向量不受文档长度影响。标准化后的点积 = 余弦相似度。当向量
和 被标准化为单位向量 和 后,它们的长度均为 1。此时点积为: ,可以直接用余弦相似度运算代替点积。 - 点积,同时考虑两个向量在长度和方向上的相似性/相关性,结果是一个数值。
- 区别于叉积(
),仅用于三维向量,结果是法向量,垂直于两个向量构成的平面
- 区别于叉积(
- 余弦相似度,只考虑两个向量在方向上的相似性。
- 点积,同时考虑两个向量在长度和方向上的相似性/相关性,结果是一个数值。
TF/IDF(Term Frequency-Inverse Document Frequency)即词频 - 逆文档频率,是一种用于信息检索和文本挖掘的统计方法,用于评估一个词在文档或文档集合中的重要性,由词频(TF)和逆文档频率(IDF)两部分组成,相关公式如下:
词频(TF,Term Frequency):表示一个词语在文档中出现的频率,计算公式为:
其中,
有时也会使用简化版本:
逆文档频率(IDF,Inverse Document Frequency):衡量一个词在整个文档集合中的稀有程度 ,计算公式为:
其中,
TF - IDF值:将词频(TF)和逆文档频率(IDF)相乘,得到TF - IDF值,计算公式为:
TF - IDF值越高,说明该词在特定文档中出现频繁,同时在其他文档中较少出现,也就越有可能是该文档的关键词 。
举个例子,假设有文档集合
- 词频
(苹果, ) = = 0.1 - 逆文档频率
(苹果, ) = ,通过计算约为 0.95 (这里以自然对数为例 ) - TF - IDF值
(苹果, , ) = 0.1×0.95 = 0.095
辨别:score=y, weight, x
线性模型(如线性回归、逻辑回归)的核心公式:
- 符号定义
-
特征矩阵
: 个样本,每个样本有 个特征,维度为 。 -
权重向量
: 个特征对应的权重,维度为 。 $ -
偏置项
:可并入权重向量(通过在 中添加全1列)。
- 预测值计算
对于所有样本,预测值( 向量)可表示为:
展开形式:
常见应用场景
(1)加权平均分
- 场景:课程最终成绩由作业(30%)、期中考试(30%)、期末考试(40%)组成。
- 权重:作业0.3、期中0.3、期末0.4(权重之和为1)。
- 分数:作业85分、期中90分、期末95分。
- 计算:
(2)推荐系统 - 场景:商品推荐综合考虑用户评分(50%)、销量(30%)、价格(20%)。
- 权重:评分0.5、销量0.3、价格0.2。
- 分数:商品A(评分8.5、销量1000、价格100元)。
- 计算:
。分数是消除计量单位差异,做的标准化/简单归一。
(3)机器学习 - 场景:神经网络中,输入层到隐藏层的连接权重决定信号传递强度。
- 权重:模型训练自动学习的参数(如
)。 - 分数:输入特征值(如
)。 - 计算:
,其中 是激活函数。
BM25
经验公式,工业系统常用
信息检索领域发明的排序算法。BM=Best Match
非监督学习排序算法的典型代表,文档与一个查询关键词的相关性是不知道的,算法本身无法从数据中学到相关性,而是根据某种经验法则猜测相关文档的特质,所以,BM25 是一个经验公式,每个参数经过迭代逐步发现。
- 单词和目标文档的相关性:基本思想是词频TF,BM25 挖掘出了词频和相关性的关系是非线性的,每个词对于相关性的分数不会超过阈值,阈值与文档有关。因此,词频标准化,目标是某个单词对最终分数的贡献有阈值。标准化方法是词频/(词频+权重),这个做法在非监督学习中很普遍;权重包含2个重要信息1. 当前文档长度2. 所有文档平均长度
- 单词和查询关键词的相关性
- 单词的权重 1. IDF变形。IDF用对数函数log对词频进行变换。2. RSJ值,是更复杂的IDF,需要一个监督信息,验证文档对某个查询关键词的相关性。
三者乘积组成某个单词的分数。某个文档相对于查询关键词的分数=查询关键词中所有单词分数和
算法变种
- BM25F,Field,域,可以理解成一个文档的多个方面,如标题、摘要和正文。BM25F 要结合相关的域,将文档相关性统一到一个分数上。方法是一个文档看作是各个域的加权平均,每个域分别计算词频进行标准化,加权平均作为文档,文档x权重就是分数值
- BM25 结合其他信息,如BM25和PageRank 线性组合,BM25是查询关键词相关的信息,PageRank是一个网页的总体权重
语言模型
容易解释,自由扩展
希望用概率模型描述查询关键词和目标文档间的关系。最基础的是模型是查询关键字似然检索模型 Query Likelihood Retrieval Model。
语言模型:一个针对词汇表的概率分布。则查询关键字是从一个语言模型抽样Sample 得到一个样本(关键词抽样假设),从而产生一个随机过程。
- 是一个离散分布模型,产生式模型,针对某个词库,在某种语境下,产生下一个单词。即更改词库,变成离散数据。
设概率分布参数已知,则对一个查询关键字打分,就变成在这个概率分布下,一组事件的联合概率。现实中,因为联合概率小,则通过一个对数变换,把概率乘积,变成概率对数的加和。
要求语言模型参数,先确定语言模型的形态,常见选择是类别分布函数,即多项分布 Multinomial Distribution去除排列组合信息。
在类别分布假设下,认为单词间相互独立。则定义1w个单词的类别分布就有1w个参数。每个参数对应单词出现的概率。不过参数未知。需估计参数,最直接的参数估计法叫最大似然估计。在类别分布的假设下,最大似然估计的最优参数解,恰好有解析形式,即如果有数据,可以得到唯一最优的解。
每个文档对应一个类型分布,每个类别分布都可以从自己这个文档中求出所有的参数。
变种
- 最大似然估计的平滑。结合全数据集平滑和狄氏平滑,或者先把文档分成一些聚类,如不同话题,然后根据类别进行平滑
- 语言模型本身的定义。语言模型的关键词抽样假设,没有明确说明关键词和目标文档间的关系,即没有定义相关性。改进是认为有两个模型,查询关键字从一个分布中产生,目标文档从另一个分布中产生,这两个分布的距离,就是相关性的定义。在这样的结构下,文档和查询关键字形成一种对称的局面,相关性可以根据距离得到定义。
机器学习排序
用机器学习提升检索的性能水平。于是产生了机器学习排序算法。
单点法
排序问题转机器学习问题。特别是监督学习。之前的算法都是无监督学习,即不知道关键词与哪些文档相关,是一个猜测相关性的过程,于是用算法对 关键词-文档 打分,希望分数反映相关性。但这种排序算法不是最优的,特别是相关信息存在时,应该可以直接用相关信息帮助算法提升准确度。
构建训练集
- 要训练排序算法成为监督学习,先看需要什么样的数据集。建模对象是关键词-文档,则每个训练样本至少包含关键字-文档信息。针对这个训练样本,可以用相关度定义样本标签。
- 简化下,标签定义为,文档与某个关键字相关,即二分标签,训练排序算法,转成二分分类问题,可以直接用二分分类器训练排序算法。如对数几率分类器或者支持向量机。
- 说这样的方法叫单点排序学习,是因为每个训练样本,值是某一关键字和文档的有关无关标识,它们间是否相关,完全不取决于其他文档。也不取决于其他关键字。没有关联的看待问题,是对现实的极大简化,但对于训练排序算法是一个好的起点。
构建测试集,重点看算法好坏的评估 - 测试集与训练集是同一个数据源,但是两者互斥。
- 对于二分分类问题,评价指标 1. 精度 Precision,在所有分类器已经判断是相关文档中,有多少是真正相关的 2. 召回 recall,真正相关文档,有多少被提取了出来
- 因为是排序问题,有TOPK问题,所以,精度和召回都受到K的约束。实际上,K值往往很小,如,5,25;而被评分的文档数量很大,所以K是个至关重要的简化问题的方法。
-
- F1 值是平衡精度和召回两个指标的数值。很多情况下,精度和召回是互斥的一组指标,用F1平衡更方便
排序算法可以在训练集上,从五级相关度上训练多类分类器,在测试集上用NDCG指标评价排序。查询一个关键字,相关度不是二分类,而是进行相关程度打分,最相关 相关 不确定 不相关 最不相关,一共五级定义,使用多类分类评价,把五级相关度当作5种标签,来看分类器的分类准确度。当然,这种评价不适合排序。五种相关类型对应的数据量不同。但某个排序算法可以把最不相关的文档分类正确,但可能错失了所有的最相关文档,分类是准确的,但没有价值。多数时候,最相关数量少,不相关数量多,会得出不恰当的结果。解决,NDCG Normalized Discounted Cumulative Gain,不是一个分类准确度评价指标,而是排序的精度指标,设排序结果里,相关信息比不相关的排序高。任何排序一旦偏离这样的结果,就会受到扣分(惩罚)。
配对法
单点排序法与我们需要的结果有差距,这个差距不是算法好坏决定的,而是算法要优化的目标,即单个数据点是否相关,和一组结果的NDCG排序最优间的结构化区别。对于一个查询关键字来说,最重要的不是针对某一文档相关性估计的准确,而是一组文档间的相对关系估计的准确。
配对法基本思路是,对于一个查询关键字,有一个完美的排序关系,推导出两个文档的相对关系,从相对关系中学习,得知如何对其他关键字排序。
于是,训练集的样本,不是关键字-文档,而是关键字-文档-文档。如有三个文档A B C,完美排序是B>C>A,希望通过学习两两关系,B>C C>A B>A ,来重构B>C>A
假设是
- 可以针对关键字得到完美排序关系。可以通过五级相关标签,或是点击率获得。但完美关系不是永远∃的,电商中,关键字“哈利波特”,有的希望是书,有的希望是有哈利波特图案的衣服,这就不是一个完美排序
- 希望学习两两文档的配对关系来重构完美排序。但可能,两两关系是独立的,特别是预测时,模型能正确判断两两关系 B>C C>A ,但不代表能得到B>A。即我们不能保证能得到最优排序
- 构建的样本,可以描述两两相对的比较关系。可以简单认为,文件间的两两关系来自文档特征 Feature 间的差异。将差异值作为新的特征,从而学习到差值到相关性差异的关系。
注意,在测试集预测时,会有计算复杂度问题,因为,原则上,必须对所有两两关系都进行预测,现实中,基于线性特征差值构造样本,则测试可以回归到测试复杂度的情况。其他方法则有问题。计算提速或逼近算法为两两比较排序提供了可能。
列表法
基本思路是
- 尝试直接优化像NDCG这样的指标,学习到最佳排序效果。目的简单,用什么做衡量标准,就优化什么目标。但指标在数学形式上是非连续,不可微分的。多数优化算法基于连续微分,解决:
- 近似 NDCG的指标。SoftRank,AppRank
- 尝试从数学形式上写出 NDCG的边界,优化边界。有 SVM-MAP,SVM-NDCG
- 涉及复杂的优化算法,以优化 NDCG 指标。有 AdaRank,ListMLE。
- 根据一个已经知道的最优排序,尝试重建这个顺序,衡量中间差异。AdaRank,ListMLE。
- 在纯列表法和配对法间寻中间解。找 NDCG替代,直接优化列表想法,退化成优化某种配对。有LambdaRank,LambdaMART。原理是,一个排序算法是否达到最优,简单讲,是看当前排序,相比于最优,哪些两两关系搞错。学习最优问题,转成减少两两排错问题。这不需要真正的目标函数形状,仅需要某种形式的梯度。受此启发,大多数的优化过程,目标函数仅是为了推导梯度存在。如果直接得到梯度,就不需要目标函数。实验证明,把NDCG通过梯度变化差异x梯度,达到增强效果的目的。早期的LambdaRank用神经网络进行模型训练,而LambdaMART用决策树,效果非常好,成为很多类似方法的标配。
列表法是比较理想的排序学习方法,因为列表法尝试统一排序学习的测试指标和学习指标。工业界,基于配对法和列表法的混合方法更受欢迎。因为列表法复杂度高。
RANKSVM:排序支持向量机
- 把向量机用到序列数据中,试图对数据间的顺序直接进行排序
- 支持向量机,在二分类 Binary Classification 问题中,线性支持向量机希望找到一个超平面 Hyperplane,把正例和负例分割开。在很多可能的超平面中,支持向量机尝试找到距离两部分数据点边界最远的那个。因此,支持向量机也称为边界最大化 large margin 分类器。如果不是线性可分,支持向量机借助 核技巧 kernel trick,把输入特性特过非线性变换到线性可分
- 要把支持向量机用到排序场景,需改变问题设置。设每个数据点由特性 X 和 标签 Y 组成,X代表当前文档信息、文档与查询关键字相关度和查询关键字等文档和查询关键字属性的信息。Y是一个代表相关度的整数,通常>1。针对不同的X,需要学习到一个模型能准确的预测出Y的顺序,即如果两个数据点 X1,X2,对应Y1=3,Y2=5,因为Y1<Y2,合理的排序模型,需要把X1,X2通过同种变换,使得 X1<X2,这个变换,就是排序支持向量机需要学到的模型。即在线性假设下,排序支持向量机要学习到一组线性系数W,使得X1·W<X1·W(点积),当然,不仅是对X1,X2,也需要对所有点和顺序建模,即模型W需要让数据集上的所有点的顺序关系都预测准确。这个定义使非常严格的,可能找不出解。因此,允许一定误差,使得 W 可以准确预测所有数据间的顺序,并且W确定的超平面,使两边数据边界最大化,这就是线性排序向量机。实际的建模对象是数据对的差值 Pair,因此, 向量机的理论可以直接用到这个特征向量空间
- 难点:复杂度是
,N是数据点的数量,因为需要对所有的数据对进行建模。如果由百万文档,需要降低复杂度,使用解决结构化向量机 Structural SVM的一种算法,CP算法 Cutting-plane。这个算法保持一个工作集合 Working Set,存放当前循环时违反的约束条件,在下一轮中优化约束条件。始于空集合,每轮优化基于当前工作集合的支持向量机子问题,直到所有约束条件误差<一个全局的参数误差。这是一个线性复杂度
GBDT Gradient Boosted Decision Tree 梯度增强决策树
- 增强算法 boosting,将弱机器学习转成强机器学习,代表算法是 AdaBoost 。初始训练集训练出一个基学习器,根据基学习器的表现对训练样本分布进行调整。使得基学习器做错的训练样本在后续受到更多关注(降低偏差),基于调整后的样本分布训练下一个基学习器。直到基学习器数目达到阈值,将所有的基学习器求加权和(加性模型)。实际效果上,增强算法能基于泛化性能弱的学习器,构建出强的集成结果。
- AdaBoost 可以从统计视角解释,是基于加性模型 Additive Model,以类似牛顿迭代法,优化指数损失函数 Loss Function。由此,提出了梯度增强,可用于搜索和新闻推荐。梯度增强增强算法的扩展,希望弱学习器达到强学习器效果,逼近目标变量的值,即标签值,取得加权和。权重,从统计学和优化理论的视角,用梯度下降 Gradient Descent 来优化一个目标函数,每轮梯度的值和 “学习速度 Learning Rate”参数叠加形成最后的预测效果。这个观察非常明显,每个梯度的值可以认为是一个弱学习器,学习速率可以看作权重。
- 因此,增强算法是一个迭代算法,每轮迭代,把当前所有学习器的加权平均结果当作这轮的函数值,求针对某个损失函数对于当前所有学习器参数的一个梯度。用弱学习算法,可以是线性回归模型 Linear Regression,对数几率模型 Logistic Regression 来拟合梯度。最后用 线查找 Line Search 的方式找到权重。即用一些简单模型,拟合不同迭代轮数的梯度。
- 特点是,梯度下降带来的,每轮迭代一定是去拟合,比上轮小的一个梯度。函数对目标的整体拟合是越来越好的。
- 梯度增强决策树是用决策树,当作弱学习器,去拟合增强过程中的梯度。每轮迭代,都拟合一个新的决策树,用来表达当前梯度,然后跟前面的决策树进行叠加。而决策树的形状如层数,节点个数,都是可以学习的超参数。决策树的个数,即迭代轮数,是最重要的参数,避免过拟合。在搜索中,损失函数的设定,用配对法排序,不直接拟合相关度,而是拟合两个不同文档相关度的差值,即相关度高的文档在前。
- 梯度增强决策树,是一种普适的机器学习排序算法。核心想法是增强算法+多个决策树堆积,这个想法是在机器学习中被反复验证,有效的方法
LambdaMART
- RankNet,不能直接优化搜索的评价指标。是一个和排序向量机非常类似的配对法排序模型。尝试正确学习每组两两文档的顺序。两两文档的顺序,由损失函数 Loss Function 引导模型学习到正确的两两关系。设有两两关系的标签,即某个文档比另一个文档更加相关的信息,更加,表达了次序关系,可以是二元的,如+1是更相关,-1是更不相关。我们希望,不管什么模型,希望输出和标签信息匹配,相关度更高,则预测值更高。可以用二元分类器处理,RANKNET 用 对数几率模型 来处理二元关系。最小化损失函数用到的模型,是神经网络,对文档间的相关度建模
- 但文档的两两相对关系,和搜索评价指标不直接相关。搜索评价指标,如NDCG或 MAP,直接建立在对某一查询关键字相关文档的序列上,至少是TOPK序列。RankNet 不保证在 NDCG 指标上有好的效果,因为没有优化这些指标,可能相关度高的文档,没有排在前面的损失,>
- RankNet 的梯度下降算法,要解出损失函数针对模型参数的梯度,可以是两部分的乘积。第一部分是损失函数针对模型输出值,第二部分是模型输出值针对模型参数。第一部分和损失函数的定义有关,第二部分和具体的模型有关。同时,损失梯度不一定是给函数,只要能指引函数方向。所以,损失梯度变成 Lambda,是两个文档 NDCG 的变化量,实际上是变化量×之前对数几率带来的梯度。而学习器改成 梯度增强决策树 GBDT,优化时先考虑改进 NDCG方向,再二分类。
查询关键字理解
用户行为背后的目的。这是很强的指导因素。也是个性化搜索结果重要的原因。
分类
自动化分类,定义更精细的用户意图。
查询关键字的目的,用户日志和调查问卷证明这点。
- 导航 Navigational 26%:特征,对应唯一少量的标准答案,信息集成网站也是可以接受的答案。
- 信息 Informational 50%:目标不仅是找到权威性质的网页,还包括列举权威信息的节点网页
- 交易 Transactional 24%:到达中间站点,进一步完成交易。主要对象是购物。
查询关键字分类的价值:1. 不能依靠用户汇报自己关键字的用途 2. 亿万用户输入的关键字,不可能人工标注 3. 希望更细粒度的用户意图
把查询关键字分类转成监督学习任务。每个查询关键字是一个数据样本,响应变量是对应的类别。具体情况取决于任务,是把认为类别独立还是可以同时存在。
简单假设下,关键字分类是一个多类分类问题。可以用 支持向量机 SVM,随机森林 Random Forest及神经网络 Neural Networks解决。
大多数监督学习任务,最重要的组成是选取特征,有效的特征有: - 查询关键字:含人名或公司名,则分类更可能是信息。关键字和类别有直接的关系。
- 搜索引擎返回的,查询关键字相关的页面:页面信息和类别有直接的关系。
- 用户的行为信息,用户输入查询关键字后会点击什么网站,在哪些网站停留。用网站作为查询关键字代表的信息靠谱
实际上,查询关键字分类很难,每天1/3的查询关键字之前没出现过,也有长尾的低频关键字
解析
分割:如“White House Opening”,可以分割成“White House”,“Opening”
关系到搜索结果的质量。标准的搜索引擎,根据查询关键字提取倒排索引 Inverted Index,数量从百到千。有了文档,用较复杂的排序算法,如基于机器学习的排序学习模型,对文档重排序 re-rank
- 尝试从查询关键字中产生N元语法,即从一组此词中产生连续的子词语。通过这些N元语法,在一个大语料中出现的词频(Google发布的语料),来判断分割有意义。当然,直接用词频可能偏好短的单词,有2种矫正词频的方法 1. 矫正词频(内部) 2. 基于维基百科(外部)。目的都是让长词频的打分,有机会高于短单词。
- 短语互信息 Mutual Information。互信息计算两个随机事件的相关程度。在这里,是计算两个查询关键字每两个相邻短语的互信息。值>预设阈值,则可以认为相邻两个单词组成了短语。互信息计算需要知道某个单词出现的概率,可以从微软发布的一个N元语法获得。
- 条件随机场 Conditional Random Field,对输出的复杂标签进行建模
查询关键字标注Annotation:分析查询关键字,获取其属性信息,如“White House Opening”,“White House”是一个建筑物名字或地理位置名字,“Opening”是一个名词,暗指“开门时间”。
标准信息帮助搜索结果,取决于用户的搜索场景。如“苹果”,可能是一种水果,也可能是一个公司,搜索结果差距大
标注方法: - PRF Pseudo-Relevance Feedback,难点在于查询关键字信息太少,需要用大量辅助信息进行标注。
- 条件随机场,一个序列建模工具,预测标签是“手机苹果”还是“水果苹果”这样的组合输出结果。
扩展
希望不仅理解关键字,也能补充用户输入信息,为用户提供扩展选项,因为用户输入信息不足,丰富查询效果。这是精度和召回recall 的平衡。
召回:查询相关的信息
同义词
- 结合查询关键字与查询结果(用户行为),需要大量用户交互数据。需要对用户的搜索行为数据进行大规模挖掘。设有两个搜索关键字A B,A的结果中,用户点击了一些网页;B的结果中,用户点击了另外的网页。如果A B的网页间相似,则认为A B是同义的查询关键字。可以把查询关键字和网页分别表示成图 Graph 中的两类节点 Node,每个关键字节点和多个网页节点建立联系Edge,象征这些网页对应关键字的相关页面,从每个网页的角度看,多个关键字节点和同一个网页节点相连,则这些关键字和同一个网页相关。寻找同义词的工作,变成在图上进行相似节点,特别是相似关键字节点的挖掘。如果把查询关键字的节点放在一边,网页节点放在另一边,就是典型的二分图 Bipartite Graph,特点是同边的节点间没有连接,如关键字间没有连接,所有的连接发生在不同边的节点间,如关键字和网页间。二分图聚类 Clustering 是机器学习的经典问题,如用二分图随机游走及随机游走产生的到达时间,来挖掘相似关键字
- 海量文本中分析出词语间的相关度,可以通过维基百科等外在语料进行学习。思路是为每个词组建一个表达 Representation,通过表达找到同义词。流行做法是为单词找到数值表达,即嵌入 Enbedding,如果两个词在嵌入空间,通常是欧式空间中距离相近,则认为两个词是同义词。为词组产生嵌入向量,通用算法是 WordsVec,目标是通过一个文档的每句话某个词周围的词来预测词出现的概率,如苹果手机帮助文档中,version 6,7 的备份帮助文档相似,因此,通过周围上下文信息对单词的嵌入向量进行学习,可以有效学到单词的语义,通过语义,能找到其他同义词
缩写
搜索系统评价
if you can't measure it, you can't improve it.
指标
线下评测
设你开发了一个新软件,怎么知道用户是不是喜欢,是不是愿意掏钱?核心是了解用户喜好。最直接的方法是询问用户。最好形成一组数据帮助系统反复迭代,减少人工成本。
早期为了比较多个系统,先构造一个线下的测试数据集,以对系统进行改进提升。数据集特点是
- 有一个几十到上百的查询关键字集合,对关键字的选取来自经验和召回。
- 测试数据集有几百到几千不等的文档。文档的一部分,是查询关键字的相关文档。
测试数据集不是用户与产品交互产生的真实回馈结果,所以,这个测试数据集叫线下评测数据。
好处是,关键字和文档和系统本身无关,可以在不同版本中重复使用。需要强调,在讨论查询关键字和文档相关性时,对所有用户适用,即与用户无关。
基于二元相关度的评测指标
针对某个查询关键字,整个测试集中的文档,有一个标签,相关 不相互。
二元相关度上的指标,是很多其他重要指标的基石,如精度 Precision,提取的文档中,多少是相关的,即 (提取+相关)/提取;召回 recall,相关文档中,提取出了多少,即 (提取+相关)/相关。这里的假设是,提取的文档数< 所有文档数。精度和召回指标不能评价排序系统,即无法确定提取出的文档在最后排序中的位置。
基于多程度相关原理的评测
折扣化的累计获得 discounted cumulative gain,设倒序排序,位置1是最高排序
- 一个排序整体相关度,是这个排序各位置上相关度的某种加权。避免指标对排序的不敏感。
- 每个位置上的获得 Gain,和这个文档原本定义的相关度相关,但要根据不同的位置,打不同的折扣=文档相关度/log(位置),位置下降,折扣变大,即DCG鼓励文档尽可能排到序列顶部。
- 直接用 DCG 会有问题,如果两个查询关键字返回文档数不一致,则直接比较两个查询关键字的DCG值是不公平的,可以进行归一化处理 Normalized DCG,对某个查询关键字的排序,根据相关信息,计算一组“理想排序”对应的DCG值,理想排序多按相关信息,从大到小排序。nDCG=当前算法排序产生的DCG值/理想的DCG值
- 比较两个不同的排序。均值与假设检验,如两个样本的配对T检验。可能的问题是,假设检验得出的结论,只是统计意义上的好坏,和系统在用户面前的表现有差距
在线表现
检验用户和系统的互动。是建立因果联系 Casual Relationship 的重要工具,基于统计的假设检验。
划分应用人群,一半是平均划分,50%控制组,50%对照组,区别是系统不同。设一个搜索系统,需改进的部分是实验设置的变量,叫独立变量 Independent Variable。评测的指标,特别是用户指标如网站点击率、搜索数据,叫依赖变量 Dependent Variable。希望在独立变量和依赖变量间通过假设检验建立关系。
- 人群划分不均匀。可能控制组有更多的女性用户,对照组有更多的北京用户,需要通过算法,控制这些变量,使得分布均匀。但十几种变量时,如年龄、性别、地域、收入层级,难度大
- 独立变量设立难度大。应用中有很多服务 子系统 页面 模块,分属于不同的工程团队,如果每部分都做自己的实验,很难保证用户间的可比性。有效的进行在线实验,包括实验设计、评测等,是非常前沿的研究课题。
用因果推论分析实验结果。不能实验的前提下,通过线上数据,训练模型,得出期望结果,即模拟在线实验,是因果推论的价值。因为线上数据有误差,因果推论是机器学习的一个工具,希望无偏差的训练和评测模型。
文档理解
从文档中抽取特性,帮助检索算法找到更相关的文档
首要:分类
把分类看成机器学习任务,则常见分类有
- 二元分类,文档分为2个类别
- 多类分类:判断文档属于多个类别中的某个
- 多类-单标签-硬分类:文档只有一个标签
- 多类-多标签-硬分类:文档∈多个类别,分类唯一确定
- 多类-软分类:文档以概率∈不同类别
- 层次分类,类别看作组织结构,一个文档属于组织中的所有类别节点。一般来说,上层节点更抽象
特性
文字
- 词袋模型 Bag of word,用文档上的文字,不考虑(打乱)文字顺序,每个词的权重可以用TF-IDF或语言模型加权。
- N元语法,保留部分词序。缺失是极大增加特性空间,每个N元组被观测到的次数明显减少,引起数据稀疏问题Sparsity
- 递归神经网络 RNN,对序列建模
文档排版 - 有些字段有明显的特征,比如标题很重要,有些段落结构,对文章的主要内容有很大的指导意义,所以,对文档的不同域建模
- 针对网页,要用浏览器最终呈现的视觉效果提取特性
- 针对孤立文档,信息有限。互联网上的文档链接会为网页提供额外信息。因为噪声存在,也需要找周围文档有价值的信息
算法
- 二分类,则用对数几率回归,支持向量机,朴素贝叶斯分类等监督学习模型。多分类,改动上述模型也可以做到
- 不是所有的分类算法支持“概率的输出结果”,如支持向量机,应用中,用 Platt Scaling 调整,把支持向量机的输出结果当作新特性,学习一个对数几率回归
- 用周围文档的关系学习 Relational Learning,用文档间的关系提高文档分类效果,即假设相似页面有相似分类,效果好。
- 层次分类中,相似的页面,可以是文字信息相似,也可能是文档间组成的图相似,如公司子页面内容差异大,但都代表公司信息,因此,文档分类时会放在一起
关键:聚类
文档聚类是非监督学习的典型代表。分扁平聚类,类外无关;层次聚类,类外有结构关系。硬聚类是文档明确的分到一组类中;软聚类是,学到文档分配到一组聚类的分布,即分配以概率存在。
聚类关系不是事先定义的,并且不容易衡量聚类结果的好坏
应用
- 帮文档提取或排序。聚类是因为相似,则或许可以满足用户的相同需求。在语言模型或其他概率模型中,预测文档相关度,需要从相似文档群体中找额外信息。
- 帮助整理搜索结果。聚类更反映文档潜在的本质关系,而不是分类这样先入为主的定义。
- 帮助研究人员浏览一个文档集合,不需要太多预先假设。很容易根据层次关系来分析文档,发现问题,进行下一步有效步骤
模型 - 扁平聚类,用K均值算法1. 文档表示成特征向量 Feature Vector,用词袋模型,N元语法或RNN 2. 聚类,K均值的基本思路,
- 目标函数仅表达最终的聚类最佳时的一种分配情况,没有描述如何得到最佳聚类的分配。直接最小化这一目标函数不容易,找到它的最优解是一个NP难的问题,用贪心算法找近似解,1. 初始化均值向量,随机选择点做聚类均值。2. 依次聚类样本点,将其分到最近的聚类中,聚类结束后更新均值向量(聚类中心),直到聚类结果不再发生显著变化,或达到预设的迭代次数阈值
难点 - 衡量聚类好坏,评价聚类算法,比较不同的算法,是个问题
- 聚类算法中,聚类个数非常难决定。
特例:多模文档分类
文档有多种模式 model 的表达路径,不同模式间共同描述一个文档的不同方面。如文字和图片。难点,,不同模式的数据有不同特征,有效用各自特性,最优的反映到某一任务。
建模的核心思路是数据表征,两个不同的神经网络学习隐含单元 Hidden Unit 来表达图片和文字信息。
- 连接不同的特征向量,得到联合表征 Joint Representation
- 表征独立,通过关系维持表征联系
假设是,虽然呈现不同,但都是对核心内容的表述,即数据的内在表达是相近的。相近依靠相似函数表述,如余弦相似函数
混合思路是,从文字和图片的原始数据中学到一个统一的联合表征,认为联合表征发展出了各自表征。
输入不一定是从数据中学习到,可以是从其他数据集中训练好的文字嵌入向量表达。
将联合表征当作整个文档的特征,学习分类器进行分类任务,文档、图片有各自的分类器。第三个分类器,将前面两个的分类结果作为新的特征进行分类。
多模数据的其他任务
- 图片转文字,生产准确文字来描述图片;或相反。也涉及语音。翻译基础上,进一步是对接 Align 文字和图片,如一组图片,根据图片变化,生成图片描述信息
- 可视化问答 Visual Question Answering,图片和文字一起回答问题。需同时对图片、文字信息建模
- 这些问题都是用深度学习的序列模型 Sequential Modeling,特别是RNN,LSTM模型
搜索框架
大型搜索框架
基于文本匹配的信息检索系统,特点是
- 文本匹配系统的基础是倒排索引 Inverted Index,索引中的key是查询关键字,values是查询关键字的文档列表编号。文档按重要(相关)程度倒序排序,因此,不是包含关键字的文档都会在倒排索引中。
- 索引过大,需要编码压缩;当超过内存,需要在内存和硬盘上切换。因此,索引的快速查询是非常重要的课题。
- 检索方法,如 TF-IDF,BM25及变种。建立查询关键字和索引的联系,使得搜索引擎能给<关键字,文档>赋予一个数值,数值用于排序。
- 缺点是,它是经验算法,无法适应现有数据;也缺乏理论基础;不能处理多模数据,如文字、图像、图信息;
- 优势:不依靠机器学习,不需要数据和调优
基于机器学习的信息检索系统。特点是
- 理论支持。如单点法 pointwise,配对法 parewise 和列表法 listwise 排序。使用通用机器学出现语言来描述搜索问题,有明确的目标函数、特性 feature、算法求解这些框架下的机器学习问题。机器学习的基本方法,训练数据、测试数据、评测方法可以用到信息检索场景。对搜索性能和系统研发有指导意义。机器学习的发展可以用在搜索框架,便利的提升搜索效果
- 容易用多模数据。多类数据可以通过特性表达,通过学习特性间的联系,预测相关度,是机器学习的强项。因此,多是理解搜索系统各部分数据并用在排序算法中,如查询关键字分类、解析,文档理解的分类产生的特性,是提高相关度建模的重要工具。
- 缺点是,机器学习不一定在实际中获得满意效果。机器学习需要大量可靠数据,对整个系统有较高要求。机器学习中可能有特性、模型、数据异常,需要在生产中对这些情况有个估计。
进一步
- 强化深度学习用于思考搜索问题
- 从用户的角度,抓住用户对系统的偏好,研究更有意义的评测方式
多轮打分系统
也叫多层搜索架构
机器学习模型,用于预测搜索关键字和文档间的相关性,理想状态下,针对每个关键字,需要对文档进行打分 Scoring。如果是互联网引擎,需要对十亿文档打分,这个数量级不现实。此外,通用机器模型,特别是便于排序的树模型 tree model,如 GBDT,神经网络,有较高的计算复杂度。想在实时响应(几百ms)对上万文档进行打分难度大。
因此,需要极值,对于每个查询关键字,先有一个方法在整个数据集上快速评价出百到千的文档,然后用模型计算和排序。这种需要对文档进行2轮打分的流程,叫两轮打分框架。
- 第一轮叫 TOPK 提取,将文档数据降到百到千。1. 倒排索引,通过索引提取文档,建立有效索引是达到目的的关键。2. 线性模型如 WAND 操作符提取文档,把模型简化为只有正系数的线性模型,整个模型可以看作是两个向量的点积。WAND是点积在索引上的一种优化。当然,除了线性模型,树模型用到索引处于研究阶段
- 第二轮用模型。第一轮是对不同机器上的单一文档打分,第二轮采用配对法或列表法对文档打分。
- 雅虎是三轮打分,第三轮根据上一轮的上下文特征 contextual feature,进一步提高抖索结果的质量。需要三轮打分的原因 1. 相关排序只是搜索系统的一个方面,还可能引入多元化或其他商业规则 2. 最后文档集合生成后,可以生成更精细的特性,提高排序的精度
多轮打分系统特点,1. 每轮用的文档数量比上轮少 2. 每轮用的特征数量和模型比上轮更复杂
搜索索引
用于查询关键字处理的场景。key,values
- values 按相关度倒序排序。
- 包含查询关键字的文档,不一定在values中
如果用户输入的查询关键字含多个词组,很容易得到包含所有关键字的文档集合,如在多个列表中做归并排序。倒排索引中,valuse除了存文档编号,
- 也可以存文档含查询关键字的次数,及词频这个特性。可用于对词频计算有很强依赖的算法,搜索算法如 TF-IDF,BM25,语言模型。
- 查询关键字在文档中出现的位置 position,这对于多个查询关键字非常重要,也可以帮搜索引擎生成结果摘要信息
索引技术
- 索引压缩。如差值编码,不直接记录文档编号,而是按文档编号的顺序,记录编号间的差值,适用于频繁查询的关键字,要求文档列表不按相关度排序,而按文档编号排序
- 索引略过 skipping,当有多个查询关键字,这些关键字间的频率有大的差距,而我们仅需要交集。则掠过几个大频率关键字的文档
查询关键字处理,从索引中提取相关文档并计算分数。一下两种思路演化出很多高级算法,如WAND操作符,能模拟线性模型 - 文档优先 document-at-a-time,找出查询关键字组合对应的文档,再针对取出的文档分别计算分数,放入TOPK
- 词优先 term-at-a-time,依次处理查询关键字组中的每个字,取出关键字1的所有文档计算出一个文档分数,再处理关键字2,更新分数作为最后分数。
经典图算法
PageRank
用图表达网页间的关系,计算网页重要性。
每个网页,有一个输出链接outlink A→B√/输入链接 inlink A√→B的集合,设每个页面A都有一个值,叫 pagerank,衡量页面的重要程度=输入链接B pagerank 值的加权和,则权重=1/输入链接B的输出链接个数,即B的pagerank/N 分给A。谁的输出链接多,谁分给A的就少。页面的pagerank 值之前是不知道的,则给予相同的初始值,根据定义更新pagerank值,直到所有页面的pagerank不再发生很大变化,通常比较少的迭代,pagerank值就能收敛。
改进:整个页面网络是一个完全联通的图,使得 pagerank 值由唯一收敛的解
- 一些页面没有输出链接,如pdf或图片,智能聚集上游输入链接传来的pagerank值,而不能把自己的pagerank值发出去,结果是一些页面悬空 dangling,使得pagerank值不能收敛。悬空节点的pagerank值增大,直到获取到其他所有输入链接的值。需要对悬空节点引流,认为这个节点能随机到达整个网络上的其他的一个节点。
- 一个页面有自然的输出链接,也需要一个机制,从这个页面跳转到其他任何一个页面,即模拟用户操作,从这个页面的输出链接继续浏览,确保pagerank的收敛性。因此每个页面把自己的pagerank值发给输出链接,也分享到所有页面,可以引入一个参数,控制比例,是顺着输出链接走,还是跳转到其他页面,取值范围大概是 60%~85%
pagerank 解释
- 分配等式写成矩阵。算法变成求解随机矩阵的左特征向量值的过程。随机矩阵就是经过两次修改后的跳转规律的矩阵形式,迭代方法就是求特征向量的乘幂法,在一定条件下的随机矩阵,经过乘幂法,能得到一个唯一解。
- 矩阵代数变形,把等式两边的各项,移到等式一边,则另一边是0,整个式子变成一个线性系统的求解过程。可以从代数角度解释求解。
HITS
网页的网格结构。权威节点 Authority,枢纽节点 Hub。
循环:很多枢纽节点的输出链接是好的权威节点,好的枢纽节点指向很多好的权威节点。
用数学的方法表达权威和枢纽节点,则必须为页面准备两个值,因为不能有一个页面完全是权威或枢纽。最直观的定义是,对于A的权威值B,B是A页面输入链接的枢纽值的和。如果A页面的输入链接的枢纽值大,说明B自身的权威性高,如果A经常能指向好的权威节点,则A的枢纽性也高。
求解权威值X和枢纽值Y,通过矩阵运算,转成求解特征向量。表达方式和 pagerank一样,虽然定义不一样。经过变形,两个算法都可以转成矩阵求解特征向量的问题。
- 定义邻接矩阵L(如果网页j链接到网页i,则Lij=1;否则Lij=0),X为所有页面的权威值向量;Y为枢纽值向量;L为邻接矩阵,行/列表达两个页面是否相连。
- 迭代更新
- 权威值X可以通过所有指向它的枢纽页面的加权和来更新:
- 枢纽值Y可以通过它所链接的所有权威页面的加权和来更新:Y=LX
- 权威值X可以通过所有指向它的枢纽页面的加权和来更新:
- 归一化处理,确保数值稳定,用L2范数归一化。
其中∣∣⋅∣∣2表示向量的L2范数。 - 转成特征向量
- 将Y=LX代入
得到: ,这表明X是矩阵 的一个特征向量。 - 同理,
表明Y是矩阵 的一个特征向量
- 将Y=LX代入
- 求主特征向量
- 对于X,我们需要找到矩阵
的主特征向量,即对应最大特征值的特征向量。 - 对于Y,我们需要找到矩阵
的主特征向量,即同样对应最大特征值的特征向量。
- 对于X,我们需要找到矩阵
- 总结
- 权威值X满足:AX=λX,其中
- 枢纽值Y满足:BY=μY,其中
- λ和μ分别是A和B的最大特征值,而X和Y则是对应的特征向量
- 权威值X满足:AX=λX,其中
图算法的一个重要分支就是把图表达成矩阵,通过主特征向量对图的一些特性进行分析。可以用乘幂法 power method。
HITS在搜索中的使用
- 根据查询关键字构建相邻图 Neighborhood Graph,图包含和这个查询关键字相关的页面,通过倒排索引很容易得到。
- 根据图,建立邻接矩阵,通过矩阵运算,得出权威值和枢纽值。根据这两组值,给用户展现2种网页的排序结果。
pagerank是查询关键字无关的算法,每个页面的 pagerank 值,不随查询关键字变化。HITS是查询关键字相关的算法
HITS特性
- 迭代计算值。HITS一定是收敛的,但不一定收敛到唯一一组<权威,枢纽>值,需要让HITS邻接矩阵种所有的节点能到达其他任何节点,只是概率比较小。
- 优势:提出新的视角,对于同一个查询关键字,权威和枢纽排序能帮助用户理解自己的需求。
- 缺点:依赖查询关键字,需要在响应时间内计算出结果。可以用全局的网页图,提前计算所有页面的权威值和枢纽值,但这样会失去都关键字的相关信息
社区检测算法:模块最大化
前面两者都希望赋予网页权重,表达网页重要性。
社区检测 Conmunity Detection,是一个网页分析工具,希望把网页代表的图分成小块的图,每个小聚类叫社区,希望从图上挖掘出一个潜在的社区结构。
模块最大化的社区检测算法
- 简化思想,一个网络分割成2个社区,逐一检查节点,看把这个点归到另一个社区的话,会不会增加模块化这个目标函数。直到社区赋值不再变化。
- 目标函数, 两个节点连接数量-这两个节点的期望连接数。模型最大化,就是希望社区中的节点差值和最大化,即两个节点连接数>它们之间连接数的期望值。
- 两个节点间的期望连接数,两个节点各自的总连接数相乘/整个网络总连接数* 2,用于衡量两个节点间出现连接的可能性。
- 整个模块最大化的目标函数是,针对现在网络的所有节点,根据是否在同一个社区,计算两两间的模块化数值,对所有两两配对加和。若知道社区的分配,即结束属于哪个社区,则可以计算目标函数最大化
- 社区分配和PageRank、HITS思路相似,用矩阵对模块最大化进行重构,经过代数变形后,新的目标函数=
/4* 网络连接总数,向量S代表一个节点是否属于两个社区中的一个。矩阵B中的某个元素表示 横纵坐标代表两个节点的模块化值。求解S的值。注意,S的值是离散的,要么是1,要么是-1,代表属于社区中的一个。这是一个困难的离散优化问题 - 简化离散优化问题,进行近似处理,允许S的值是实数。最优情况下,S是矩阵B最大特征值对应的特征向量,解得S后,根据S中的正负号,对网络节点进行划分
- 把二分法推到多个社区,就是网络不断二分,每次二分前,需要检查对模块化目标函数起到正向作用。
深度学习搜索
深度结构化语义
经典搜索模型,争取用某种表示 Representation 来表达查询关键字,用类似的表示来表达文档。通过匹配函数计算查询关键字和文档的距离,进行排序。
深度学习实现,前馈神经网络是最重要的改进
- 查询关键字和文档的表达:把查询关键字或文档定义为词向量 Term Vector,词向量可以时词袋。基于词向量,模型学习一个词哈希 Word Hashing,即把0/1的稀疏词向量,转成一个稠密 Dense 的词向量表达。这是深度学习 在自然语言处理的通用方法,降低输入的数据维度。用深度学习的重要经验,非线性转换 Non-Linear Projection,获取数据深层的语义信息,使用简单的前馈神经网络 FeedForward Neural Network,对输入向量进行多层的非线性转换,如双曲正切函数 tanh函数
- 匹配函数:计算两者距离,用余弦函数做距离函数
效果: - 因为模型仅用查询关键字和文档间的文字信息,则无法用机器学习排序算法,只能用文字性的经典排序算法,所以用的数据集不是通用的,而是Bing的搜索数据。
- 算法比较上,效果明显但不是特别惊人
卷积结构下的隐含语义
局部和分布表征下的搜索
推荐
应用:电商、新闻、音乐
简单模型
流行度
Popularity-based,推荐吸引用户的内容。
假设:物品好坏和流行度成正比。即好的东西,关注的人多,谈论多。
如果能判断一个物品在任何时间点上的流行度,按流行度排序物品就可以了。判断指标:
- 时间:周期性的访问,由流量体现。文章投放在早上和晚上会有较高的关注度。但文章质量存在时间误差
- 位置:不是地理位置,而是在网站的哪个位置显示物品。用户心理上对位置的感受会有偏差。
单位时间内点击的数目,购买的数目,点赞的数目,都会存在时间和位置的影响(偏差),而不只是物品本身属性。因此,不能用直接的数值对流行度建模。往往用比值 Radio,或是计算某种可能性,如点击率、购买率。
要进一步建立无偏差的数据,是一个课题,比较经济的方法是收集没有偏差的数据,把服务流量分成2部分,流行度+随机推荐,使用算法叫 Exploitation&Exploration中的 epsilon-Greedy。
从数学上对点击率建模,可以把一个物品在显示后是否被点击看成“伯努利随机变量”,对某段时间内点击率的估计,转成对伯努利分布参数的估计。参数估计方法可以是最大似然法 Maximum Likelihood Estimation,即把参数估计问题变成最大化的优化问题,希望参数取值可以最大限度解释当前数据。估计的数值是某个物品当前点击总数/被显示次数,缺点是,没有点击率的参数值为0,分子分母为0,无法体现物品的流行度。这是一个悲观的估计,因为你可以认为,不管在任何情况下,就算没有一次点击,出现的概率也不该绝对是0,这会导致过拟合或泛化能力差。
针对0的概率估计,用平滑Smoothing的技术,给0值非0的估计值,平滑是必要的,可以使估计不完全由点击决定,消减过分流行的概率。1. 简单的一个做法是通过整个数据集的频率做平滑。点击率的频率,是单一物品点击的平均频率和所有物品点击的平均频率的加权平均。这个权重可以动态调整。2. 借助贝叶斯统计推断,为类别概率加上一个先验分布,通常是狄氏分布,计算出点击率在先验分布和数据都存在情况下的后验概率。
流行度的推荐不是个性化的,面向全体用户。
相似信息
也叫 Neighborhood 临近模型,推荐相似的数据点。
假设是协同过滤 Collaborative Filtering,相似用户有相似喜好,相似物品被相似的人偏好。相似的用户互相过滤信息,在用户A数据不足时,借鉴用户B的数据。把用户A和用户B聚类在一起,可以对同一类型的用户建模。
问题抽象成,估计用户A,对没见过的物品a的偏好,如点击、购买或评分。
- 建立用户集合,这些用户已经接触过a,在其他行为上与用户A相似
- 基于用户集合,给物品a打分,用均值分数。均值改进
- 加权平均。和用户A越相似,权重越大
- 修正评分,去掉用户本人的偏差。一个用户对物品a的直接打分-这个用户对所有物品的平均打分。可能用户习惯性的对很多物品有很强的偏好
- 因此,打分算法分成2部分 1. 用户A的平均打分 2. 相似用户集中每个用户对于物品a修正评分的一个加权平均。
- 构建相似信息
- 定义用户相似。计算两个用户偏好物品的相关度,皮尔森相关度,对于同时偏好过的物品,用乘积展示相似,对所有的乘积结果加和,归一化
- 定义阈值,筛选相关用户集合,可以是100 或是200
- 加权平均中的权重。某个用户可能就偏好一两个物品,即数据少,但相关度高,这不可以过分相信。因此需要重新加权 re-weighting,可以用皮尔森相关度x系数,系数由偏好数量决定
相似用户的协同过滤,可以用为相似物品的协同过滤。与用户过去偏好相似的物品
协同过滤的推荐,可能受数据稀缺的影响。
内容
一种普遍方法,使用不同的推荐场景。用特征 Feature 表示用户、物品和两者间的交互,把推荐问题,转成监督学习任务。
- 把用户、物品的各种信号用特征表示。涉及复杂的特征工程,把不同信息通过特征表达出来
- 构建目标函数,描述当前场景
内容的主要特性
物品特性
- 文本信息,如商品名称和描述。可以用文本挖掘 text mining 的方式组成有效特征。如用 TF-IDF 形成文本向量。当然,噪声大,文本信息维度大时,需要用降维工具,如
- 传统,话题模型 topic model,对每个文字描述可以学到一个话题的分布,分布向量可以是100维,但一定比原始向量小
- 流行,词嵌入向量 word embedding,维持一个固定维度
- 物品类别信息。如新闻有娱乐、财经或时政。商品有电器、生活用品等。这类信息可以非常有效的抓住物品的整体属性。类别信息一般在数据输入时获取如通过合作渠道获取文章,类别往往是编辑加上去的。如果缺失,就需要机器学习,构造分类器。此外流行,用知识图谱 knowledge graph,用相关类型,推断(挖掘)物品类别信息。
- 图像或多媒体信息。多媒体信息是稠密 Dense 向量,需要先学习一个分类器,再组合其他特征的分类器。
用户特性 - 用户基本特性,如性别、年龄、地理位置。及衍生特征,如不同性别在文章点击率上的差异,不同年龄层在商品购买上的差异,不同地理位置对不同影视作品的喜好
- 用户画像 profiling,用户自己定义喜好,或不愿看到某类物品。其他情况通过隐反馈 implicit feedback 建模
目标函数:点击率、购买率;预测用户在某一物品上的停留时间
基于隐变量的模型
用户和物品的隐含结构。
设实际数据由隐藏变量构成,通过模型假设,知道隐变量的关系,但不知道取值。因此推断取值,根据取值预测和分析数据。
假设隐变量间或与显变量间,存在统计分布 distribution,最简单的模型是高斯混合模型,假设数据由多个不同的高斯分布产生,每个高斯分布有自己的均值和方差。对于每个数据点,我们就有一个隐含的变量,表达这个数据点属于哪个高斯分布。
学习的过程需要估计数据点的来源,及多个高斯分布的均值和方差。
矩阵分解
核心假设是,用隐向量表达用户和物品。显式的对用户和物品的隐含结构进行建模,用来表示评分、点积、购买关系。
推荐系统最常用的数据表达,就是用户和物品的交互,如评分,点击。对于每个用户,用一个向量表达对可能物品的评分,堆积所有用户的向量,就得到一个矩阵,行代表用户,列代表物品,每个元素代表一个用户对一个商品的评分。矩阵特点是稀疏,因为一个用户不可能对所有物品评分,多数的评分值是缺失。则补全 complete 矩阵,因此可以根据评分大到小,推荐给用户。
补全矩阵信息:设矩阵每个元素的产生过程如下:
- 每个用户和每个物品,对应一个隐变量 latent factor,设一个用户用100维向量表达,则100w个用户用100w个 100维的向量表达,物品同理,1万个物品用1w个100维的向量表达
- 设矩阵每个元素由用户和物品的隐向量点积(对应元素相乘相加)得到,则用户-物品评分矩阵=用户特征矩阵x物品特征矩阵=
,结果中的每一个元素 (i,j) 是通过将用户 i 的特征向量与物品 j 的特征向量 进行点积计算得出的。即矩阵中每个元素,来自2个隐向量的点积。因此名为矩阵分解,这是一种降维 Dimension Reduction 方式,每个用户和物品的隐向量都少于原有的物品数目,把一个大矩阵分解成2个小矩阵表达。
矩阵分解仅描述了模型表达,但没说怎么获得模型的核心内容,即用户和物品矩阵中每个元素的值。适用最小二乘法拟合,求解这些隐向量。
矩阵中每个元素,来自2个隐向量的点积,可用于构造目标函数,使得点积与我们观测到的矩阵数值相近,相近可以用平方差衡量,误差越小,则数据拟合的越好,隐向量能更好的表达用户和物品。
优化目标函数。因为计算未知数点积,因此目标函数无全局最优解,可以通过梯度下降找到局部解。
回归的矩阵分解
是矩阵分解基础上衍生出的模型,矩阵分解的问题:
- 矩阵仅对用户和物品的喜好进行编码 encode,对于一个复杂的工业系统,很多灵感或直觉,很难只用喜好捕获到,其他信号,无法融合到矩阵分解的模式中。
- 矩阵分解核心是学习用户的隐向量和物品的隐向量。只能通过训练学习到,但对于新用户或新物品的隐向量,因为不在训练集中,则无法学习到。如新闻网站推荐文章,每几天就会替换掉整个网站的文章,这就不适合矩阵分解
回归的矩阵分解
- 用显式的特性表达用户和物品。用户特性可以是年龄、性别、地区、已表达喜好的类别;物品特性可以是物品的种类、描述;
- 基于回归的矩阵分解假定,用户的隐向量,是从用户的显式特性变换来的。这种变换,就是回归模型。即建立显式特性与隐向量的回归模型,加大隐向量的约束 1. 受评分矩阵分解信息的约束 2. 受显式特性回归的约束
- 因此,虽然没有隐向量,但有显式特性,可以帮助得到隐向量。可用于新用户
- 从贝叶斯角度理解基于回归的矩阵:用户隐向量和物品隐向量看作两个随机变量。可以认为,两个随机变量有先验概率分布,只不过均值不是0,而是一个以回归函数结果为均值的高斯分布。回归函数由显式特性得到。即,我们认为显式特性的变换是隐向量的先验信息
基于回归的矩阵分解,即“层次的贝叶斯模型”,学习此模型的方式,都只学到局部最优解
- 简单方法,2阶段学。1. 针对已知的用户和物品,通过矩阵分解学习到隐向量。2. 学习显式特性到隐向量的线性回归
- 期望最大化,用一组随机参数决定回归的部分,学习到最佳隐向量,根据隐向量更新回归部分的参数。
分解机
是基于回归的隐变量模型的衍生,因简单易用,是主流的推荐模型。回归训练复杂,统一显式特性和隐向量的另一种方式就是分解机,结合基于内容的推荐和基于回归的隐变量模型。
分解机的输入是显式变量。不仅对显式变量建模,也对显式变量的两两关系进行建模。把两个特性的数值进行乘积,结果作为新特性,进一步处理新特性。原始特性两两配对,是构建模型的重要方法,特别对于非深度学习模型、自己做特征工程的模型。问题是,特性空间会急速增长。特别是∃类型特性,则两两配对后会产生大量的0,从而产生大的稀疏矩阵。
分解机的解决思路是,矩阵分解的降维思路。把稀疏矩阵分解后进行建模。假定所有特性都对应一个隐向量,两个显式特性的乘积,就是两个特性隐向量的点积。
可以用随机梯度下降求解。
高级
张量分解
Tensor Factorization,张量是对N维关系的建模。把上下文当作新维度,放进张量中建模。问题是求解难,不同的分解方法带来不同的建模选择。
在二元模式下,矩阵是表达用户和物品关系,最好的数据结构。矩阵分解绕开用户基于某个时空下的上下文影响。把这些信息放在隐变量中。张量是另一种方法,将上下文信息,融入到用户和物品的建模中。
张量分解的两种形式,如三维张量<用户、物品、时间>
- CP分解。candecomp/parafac,假设我们有一个三维张量
,其 CP 分解由三个因子矩阵组成: ,其中 是秩。 重构张量 可以表示为: 对于张量 中的元素 ,其计算公式为: ,R 是一个参数,可以理解成矩阵分解中隐变量的维度,决定了分解后每个因子矩阵的列数,也即是说 R 定义了模型复杂度和表达能力。因为分解出的R是一样的,因此减少了需要调整的参数个数 - HOSVD分解。high order singular value decomposition,分解出的三个矩阵维度不都是R,而是分别 A,B,C,这需要ABC 共同求得一个小张量。优势是给不同数据以不同的自由度,
设计目标函数或说定义损失函数,可以用原数值和预测值的平方差定义。
求解
- 简单模式,随机梯度下降,把张量分解问题看作一般的优化问题
- ALS alternating least square,优化每轮时,其他矩阵变量不动,单独优化一个变量
协同矩阵
Collective Matrix Factorization,有多少种二元关系,就用多少个矩阵分解去建模这些关系。
核心假设是,两个没有关系的矩阵,各自做矩阵分解,则分解出来的信息,没有任何关联。要想在两个矩阵分解间建立联系,必须假设两组用户的隐变量是一样的,即用户隐变量,在用户间,用户和物品间的关系中,是同一个隐变量在起作用。因此,虽然是2个矩阵分解,但限制了某部分参数的取值范围。优势是建立关联,减少总的变量数目,让关系相互影响。问题是,找到这样的隐变量难度高,且表达性差
学习,用随机梯度下降法。不过,每个隐变量存在于多个矩阵分解中,更新隐变量需要的计算量大。
优化复杂目标
基于流行度和相似度的系统,没有目标函数。
基于信息的推荐系统,是监督学习的应用,目标函数多是点击率或购买率,即二分分类的目标函数。
矩阵分解对用户和物品建模,多是评分。评分常用线性回归,或泊松分布(整数变量的建模好于线性回归)。
从效果看,用户对物品的评分,不是推荐系统需要优化的目标。真实场景更可能是,用户打开应用,浏览商品,翻阅,找到喜欢商品。和搜索结果的浏览相似,只不过推荐没有搜索关键词。因此,可以把用户喜欢的物品排到前面,把评分的预测,改成排序学习。虽然没有查询关键字,可以通过会话 session 来学习排序,对用户交互过的物品进行建模训练。因为反馈是隐性的,假设正交互信息的物品比其他物品更相关,有更高的预测值。正交互可以是点击、购买。可以用配对法训练,对于某个查询关键字,学习到每对文档间的关系,将两两关系预测正确,建立一个完整的排序结果。
Exploit 和 Explore
EE
利用,探索。用时间维度上看,当信息不足以决策,优化目标函数的两个决策方法
- 现在的最佳
- 未来的最佳
需要多次迭代才能找到好的方案。持续挖掘用户喜好。
UCB
EG epsilon-greedy,是最简单的EE算法。
P%的用户看到按估值如点击率排序的物品,(1-P)%的用户看到随机物品。随机性可能会导致用户体验下降,但随时间推移,整体上对所有物品的估计会更准确。是牺牲小部分用户体验换来大部分用户体验的思路。
UCB upper confidence bound,动态调整概率P。
物品点击率预测,可以根据物品显示记录预测,这个数值是一个估计的均值,准确度不高,即置信度不高。
衡量一个物品的置信度,可以用标准差 standard deviation,描述数据的离散程度,量化数据在均值周围的分布情况。标准差小说明信心大。
因此,若要动态调整物品显示的可能性,需要考虑物品的估计,也要考虑估计的置信度,用均值和标准差表达对一个物品的整体估计。根据估计来排序显示物品。不确定大的物品,可以显示到前面。经过多轮显示,物品数据越多,标准差越小,UCB会收敛到均值,置信度提高。
UCB的问题,是对物品打分的机制:均值+2* 标准差,对于没有显示过的物品,均值是0,或初始值默认,没有区分度。因此,UCB基于计算出的置信上限值进行选择,而不是完全随机决定下一个要探索的选项。更倾向于选择那些有可能提供更高奖励的选项(优化长期累积奖励),以提高学习效率,不能做到真正的随机探索。
汤普森采样
随机采样,涉及概率分布,计算机生成随机数。从一个概率分布中产生一个随机变量的样本。可以用均值估计。样本可以刻画一个概率分布。
不是所有的分布都容易抽样,能够抽样的,往往是标准的分布,如伯努利分布、高斯分布。
UCB算法的问题在于,参数确定的情况下,用户看到的内容是一样的,因此丧失了探索的机会。对于用户体验不好。
通过采样对物品进行排序,带来随机性。
汤普森采样
- 构建场景的概率分布,模拟应用。物品的点击,和抛硬币类似,可以用伯努利进行建模。汤普森从模型的后验分布中采样,借用贝叶斯的思路,在已有数据的情况下,结合先验概率,对参数进行估计。可以设置共轭先验 Conjugate Prior,这是 Beta 分布,
- 构建好后验分布后,进行从 Beta 分布中抽样,可以用通用数值计算库,如 MATLAB,Numpy。选用物品中参数值最大的。
- 每轮采样,这决定汤普森采样是随机的流程。
- 从后验概率分布中抽样,当样本数量够大,样本均值趋近分布均值,即如果一个物品点击率高,则后验概率的均值大。确保物品显示结果与估值相近。因用贝叶斯统计,则对当前点击率缺失时有优势。
- 因为是采样,即便参数相同,两个物品的采样数值可能不同。做到真正随机
评测
线下
流行把推荐系统模型,简化成对用户评分的估计,并对用户评分进行矩阵分解。
简单评测,是衡量评分的准确性。在机器学习中,经常用均方差 Mean Square Error,对所有差值的平方取均值。方差 Rooted Mean Square Error RMSE,就是均方差开根号。
RMSE 的问题是
- 用户误差会造成均值偏差,即差值大部分用来描述评分较多的用户,因此,RMSE小的模型,只是少部分高频用户的评分结果高,不代表整个推荐系统质量得到提高。
- 没有反应真实的应用场景。从大堆物品中,选出一个物品进行交互,而物品的单独评分就不重要。即便推荐系统能准确预测评分,也不能证明推荐系统在真实场景中表现优异
可以把搜索的一些指标移到推荐中。两个定义在二元相关度的指标,精度 Precision,召回 recall,是其他指标的重要基石。
搜索的相关度是人工标注,而推荐的相关度,可以是用户的反馈。点击某物品,则认为是相关的。用排序的思路评测推荐系统,是线下评测的标准指标。
线上
核心是在线可控实验,即 A/B实验。这是建立因果关系 Casual Relationship 的重要工具,基础是统计的假设检验。让改变是唯一的独立变量 Independent Variable。认定独立变量会导致系统性能的提高或降低。
需要提前确定要评测的指标,特别是用户指标,如网站的点击率,搜索的数量。这些指标叫依赖变量 Dependent Variable。希望在独立变量和依赖变量间。通过假设检验,建立联系。
设计有效的A/B实验,是非常前沿的研究课题。
评测指标
- 用户驻留时间
- 用户在相邻两次访问的间隔时间
无偏差
推荐系统的偏差。如新闻推荐系统,只推荐用户体育新闻,从不推荐财经新闻。会导致用户只看体育新闻。
进行矫正,假设是收集到的数据涵盖整个数据集。按用户的回馈概率,进行反比矫正。出现概率越大,样本权重越小。平均加权点击率=正样本/概率。
但不容易实现,新闻质量呈指数级下降。但做无偏差估计,需要随所有文章进行显示,这需要冒文章低质量的风险。这是热门的研究领域
架构
线下离线计算
要解决的问题。
- 在100ms内给用户提供推荐结果
- 当用户表达了不喜欢,需要对反馈基于处理,不再推荐
- 考虑用户群体的覆盖率。服务广阔的用户群体,支持新用户和新物品
线下,事先完成打分,当用户适用网站,只需要从存储中取得推荐结果。用空间换时间,解决第一个问题。
适用于简单场景和应用初期架构。
多层搜索
第一层,有一个索引,根据某些特性,如关键字,存储所有文档,方便随时检索。通过简单流程,如线性函数或布尔值函数,获取最相关成千上百的文档。
第二层,重排序,对上百个文档打分,适用较复杂函数,如基于决策树的模型或深度模型,得到最终结果。
第三层,针对不同的商业规则,如结果的多样性,进行处理。
因为,索引+数量少,所以可以快速响应,满足需求1
因为,重排序阶段,对用户反馈进行更新。1. 更新模型,如果是决策树,则重新训练决策树,因计算量大,所以不是好方案 2. 更新重排序模型中,某些特性的数值,满足需求2
因为,搜索架构天然支持新用户,索引不是用户信息,所以,以索引为基础的架构对于新老用户是一样的,只不过用户的特征值不同。因此,重排序对老用户的效果更好。缺点在于新物品,新物品不在索引中,就无法被提取出来,重建索引也不简单。
新用户多的思路:
多层搜索
- 快速抓住新用户和系统的交互信息。通过更新特性。在重排序阶段,因特性不同,导致排序结果不同。
- 没有足够信息时,如何为用户提供推荐结果。用户的其他信息,如年龄、性别、地域,每小时或每天更新一次,单独放在数据库中。用户访问时,可以搜索架构中取信息,也可以从数据库中取,继而进行重排序。
新物品多:
线下架构 - 新物品加入到内容池中,对于所有用户,重新生成推荐结果。耗时
- 当前生产的新物品,单独放在一个数据库中,给物品预估的分数。可以针对特性打分,或者随机分。推荐反馈结果和新物品结果
多层搜索 - 对新物品构建临时索引或数据库。从旧索引和临时索引中,共同获取结果,再进行重排序
如果新物品很多并且很快过时,如新闻,则不能重复推荐。而商品可以复购,可以重复推荐
深度学习推荐模型
受限波兹曼机 RBM
RBM 是一层隐单元 Hidden Unit 和一层显单元 Visible Unit 组成的神经网络结构。显单元和隐单元联通,并且自身有一个权重 Weight,连接也有一个权重。这些权重是需要通过训练学习到的未知参数。RBM 可以针对高斯信号即实数信息,伯努利或二项分布信号即离散信息,进行建模。3个显单元,5个隐单元,则权重个数=自身权重个数+连接权重个数=(3+5)+3* 5=23
以用户为电影打分为例。1个用户用1个 RBM 进行建模,仅对曾打分过的数据建模。
通过隐单元,连接多个用户的RBM。假设每个用户的隐单元不一样,则可以学习到用户的偏好。如果两个用户对同一个电影打分,则两个RBM共享同一个权重。
每个显单元,是用户对某个电影的评价。是一个K维的数组,只有1个元素是1,其他是0,即用二元的数组表达,对“用户K种可能的输出”建模。
在这个模型中,需要学习的参数有:显单元的权重,隐单元的权重,及两者连接的权重。同一个电影的权重共享。
学习,无法用最大似然估计或梯度下降,提出用 CD Contrastive Devergence 对比散度方法,对RBM采样。这是简化的MCMC方法
基于 RNN
Recurrent Neural Network,递归神经网络,对时序信息建模,如在一个会话中的推荐。
常见,用户对电影的爱好,随时间变化。
输入一个物品,RNN 输出对下一个物品的预测。RNN为了在时间序列上建模,会维持一个隐含的状态序列。
在矩阵分解中,设隐向量随时间变化。则可以用 LSTM Long Short-Term Memory的 RNN 模型。
总结来说,RNN,对输入和输出变量,在时间上的关系,进行建模。同时用内部隐状态序列,对输入输出变量进行建模。
深度学习扩展推荐系统
深度学习始于计算机视觉,能在众多信息中,学习到高维度的特性 Feature。
矩阵分解中,隐变量是从数据中提取的特征信息,这种提取是一种线性变换。而深度学习模型,是多层次的非线性变换。
用多层神经网络提取特征
输入用户ID,物品ID。可以认为,ID是高维的离散输入。对用户和物品建立多层神经网络。层数至少是1,把离散输入,转成连续的数据层,这层叫做嵌入层 Embedding。希望连续信息携带语义 Semantic上的相似,即如果用户相似或物品相似,则希望嵌入层在数值上相近,则嵌入层很好的捕获到相似度。
连接用户和物品的嵌入层,形成一个大的嵌入层,作为输入,进行多层的神经网络变换。最后输出对评分的预测。
自动编码器 AutoEncoder,希望无监督化的学习到某信号编码后的信息,再通过解码还原最初的信号。如果能找到这样的完美过程,则在假设中,我们获取了更有价值的特征信息。用于推荐系统,主要是对用户和物品进行编码。
CNN 卷积神经网络,提取用户和物品信息。通常是在嵌入层后,不用多层神经网络,而是用CNN对信息进行变换。
效果不差,但没有更好。
自然语言和文本处理
LDA
文本挖掘中,一项任务就是,分析和挖掘出文本中隐含的结构信息,而不依赖提前标注的信息,是典型的无监督学习。LDA Latent Dirichlet Allocation,开启了主题模型。用于分析文档数据,如新闻、医药、考古文献、政府公文。其模型变种,被用到图像、音频、混合信息、推荐系统、文档检索等
LDA 属于 产生式模型 Generative Model。产生式模型,相对于判别式模型 Discriminative Model 而言。
设需要建模的数据有特征信息X,及标签信息Y。判别式只对Y的产生过程 Generative Progress 进行描述,用于分类器和回归分析。产生式对X,Y同时建模,用于无标签的数据分析,如聚类。因为产生式学习X标签,因此,模型更难识别。
产生式希望通过一个产生过程帮助理解模型。产生过程是描述一个联合概率分布 Joint Distribution的分解过程。这是一个虚拟过程,是模型的一个假设,一种描述,真实数据往往不是这样产生的。任何一个产生过程在数学上都等价于一个联合概率分布。
LDA的产生过程,描述文档、文档中文字的生成过程。
- 文档长度N,不影响模型,可去除
- 主题矩阵上,可放置全局的狄氏分布作为先验概率分布,参数是β。同时,文档主题分布的先验,也是狄氏分布,参数是α。先验概率分布,使得LDA的参数个数不随文档数目而增加。
- LDA 没有一个文档统一的聚类标签,而是每个字有一个聚类标签(主题)。
最重要的未知变量是每个单词对应的主题下标,这是从每个文档对应的主题分布中采样获得。每个文档的主题分布本身是一个未知的多项式分布,用来表达当前文档所属主题。未知的多项式分布从全局的狄氏分布产生。狄氏分布起到超参数作用,参数取值多是未知的。可以根据经验值进行设置。除了每个文档的主题分布和主题下标,也需要对全局的语言模型进行估计,这些语言模型直接决定了各类词语出现的概率。
LDA 模型训练与结果
训练:学习属于贝叶斯推理,只有MCMC为主的吉布斯Gibbs采样 和 VI 变分推理 Variational Distribution 可以解决。VI 选取一组简单的、可以优化的变分分布来逼近模型的后验概率分布。分布的选取,可能给模型带来误差,但把贝叶斯推理转成了优化问题。VI 更新 θ 和z值时,可用它们最新值更新α值。整个流程叫 变分最大期望 Variational EM 算法。
- 两种方法的初始形态都无法应对大型数据
- Gibbs采样,1. 主要对主题下标进行采样,开始是随机结果,慢慢收敛到参数后验概率的真值。这个迭代过程慢,可能要百到千次。只能一个文档一个文档的单独处理,所有数据结构都要在采样过程中改。2. Gibbs采样的核心是对一个离散分布进行采样,离散分布采样在分布参数变化的情况下,最好达到 KlogK,K是主题数目。
- 优化1:将Gibbs采样分解成几部分:全局的语言模型、文档、当前需要采样的单词。每部分的数据变化率不一样。可以减少重复操作,如全局的语言模型,在每个文档中的采样过程不变,这部分不需要每个单词都重算。文档,可以在每个单词的采样过程中只算一次,不需要每个主题算一次。提升效果不明显
- 优化2:将采样公式,拆分成与当前文档有关,与当前文档无关的语言模型部分。提出 Alias 方法,加速采样。针对一个分布反复采样,就可以建立一种数据结构,使采样在第一次计算时有计算成本,以后都是O(1)的成本。
- VI,把对隐含参数的估计问题,变成确定性的优化问题,可以用优化算法解决贝叶斯推断的问题。问题是,因为方法不能解决原来的优化问题,因此,新的优化可能不能获取原优化的解。也只能一个文档一个文档的单独处理。
- 优化:借用优化场景的思想,特别是基于梯度 Gradient 的优化方法,大数据需要SGD Stochastic Gradient Descent 随机梯度下降,即在计算梯度时,不需要处理完所有数据才计算一次梯度,而是针对每个文档,都可以计算一次梯度的估计值。
结果验证:提出用困惑度 Perplexity 这个评估值,来衡量文档建模的有效程度。值越低越好。
扩展
LDA只对文档的文字信息建模。用额外信息,是LDA扩展的重要工作。
额外信息,影响主题分布,进而影响文档字句的选择。是概率图模型的基本思路,把变量放到产生式模型的上游,使得下游受到影响。
- 作者信息,如科学或新闻文档,希望借用作者写文档时的遣词造句,分析作者的写作信息。作者 LDA,1个作者有一个主题分布。一篇文档有多个作者,用吉布斯采样的方法学习,采样到单词,可能看到不同作者对同一文档的贡献。
也可以把额外信息放在主题下游,希望通过主题变量施加影响。 - 用LDA到多模态 Multiple Model,对不同数据进行建模。基本思路是,设数据通过主题分布产生。一旦知道数据涵盖的主题,就可以生产出和数据点相关的信息,包括文字、图像、影音。
把文档放在时间尺度,希望分析和了解文档在时间轴上的变化 - 从主题分布入手,因为主题分布控制了什么文字会被产生出来。因此,可以认为主题分布随时间变化。不同时间的先验分布不同,引用状态空间 state space模型来表达,把不同时间点的狄氏分布的参数串起来,使得分布的参数会随时间变化。
基础文本分析
隐语义分析
看似没有头绪的文字中,隐含什么规律呢?能不能提取出更有用的结构性内容?
Latent Semantic Indexing,这是文本分布的基础模型。从文本中提取特性,这些特性对原来文本的深层关系又更好的解释,是无监督学习。用矩阵分解对“词-文档矩阵” Term-Document Matrix 进行分解。假设是,“词-文档矩阵” 是一个稀疏矩阵。从大量数据看,文字服从幂定律 Power Law Distribution,大多数单词只出现少的次数。少数的单词会出现在很多文档中,可以理解成28法则。
对于稀疏矩阵,假设矩阵不能真正表示数据内部信息,即矩阵中有个结构。这个假设,就是矩阵分解中的低维假设 Low-rank Approximation,核心是用少的维度表达原来的稀疏矩阵。
N个单词,M个文档的矩阵=单词矩阵NK x 文档矩阵KM,K是一个参数。单词矩阵可以把某语境下的单词聚拢,可以定义成一个主题。基于矩阵分解的隐语义分析是最早的主题模型。文档矩阵描述不同文档在K个主题下的强度。
流行的隐语义模型,基于奇异值分解 Singular Value Decomposition,SVD分解。核心思想就是分解出的主题矩阵。
优势:直接用代数计算,对文本进行分析。
劣势:分解出的矩阵是实数,有±,限制我们用这些数做一些含义的推断,无法很好的解释结果
概率隐语义分析
Probabilistic Latent Semantic Indexing PLSA。对文档和其单词的联合分布,类似隐语义分析模型中的文档和单词的矩阵,进行建模。不过,PLSA 不是对数据直接建模,而认为数据是从某个分布中产生的结果。
对联合分布的建模方式
- 直接建模,可能数据不足,或无法找到一个合适的已知参数分布来描述需要建模的联合分布。
- 简化联合分布,用分解。
- 假定一些隐含的变量,数据从隐含变量中产生。假设先从文档出发,产生需要的主题,继而产生单词。主题是我们不知道的隐含变量,需要从数据中估计出。
- 等价的模型描述。设有一个主题的先验概率,根据这个主题的分布,产生一个文档和文档中的单词。类似主题模型的下游方法,文档变量和单词变量都是主题中的下游变量。
- 经过代数变形,上面两种方法是等价的。
从第一种方法上看,是给每个单词,联系了一个未知的主题变量,主题变量从一个文档级别的主题分布中得出,这是一个多项分布。根据主题变量,从语言模型中,抽取单词,这也是一个多项分布。因此,PLSA 和 LDA相似。从模型根本特征看,PLSA 和 LDA 都是对文档单词分布的一种分解,或者产生解释。不过 LDA 对两个多项分布都加了先验分布,使模型更符合贝叶斯统计。
EM算法
PLSA 和 LDA 都依赖一个算法,期望最大化 Expectation Maximization,EM,这是针对隐参数模型 Latent Variable Model最直接有效的训练法之一。
EM算法基于统计参数方法,最大似然估计 Maximum Likelihood Estimation,MLE。多数机器学习都可以表达成某种概率模型的MLE求解。
MLE 构造:通过概率模型写出当前数据的似然表达,即在当前模型参数值的情况下,看整个数据出现的可能性。可能性越大,表示参数越好的解释当前数据。因此,MLE就是找到一组参数的取值,使其更好的解释现在的数据。
针对模型写出MLE,就是个公式,找出公式最大值下的参数取值。问题转成优化问题。可以针对参数求导,令公式函数=0,求解参数值。
简单模型,如用高斯分布建模,可以求出似然表达式,通过求最优函数解的方式,得到最佳参数表达。最优的参数正好是样本均值和方差。其他模型不能得到解析解 Closed Form Solution,也无法优化MLE表达式,适用EM算法,简化MLE求解。
EM算法核心,通过代数变形,为每个数据点的似然公式找到一个新的概率分布,这个概率分布通过隐含变量达到。隐含变量可积分,用以恢复原始的MLE公式。问题是,MLE中,对数函数 log 在积分符号外面,因而无法操作整个式子。EM 要把 log 放在积分符号里面,杨森不等式表达,函数的期望值>=先对函数变量求期望再作用于函数。于是,求积分,可以看作对某一函数求期望值。这个函数,正好是模型的似然表达。用杨森不等式,可以求出是隐含变量MLE式的下限。
有了下限公式,可以用MLE的流程。对两组未知数,模型参数和模型隐含变量,分别求导,得到最优表达。
对模型隐含变量的概率分布求解后,最优隐含变量的概率分布=隐含变量基于数据的后验分布,可得到最优解。这个步骤叫E步。再按当前的隐含变量,解得最佳模型参数,叫M步。E步+M步,是EM算法的一个迭代轮回。
Word2Vec
把单词顺序用到学习中。
LDA 和 PLSA 把文档当作词包。磁暴要求把一个词表达成一个向量,向量中只有一个值是1,其他值是0。因为每个词都表达成离散向量,所以词间没有重叠,因此无法从词包中推断出高维语义。
用词的分布假设,从离散词包中获取更丰富的信息。方法是从离散向量力抽取出每个词组的连续 Continuous 信息向量,设两个词意思相近,则两个词的联系向量相近,通过词向量,得到词汇的高级语义。
Word2Ve 是一种语言模型。根据当前语境,预测下个单词出现的概率。和产生式模型相似,从模型中产生单词。和主题模型不同,没有假设单词是从某几个模型中产生。
核心思想是,当前单词是周边单词的隐含表达,或词向量中产生的。每个单词都依赖上下文,单词的产生,依赖周围单词的连续表达。这个连续表达是需要学习到的未知参数。
两种模型
- Skip-Gram,SG。输入一个词,输出词周围的词。看能否用这个词预测周围的词。要表现的好,当前词必须抓住某种语义信息。用当前词的表征向量和其他词的表征向量作点积,归一化,保证两者相似,用于把词序影响到词的表征向量中。
- Continuous Bag of World,CBOW模型,和SG相反。输入一组词汇,希望得到中间某个词的预测。也是基于表征向量实现学习。
扩展
用到离散数据:语言模型把词库转成离散数据。如把词汇库从英语单词换成物品的下标。则 Word2Vec 变成对物品序列建模的工具。
- 表达离散数据图,社交网络 Social Network,用户两两间可能相连。把用户看作单词,整个社交网络就是单词间的网络。两个单词间的连线看作单词一起出现的上下文,则可以对图建模。当然,很多工作在优化上下文的定义。
上下文的语境信息:换上下文,使得 Word2Vec 产生不一样的词向量。 - 把学习词向量,推广到句子和文章中。学到比词更大单位的隐含向量。修改上下文,用一个句子周围的词,预测这个句子或上下文中间的一个词。修改是让上下文始终有特殊字符,即当前段落或文章的下标。下标对应的隐含向量,就是我们要学到的段落或文档的向量
- -在查询关键字和用户点击网页间建立上下文,使 Word2Vec 可以学到查询关键字和网页的隐含向量,即用查询关键字来预测网页出现的概率。这是巧妙用上下文,使模型学到离散数据的隐含表达。
对更多信息建模:Word2Vec 添加更多信息,如文档本身、段落
应用
- 计算词间的相似度。用 Word2Vec 中的词向量表示每个单词时,用余弦相似度(点积、归一化)对两个词向量进行计算。假设结果值越大则越相关。有很多相关度的任务,如相关词聚类,可以用K均值算法或Word2Vec,都是计算两个数据点的距离,用余弦相似度实现。、
- 词语类比。词向量是一个连续空间的相邻,可以进行任何数学上的运算,如四则运算。如单词“国王”-“男人”+“女人” ≈“王后”,可以得出有意义的结果。
- 用词分类。文档的类别,或文档有什么感情色彩。词向量是文本监督学习任务的重要特性。也支持深度学习架构,因为多层感知器需要输入连续的数据,将离散文本学习成连续向量,就是在学习 Word2Vec,经过这层转换,可以用多层的神经网络结果对信号进行处理。
- 实践中发现,把学好的词向量当作输入,即用提前训练 pre-trained的词向量,再用于多层感知器,可以提升效果。
序列建模RNN 架构
更丰富的用文字序列信息,从而对文本进行大规模建模。
文本中的序列数据。句子,段落,章节,文章,对话,都是序列(顺序)关系。需要对时序建模。
传统机器学习,经典时序模型有隐马尔科夫模型 Hidden Markov Model,HMM,假设是,当前的序列数据根据隐含状态产生。HMM 认为每个时间点有一个对应的隐含状态,这个状态之域当前时间点之前的时间点,对应的隐含状态有关。更简单的假设认为,当前时间点的隐含状态,只与之前最直接相邻的一个时间点的隐含状态有关,这是一个强假设。HMM 构建一个隐含状态的一阶(最近邻的一个时间点)马尔科夫链。构建好隐含状态后,就可以对链条建模。效果上,模型的表现力有限,因为只有异界,无法对所有隐含状态的转换建模。超过一阶的表达训练复杂。HMM不适合大规模问题。
RNN,是一个框架,在框架内部根据不同需求,构建不同模型。 优势是深度模型的很多优化算法,可以直接用到RNN上。
1个RNN,有1个输入序列X和1个输出序列Y,两个序列随时间变化。假定X,Y不独立变化,变化关系由一组隐含状态控制。T时刻的隐含状态有2个输入,T时刻前的隐含状态,当前时刻 即T时刻的输入变量X值。输入产生一个输出Y,T时刻的Y值。在简化状态下,不是每个时刻都有输出信息,则对一个句子分类,只有整个句子结束后才输出,则Y仅在最后一个时刻实现。隐含状态可以通过标准的深度学习框架学到。
最简单的RNN模型,需确定2个元素。
- T时刻处理过去的隐含状态和输入X,从而得到当前的隐含状态
- 从当前的隐含状态到输出变量Y
元素选择:T-1时刻的隐含状态是一个向量 Status(T-1)
选择1:用一个线性模型表达对T时刻的隐含状态Status(T)的建模。即把 Status(T-1) 和 Status(T) 当作特性串联起来。用矩阵W作线性变换的参数。或许加上一个偏差项 Bias Term。则当前的隐含状态可以是过去所有隐含状态及输入的一阶变换结果。将线性变换改成任何深度模型的非线性变换,就是更标准的RNN模型。
选择2:将Status(T)变换成Y,简化为,Status(T)就是Y,表达隐含状态和输出变量的一一映射。
但这个模型不能用,因为深度学习模型依赖反向传播 Back Propagation,来计算参数的梯度,用于优化算法。但RNN的问题是梯度爆炸,或梯度消失,这两种梯度异常导致无法进行优化算法的迭代,因而无法学到模型参数。
解决梯度异常,可以设计 门机制 Gated Mechanism。主要解决隐含变量从一个时间点到另一个时间点的变化,使整个向量变换成另一个向量。通过限制向量的变化,不让整个向量进行复制,让部分单元变化。设计门机制,使得模型知道当前模型知道需要对隐含向量的哪些单元进行复制,则不复制的单元可以变化。复制的单元被屏蔽了转换这个操作。门机制的实现,使在隐含变量中引入伴随变量G,伴随变量有和隐含变量一样的单元个数,不过取值范围是0或1,0不许通过,1允许通过。只要伴随变量和隐含变量相应单元相乘,就可以控制单元。
基于门机制的RNN架构,
LSTM:将隐含变量分成2个状态,一部分是存储单元 Memory Cells,保留信息,保留梯度,跨越多个时间点,由门函数控制,决定信息保留到下一个节点的数量;一部分是工作单元 Working Cells
GRU:为简化 LSTM,两套门机制决定隐含单元的变化。一个门决定哪些单元复制,形成临时状态;另一个门融合临时状态和过去状态。
RNN 整个过程是编码解码的过程,从已知的序列,到中间的隐含状态,再到输出序列
应用
分类:输入一个序列的文字,作决策,输出一个符号。这是文本挖掘和分析中最基本的场景。相比于传统文字表达,如词包或N元语法,效果差不多。
在句子级别的情感份上 Sentence-Level Sentiment Classification,效果好,常用于分析商品的评论文本 Review。对每个句子至少输出两种感情色彩的判断,褒义或贬义,如分析一个电影。流行的RNN建模方式是,把每个单词作为一个输入单元,把一个句子当作序列输入到一个RNN,维持一个隐含状态。句子结束时,用最后的隐含状态,经过多层感知网络,产生二元或多元的分类输出。
用2个RNN 建立起的链条,能提升分类效果。一个模型,RNN把一个句子按顺序输入或归纳;另一个模型,用RNN建模句子的逆序,把句子倒过来,学习一个隐含状态。串联顺序的隐含状态和逆序的,成为分类器需要学习的特性,这种架构称为双向模型。
从句子到文档的层级,RNN很难针对长序列建模,需要把文档拆成小的单元,如句子,句子还可以拆成短语,对不同级别的数据建模,再把小单元的RNN结果作为输入串联,这叫层次式 Hierarchal RNN建模。
特征提取器:在监督学习任务中,隐含状态被作为特征使用。适合任务对文字顺序有要求。常见任务有,
- 词类标注 Part of Speech Tagging,POS标注,针对某个输入句子,分析和标注词性,如名词,动词。获取到句子的语境。可以用双向RNN,构建的隐含信息包含上下文。
- 通用文档分类,如分为 艺术,体育,时政。RNN 和 卷积神经网络 CNN 结合效果好。计算机视觉中,CNN可以抓住图像的位置特征,善于挖掘二维数据结构局部的变化特性,用于有效的总结数据点。如果把文档排序看作一种图案,CNN 可以对文档的上下文进行提取,提取到的局部信息输入到RNN,对文章的高维特征进行建模。
对话模型
是文字相关的人工智能系统。
图灵测试,是建立在对话系统上的。一个人和一个机器对话的过程中,能否猜出这个系统是真人还是计算机程序。智能的对话能力,是衡量智能的一个标准。
早期对话系统,基于规则 Rule。特征不是理解对话,而是针对预设模板,模仿对话。机器学习+规则,在多数场景下效果好,因此规则很重要。
对话可以分为,
- 基于任务的。如打电话给航空公司或酒店或餐厅订票。特点是有明确目的和流程。
- 非任务的。如聊天机器人 Chatbot。
- 需要对知识库建模,如今天天气,喜马拉雅高度。和数据库查询类似。
- 需要推论 Inference,如比纽约气温高的美国西海岸城市有哪些,这需要理解比较词”高“的含义,转成对气温数值的比较。
架构
- 语音识别 Automatic Speech Recognition ASR,转成计算机能理解的信号。如智能家居回应你的指令。
- 自然语言理解 NLU,理解文字,如提取关键字,理解数字,比较词。
- 对话(上下文)管理,DM,跟踪和检测上下文内容,明确指示代词。监控对话状态,现在的情况和下一步的操作
- 任务管理 TM,执行任务,触发执行动作。
- 输出文本,NLG,产生语言连贯、符合语法的有意义的自然语言。
- 把文字转成语音,TTS
任务型对话
NLU
- 获取输入意图 Intent,这是一个离散的输出结果,是多类的分类问题,或句子的分类问题。如餐馆订餐或查菜品
- 细节。获取可执行 Execution 的信息。如订餐时的餐馆名,预定时间,用餐人数,执行预定,保留记录。这种分析也叫填空 Slot Filling,可以看作一个分类问题,可以用条件随机场 Conditional Random Field,或递归神经网络 RNN
DM:补全缺失信息,如就餐人数,订餐人的联系电话。DM 可以基于规则;或分类,用CRF 或 RNN 建模
TM:如操作数据库,完成订餐流程。DM 和 TM 多是联合构建,用深度强化学习管理。用协议学习,智能补充,完成操作。用简化方法让用户快捷回答问题
NLG:用填写模板,或RNN中的 LSTM进行建模
聊天机器人
基于信息检索的对话系统,在知识库的基础上和用户对话。知识库可以是海量的过去的对话(核心假设),也可以是知识。核心假设的实现,找到与当前输入最相近的某个语句,返回之前回复的内容。如果把问题抽象成搜索问题,可以建立复杂的检索系统,对回复内容建模,可以用搜索技术,排序学习。如把输入当作查询关键字,不过输入的语句长。
问题是,无状态 Statusless,无法对上下文追踪。
基于深度学习的对话系统,能有效的管理状态。经典模型是序列到序列 Sequence To Sequence,S2S,对话系统是翻译问题,对输入句子的回应,看作是把某种语言翻译目标语言。S2S 把输入语句的字符,通过机器学习,转成中间状态,这是一个编码过程。当前中间状态结合之前中间状态,用于跟踪上下文。中间状态会随上下文变化。然后解码,把中间状态转成输出字句。
S2S 用 RNN 和 LSTM实现,很多深度序列模型可以用到对话系统中。S2S 可以灵活处理语言上的多样性,及不完全匹配问题,因此效果好
非任务对话的问题:
- 无衡量好坏的标准
- 序列模型,可以给出人性化回答,但无意义,更像已出现语句的深层翻译。因此又尝试结合检索系统
文档情感分类
Sentiment Analysis。很实用,可以分析用户对商品的评价中,涉及的情感,用于商品推荐和搜索。或了解用户对时事观点的异同,分歧,了解新闻的舆情动态。
是文本情感分析中最基本的任务。假设一段文本的作者,通过文本相对某个实体 Entity 表达一种情绪。实体类型有很多,如商品,事件,或人物。文本可以是文档,段落或句子。
这类任务,限制一个文本单元只表达一种情感。这种假设较局限,实际可能多于一种情绪。
基于监督学习。希望通过有标签的训练集学习到一个分类器 Classifier 或回归模型 Regression,从而在未知的数据上预测用户情感。
- 文档分类,即多分类问题。
- 文档有多种情感,情感评分有顺序。即次序回归 Ordinal Regression
选取特性,这是重点:如词频 Term Frequency,或TF-IDF 词权重法,或情感词汇如好,差,不尽人意。收集情感词汇集合,集合中的词汇可以跟最后文档的情感有密切关系。
用文字分类器,如朴素贝叶斯,支持向量机 Support Vector Machines。
基于非监督学习。设计打分机制 Scoring Heuristics,对整个文档做一个粗浅的判断。可以分析先识别的词类,特别是大量相邻的两个词的词性,如特别好,副词和形容词搭配。当正向情感词多的时候,则文档偏正向的情感。
优势:通过简单的情感词库,开发出文档情感分类的算法,是一种快速迭代的方式,因为获取大量高质量的标签耗时,甚至不可能。
提取情感实体和方面
很多情感分析任务,围绕 Entity 和 Aspect 产生。Entity 是文本中的某个对象,如产品名,公司名,服务名,人名,事件名。方面是实体的属性和组件。xx 手机(实体)通话质量(属性)不错(情感表达)。
广义来说, Entity 和 Aspect ∈ 信息提取 Information Extraction,这是大的任务类别,用于从大量非结构化文本中,提取有价值的信息,可以用一般性提取技术,或句子的特殊结构。
- 基于 频率 Frequency 提取。先进行词类 Part Of Speech 分析,分析出每个词的词性。统计频率。当达到阈值,认为名词是一个 Entity 或 Aspect。假设是,如在一个产品评论的文本集合中,如果名词反复出现在多个文档,则名词很可能是 Entity 或 Aspect。可以用 TF-IDF 计算词频,从而提取到 Entity 或 Aspect 的候选词。
- 针对情感分析开发,用句子的特殊结构。情感词汇多和Entity 或 Aspect 同时出现,在句子结构中有一个描述对象。用这样的配对结构提取词汇
- 这都是无监督学习,用某种定好的规则或洞察,提取文本;也可以是监督学习。输入文本,输出标签信息。基本想法是针对这句话构建一些特征,学习出一个分类器。这需要输出多个标签,标签间可能有关联,是结构化预测 Structural Prediction 任务,典型模型是 条件随机场 Conditional Random Field,CRF。监督学习的训练集匮乏是一个问题。
意见总结和搜索
Opinion Summarization,Search。
为用户评论总结,让用户看到总体的有代表性的评论,能节省时间和精力,获得更好体验。
总结意见是从无结构的文本中,提取出情感的综合表达。主要是基于 Aspect 的意见总结。特点是:
- 针对 Entity 和 Aspect 总结
- 需提供数量化的总结。指出,持某种意见的用户占百分比。这涉及如何表达和显示顺序。
基于 Aspect 的意见总结,可以和其他文本技术结合,如总结语句可以分成,句子选择和人工句子生成,两种方案。
句子选择:希望最后的总结中,能用已有的,有代表性的句子,这会真实。涉及的问题 1. 筛选句子 2. 重复多余句子的选择。通常是对句子打分来筛选,打分机制可以看句子对实体某方面是否进行有情感的评价。然后对句子聚类,将类似评价聚合在一起,可以过滤掉多余的字句。
人工句子生成:知道物品哪些方面得到评价,评价是正面或负面。将信息输入到语言模型,生成最终的总结。总结中没有原始评价,可能对用户的最终体验有影响。
针对性观点总结,Contrastive View Summarization,针对同一主题两种相反的观点,可以是商品,新闻事件如某个政策法规,选举结果等较有争议的话题事件。
搜索
可以看作搜索是基于分析+总结的任务。通常,用户输入一个主体名,返回主体相关信息,信息可以是意见总结。
难点,针对意见信息的索引和检索。
- 在索引库中,找到文档和词句包括需查询的主体。可以用搜索技术,如文本搜索或基于排序学习的搜索,得到文档备选集。
- 找包含主体的意见、评价。设计评分机制,返回最有说服力的文档。在文档基础上,进行意见总结。可以通过模型,对文档备选集进行意见打分。模型可以是简单分类器,分析子句和主体意见的关系;也可以文本分类器,输出当前文档和主体在哪个方面的关系。
广告
简单场景,一个互联网内容服务商,如新闻网站或社交媒体网站作为发布(广告)商,希望在服务中插入广告,这是一个内容匹配问题。目的是匹配广告和目标人群(受众),使得目标人群对广告产生兴趣并点击,产生行动,如购买商品,订阅服务,或者对品牌有印象。
基本的广告模式
- 搜索:发布商提供搜索服务,将广告展示在搜索页面上,广告和查询关键字语义有关。
- 展示:在发布商的页面上推荐。
广告商,发广告,目标有明确的定位,希望增加销售,提高订阅数量,提高品牌效应。因此,希望在决策上有发言权,如何显示广告,什么情况下显示,针对什么人群显示,这决定了广告的特殊性,要满足广告商的需求,吸引广告商来打广告。发布商会提供工具,帮助广告商了解自己的用户群体和广告效果,确保发布商可信赖。但发布商和广告商利益不完全一致,发布商需照顾用户群的感受。如医院在新闻网站上投广告,新闻网站需考虑,长远看,广告内容和新闻内容的和谐,避免用户的厌烦情绪。因此,发布商需平衡广告投放效果和内容服务效果,实现价值最大化。
发布商需构建系统,广告商需研究发布商工具,因此,中间平台产生,整合机会。由广告交换平台,通过竞价 Bidding,实现中间平台的机会交换。
架构
实时竞标,real time bidding,RTB。角色有:
- 广告供应中间商 SSP:内容提供方,免费提供服务,但流量大,通过发广告获益。
- 广告需求中间商 DSP:用流量接触更多用户,从而推销自己的产品或服务
- 公告交易平台 ADX
- 数据服务平台 DMP
一个平台可能有多个角色。
用户行为定向。
合作伙伴的参与动作,RTB 可以是 SSP,或ADX
- 用户打开网站,网站产生RTB系统请求
- 请求 DSP,涉及用户,当前页面,上下文数据
- 请求DMP,收集用户更多信息,如年龄、性别、喜好
- DSP 返回合适广告和竞价价格
- RTB 收集到所有广告竞价后,举行拍卖 Auction。不同 RTB 规则不同
- RTB 向 DSP 发送收款价格
- 广告显示给用户
每个流程的不精确都可能让广告不符用户喜好。
在广告生态系统中,用户追踪是非常重要的能力。如果无法有效管理用户信息,则无法显示相关广告。基本技术是用户 Cookie,识别用户身份,Cookie 和域名相关,所以经过允许,用户信息收集方可以嵌入脚本到其他网站,来收取用户 Cookie 信息。问题是,收集方很难收集到用户在互联网上的全部行为信息,这不利于展示最优价值的广告。因此,整合 Cookie,基于某些共同标识符(如设备ID、浏览器指纹、IP地址等),系统推断出多个不同的Cookie实际上属于同一个用户。据统计,一个用户在30次点击内,有99%的概率被前10大”数据追踪机构“追踪,至少40%的 Cookie 可以得到有效整合。
当然,用户可以禁止Cookie,因此,基于其他存储技术的用户追踪,如 Canvas API 或 Flash Cookie,流行起来。
回馈预估
广告本身的交互;广告代表的服务或商品,达成的交易。叫 回馈 Feedback。要预测用户这种行为的可能性,或概率,如用户点击广告,看完视频广告,购买广告商品。
对广告回馈概率进行有效估计,是广告生态系统组件中的核心需求。预估的越准确,则越能保证收入。
简单设定下,回馈预估可以看作监督学习任务。标签是用户动作,如点击、观看、购买。需要建立用户在某种上下文对广告标签的模型。上下文含查询关键字、用户信息、广告信息等。
挑战是,
- 数据稀疏 。从概率角度,用户是不点广告的。则大量数据点都是未交互的数据,只能看作负例。正例的数目,通常是负例的百道千分之一。在不均衡的数据中进行概率估计是一件困难的事。购买事件比广告更稀疏。
- 目标函数。在候选广告中,选出几个展示在页面,这是一个排序问题,用于竞拍。需要对广告能赢得竞拍,进行估计。
从监督学习角度看,常见算法是 - 把广告回馈预估看作二元分类问题,用对数几率回归 Logistic Regression 建模。
- 用树模型,如 GBDT 用在搜索中的模型,利于排序学习。
- 用深度学习建模
点击率预估
根据环境和广告类型,估计用户点击当前广告的可能性。预估值可用于广告主的计费模块。因此准确性和实时性要求高。
Google
在线逻辑回归 Logistic Regression。传统且强大的线性分类工具。是点击率预估的核心算法。
逻辑回归对二元分类问题建模,核心是通过一组特征及对应的参数,对目标标签拟合。拟合过程通过逻辑转换或者函数完成,使得线性的拟合转成非线性的二元标签。
FTRL Follow The Regularized Leader,在线算法,模型参数会在每个数据点更新。目标函数分三部分:
- 用过去的梯度值 Gradients 重权 Re-Weight 所有参数值。用梯度控制,使参数变化符合数据规律。
- 当前参数值,与之前的参数值的偏差,尽可能小。使得参数不随异常的数据点发生剧烈变化。
- 当前参数值有稀疏解。
算法对每个特征维度的学习速率,有一个动态的自动调整。这是传统的随机梯度下降或简单的在线逻辑回归没有的,避免花长时间手动调学习速率参数。同时,学习速率能根据每个特征维度上特征值的差异,即梯度平方和倒数↓,调整学习速率↓。
系统调优,减少内存消耗 - Bloom Filter,动态决定某个特征加入到模型。这是概率性的,可能被错误加入,但错误的概率小。可以看出,特征仅在少量数据中
- 用紧凑的存储格式。
- 计算 FTRL 更新时,用粗略的估计方式,使得过去的梯度信息可以部分存储。
特别提出 - 在点击率预估这样非常不对称(正例 ≪ 负例)问题上,需对负样本采样。直接采样会导致参数估计的偏差
- 对模型的最后预测进行调整 Californian,使得模型输出和真实点击率分布相近。这对于用点击率计费很重要,因为可能有系统性偏差,使得预测数值整体与历史观测值不一致,造成计费的偏差。
失败实验 - 没必要对特征Hash。特征经过Hash后,没有降低内存,还让模型的准确度下降。Hash 也让模型变得不可解释。
- Dropout 没有显著效果。
- 参数归一化,让参数在一定范围内不波动。会让模型效果降低。
FaceBook
雅虎
LinkedIn
Twitter
阿里
出价
基于第二价位的广告竞拍
在众多广告中选择1个,即广告的竞价排名。基于,广告位有限有竞争,引入竞价机制会抬高广告单价,可以让广告中间商或发布商获利。
基于第一价位的竞拍。投标方定好自己的出价,一次性统一出价,出价时,看不到竞争对手出价,确保出价的诚实性。价高者得。问题是,竞价结果虚高,不利于广告商的长远发展,也打击广告商的积极性。
基于第2价位的竞拍。
- 按期望收入排序。期望收入=出价 (Bid)×点击率 (CTR)。点击率是广告被点击的概率,基于历史统计得出。
- 用第二高排名的价格作为第一高胜出者的支付价格。这更符合广告商对于广告位真实价值的判断。
难点:
- 广告商希望知道在当前出价下,有多大概率赢得竞拍。这对于广告商调整自己的出价有大的指导意义。
- 对整个出价概率分布的一个估计,叫竞价全景观 Bid Landscape 预测。预测用简单模型,可以假设服从对数正态分布 Log normal,于是,可以从数据中估计分布的参数,获得这个分布。
- 问题是,广告商不知道其他对手的出价;以及在没有赢得竞拍情况下,赢得竞拍的出价是多少。因此,我们只观测到一部分数据,即我们赢得广告位的出价。因为数据不全,所以预测不准。有用对数几率回归,来预测不全的数据,从而调整对数正态分布。
竞价策略
DSP 和广告商的竞价策略 Bidding Strategy。基于实时竞价 RTB。自动竞价模式下,需要一种指导,使得计算机能根据形式变化来出价。
竞价的重要特征是,作为竞标方,不知道其他竞标方的点击率和出价,在一个信息不完整的竞价环境中。只能根据自己的点击率估出自己的出价,或根据过去出价成功对整个市场形式的判断。因此,竞价策略有2种思路
- 把竞价策略看作博弈 Game。用博弈论方法,对竞价环境种,竞标方的行为和收益进行研究,针对竞标方行为间的关联性进行建模,关联包含收益和动机。这主要在学术界,因为假设多,如竞标方是不是理性,市场是不是充分竞争。
- 把竞价策略看作统计决策,即直接对广告商的行为建模。把竞价环境中的联系,看作当前决策下的不确定因素。因此,对不确定性的建模更重要,而各个竞标方的行为决策不重要。只从广告商自身角度出发,可操作性更强。
第二种思路,就是根据当前输入,如页面、广告、用户、上下文,学到一个输出价格的函数。函数值就是出价。
搜索广告竞价:每个出价针对一个关键字,车辆广告商可能竞标自己的车品牌,如”大众汽车“。或者竞标更宽泛的关键字,如”买车“,”汽车“。出价是事先设置好的。可以用机器学习对出价建模。用线性函数把信息当作特性,学习从特性到出价的线性关系。
展示广告竞价:广告商无法针对场景产生出价。这要求提供商在不同场景中帮助广告商出价。用 CPM 的收费模式,一旦赢得广告位,广告商就要支付费用,因此需要针对当前页面显示机会,预算剩余等因素建模。
竞价系统的其他问题
- 预算步调 Budget Pacing。希望广告展示相对平缓,不会再短期时间内,用完预算。这对广告的出价方式有影响
- 保留价格 Reserved Price。设置最低的竞价价格。确保收益,但低价过高可能让广告商觉得不划算。因此,保留价格的设置很重要。
优化广告竞价策略
单个广告推广 Campaign
简单假设,推广计划的出价是点击率的一个函数。
- 赢的概率 Wining Probability,已知市场的价格分布和我们的出价,则赢的概率就是已知概率密度函数求概率的计算,即积分计算。
- 效用 Utility,这是广告商关注的指标,通常是点击率的函数,如利润=每次点击后的价值-成本。成本是出价后产生的交易价格,如果基于第一价位的竞价,则成本是出价;基于第二价位的竞价,则成本是超过第二价位多少,还能赢得竞价的价格。
限制条件:所有广告的推广计划必须在预算内
竞价策略:假设,不考虑预算,竞价的核心是“按价值”的竞价。则最优策略是按照点击率x点击后产生的价值出价。这是业界接纳度最好、最直观的竞价策略。若有预算和当前交易流量信息,则我们或许不会按自己客观认为的广告价值来竞标。要应对预算和交易流量的限制,可以按广告的价值出价x系数,这是一个线性变换,也叫线性出价策略。效果好,但没有太多理论支持。更通用的框架,是用不同的效用和损失函数。核心思路是,找最优出价,或竞价函数的目标,表达成有限制的最优问题 Constrained Optimization。目标是当前竞价流量下的收益,限制条件是竞价流量下的成本=预算。即在期望达到预算情况下,尽可能扩大收益。限制条件决定了问题的解空间。于是,整个问题的求解变得相对规范化。标准的求解过程是用拉格朗日乘数法,把有限的优化问题转成无限的优化问题。针对目标函数求导置0,得到结果值。这是标准的数学微积分的内容。在这个框架下,基于第一或二价位的最优出价,都是基于点击率、当前竞价流量和预算的非线性函数,则之前的线性竞价策略就不是最优的。
多个广告推广
把单个广告的有限优化问题扩展到多个广告。除了满足总的预算要求,也提出基于风险的控制思路,来计算每个广告推广计划的均值和方差,通过限制方差的大小来降低风险。但优化是一个基于EM 算法的过程,解是局部最优解。
控制预算
预算步调优化 Budget Pacing,在某时间段内均匀分配广告商的预算。理想的状态是一个广告在一天的不同时段被不同受众看到,实现扩大广告受众的目的。常见思路
- 节流 Throttling。把单位时间的支出或成本控制在某个速率内,使得预算能被均匀使用。可以把节流当作线性优化问题,并且是有限制的最大化问题。对于每个出价的请求,可以做一个二元的决定,是否接受出价。对于每个价值请求,有一个价值和成本,根据不同出价请求的设置做优化,实现总价值最大化,但也要实现成本<=预算,这就是在两个目标间寻一个均衡。可以用拉格朗日乘数法解,但不能实时的对整个竞价的安排进行计算和更新。一般是线下计算。因此,不适合快速变换的竞价环境。也有通过节流,即在线优化控制预算的情况。
- 修改出价。直接修改竞价,实现预算均匀化。思路是借用控制论的思想,到竞价的直接优化上。目标是让广告商的预算能平滑使用。 控制是DSP的实时检测各种指标,如竞价赢的比率,点击率等。以这些数据为参考,形成回馈信息以供控制系统对出价进行实时调整。这种思路比节流更灵活,但实际中,很难做到对点击率和竞价全景观的准确预测,用节流的思想,即不修改出价,更简单有效。
频率上限 Frequency Cap,限制某个或某种广告在某个媒介上一段时间内出现的次数,如限制一个肯德基的广告在半天内让同一个用户看见的次数。
限制原因:降本增效,花钱少,效率高
- 希望广告预算不在短时间内消耗完。
- 用户反复看广告会有厌烦情绪,降低广告有效度。对于广告商来说,这是消耗的资源。
没有好的解决方案。
竞价低价
发布商在广告竞价流程中的调优,广告竞价中的低价优化。底价方案好,可以增加市场的竞争,从而人为抬高竞价,增加收益
低价是竞拍的最低价格。因为,理想状态下,一个充分竞争有充分广告元的市场,广告单价逐渐升高,因为广告资源有限,所有广告商为竞争有限的广告位,必定太高广告价格。作为广告发布者,可以享受到逐渐升高的广告位价值。但是,理想状态的竞争态势∄,对于一个新的内容提供商,新闻首页顶端的广告位更吸引眼球,这种广告位可以引起充分竞争。但其他广告位的点击率只有顶部广告的1/10,甚至更少,则对于无法带来充分竞争的广告位,内容发布商无法收取理想状态下的收益,极端情况下降价甩卖。即真实的广告竞争市场中,很多广告位无法得到充分竞争。此外,同一广告位在一天不同时段的竞争不同;搜索广告,不同搜索关键字有不同的竞争。因此,广告发布者要保护自己的广告位价值并保证最低收益。因此,设置广告竞价的最低价格。即底价,所有广告位不低于这个价格,就人为的抬高了广告位的竞争水准。带来的问题是,底价抬高,会打击广告商的积极性,进一步影响广告位的竞争,让整个市场变得竞争不足拉低价格;底价太低,则没有起到实际作用,广告商可以用较低价格获得广告位,而广告发布者没有得到足够利益。
底价优化
在基于第二价位的竞价系统中,三种底价,这导致发布商有不同收益
- 底价高于竞价的最高价
- 底价高于第二价位,最理想,这会有额外收益。要学习到这个底价。发布商的困难在于,广告商在提交出价时,发布商不知道出价,需要猜出价分布。用最优化竞拍理论 Optimal Auction Theory,假设发布商知道出价的一个概率密度函数,这个函数服从对数正态分布,则可以推导出一个最佳底价,用于管理广告的竞价。实验现实,对于某些广告,发布商的收益增加10%+。也有指出,在实时竞价场景中,出价分布不服从对数正态分布,竞价环境也不符醉话有竞拍理论,如广告商出价未必按心中的价值出价,而是为了赢得更多广告位。提出类似于决策树的策略,在不同发布商策略下,获得的不同收益。总体看,发布商可以这样调整底价:当发现底价低于最高出价时,保持或提高底价;当底价高于最高出价时,降低底价。在这种策略指导下,发布商能达到最佳收益。
- 底价低于第二价位
程序化直接购买和广告期货
Programmatic Direct,广告商不通过竞价方式,获取发布商的广告位。而是两者直接签合同,以获取一定量的展示机会 Impression。这在互联网早期,由公司的销售人员直接洽谈。这更快捷。对于顶级发布商,可以把最优价值广告位,如较好位置或尺寸较大的广告,留下来当作 独家 Premium 广告位,用于直接购买合同。用程序让直接购买更便捷是广告中间平台的重要任务。
广告发布商对程序化直接购买的推动:预估未来一段时间内展示机会的数量。如下一个小时,有多少展示机会,这种预估就是对流量的统计。把预估展示机会分成2部分,1. 给 RTB,广告竞价排名,2. 直接购买
程序化的直接购买,不需要发布商和广告商建立联系,而是通过平台交易,这种交易方式和股票类似,平台显示展示机会的统一价格,广告商按需购买,一般需提前几个星期或几个月。广告商愿意提前购买,因为这样购买的广告价值低于他们的心理价位。而发布商需权衡两种渠道间的收益平衡,在市场竞争不完全的情况下,这也是发布商确保一定收益的方法,即在有折扣的情况下卖掉广告位。
不过,程序化直接购买技术少,需要高级的广告系统作为支撑。
广告期权
公告生态系统架构和金融系统,特别是股票或大宗商品交易类似。
- 广告和股票交易一样,有大量交易机会,这需要第三方系统和平台,如股票交易所或广告 DSP,SSP。
- 广告和股票交易一样,价值和价格因为交易带来大的差别,因此,更多的金融工具被制造出来,为生态系统中的种种角色进行风险控制。如对于RTB,虽然这种机制为发布商和广告商创造了一种交易模式,但基于第二价位的竞价让广告商无法对最终的成交价进行有效控制;发布商对利润把握也有风险;广告商和发布商间谈不上“忠诚度”,因为相同的广告位可以在其他发布商那里找到。因此,“期权” Option,这种金融工具被用到了计算广告的环境中。
多数发布商,对广告期权,设置未来某个时间点的,某个或某些广告展示机会的,提前价格,不是实际价格,而是权利。广告商可以买这个权利,用来得到未来的展示机会。当然,广告商不一定买这个展示机会,也可能放弃。
对于广告商,参与竞拍,在最佳时机购买期权,是一个复杂的优化问题,多是借用金融领域的模型和算法。
广告有效性:归因模型
这不是机器学习,在计算广告中的主流应用,但在现实中有大的实用价值。
Attribution Model,是一种计算广告中,分配贡献的机制。广告商想知道,哪个广告起了更大作用,不同广告对最后转化起了什么作用。
难点:
- 没有完全的基本事实 Ground Truth,都基于一定的假设。
- 关系到广告的有效计算,即我们能否推行一个公平的市场,防止其他广告商在平台上博弈。
基本归因模型,不准确,没有理论支撑,多基于经验和传统方法。直观。可能给广告商利用系统进行不公平投放的机会 - 最后触碰 Last Touch。转化前的最后一个广告,拿走100%的贡献值。是使用最广泛的方法,因为简单直观。点击率和转化率的计算,都是基于这个归因方法。可以博弈最后触碰的方法是,让DSP广告商把广告投放给,已对品牌和服务产生兴趣的人。实现大概率的用户转化。这个过程中,广告投放没有起作用,DSP 也没有试图转化新用户,这鼓励DSP 用更保守的投放方式。
- 第一次触碰 First Touch。只要一个用户最后转化了,则这个用户第一次看到的广告,就获得了100%的贡献值。
- 位置触碰 Position Touch。是 最后触碰 +第一次触碰。
- 时间递减 Time Delay,经验方法,从远到近,对所有广告位给予↑的贡献值。
基于模型的归因
- Bagged Logistic Regression,根据当前广告的触碰信息,即用户看的广告,来预测用户是否转化。模型的特征是二元的用户,是否观看了某个广告的信息;标签是用户是否转化。通过特征学到的系数(正数,确保能解释模型含义),表达广告在预测模型下的贡献度。
- 概率解法。某广告对用户的转化,最后作用于1. 直接作用 2. 当前广告和另一个广告同时作用。则一个广告对用户的影响是2部分的加和。即考虑了一阶,二阶关系下的归因模型。
可以把归因信息,用到广告竞价中,即针对有价值的渠道进行有效出价,对没有效果的渠道进行控制。
此外,归因信息可以帮助广告商分配预算,大的预算放在优质渠道进行广告投放。
广告投放扩展受众
受众选择
为让广告商选择受众,广告平台提供2种基本功能
- 搜索广告,基于关键字。假设是,受众兴趣或意图和关键字有关。若假设符合,则可以假设,这种情况下,受众的转化率最高
- 广告商选受众群,基于人口 Demographic 信息,如年龄、性别、地域。
难点 - 搜索关键字。广告商不知道,所有和产品相关的关键字。关键字投放和成本相关,无法投放所有关键字。
- 人口信息。如何找到合适的人口。对于中小广告商,不可能花大的时间和精力研究人口和广告关系
广告服务平台提供这个服务,优化这个问题。广告商仅设置预算信息,由广告平台负责人群的投放。
受众扩展 Audience Expansion,实现受众转化的最大化
- 无关广告推广计划。通过类似算法,找到类似公司,类似技能。优势,无需积累数据,实现对广告推广扩展
- 相关广告推广计划。类似算法,根据广告商对广告推广,选的条件进行选择。
- 结合√。先无关广告推广计划,得到最初扩展用户,尽管质量不高。运行一段时间后,相关广告推广计划,找到更高质量的用户群
类似算法,针对某实体,如公司、人名、地域、技能,通过搜索,返回最相关的K个其他实体,可以看作监督学习。用对数几率模型,对类似的正例和负例进行学习。正例是用户频繁选择,一起投放的实体。模型特性用文本特性,包括文本的词包表达、N元语法;两个实体间的余弦相似度。用图相关度推算,如两个公司在社交关系上的相关程度。
检测广告欺诈
Fraud Detection。不同广告欺诈对应不同计费方式
- 展示 Impression。展示虚假的竞价信息,把竞价展示放到广告交易平台上卖。在广告商买了后获利
- 点击 Click。虚假点击行为
- 转化 Conversion。完成虚假动作,如填表格,下载应用来 mock 转化事件
欺诈源 - PPV网络 Pay Per View。购买流量,在合法的展示机会中插入用户肉眼看不到的,0像素的标签 Tag,诱导广告商,认为产生更多合法流量。这需要广告商检测,用户会不会看见,或是否是0像素产生。通过黑名单,屏蔽欺诈IP
- 僵尸网络 Botnets。试图控制用户的终端电脑或其他移动设备,进行攻击。多应用于拒接服务的DDos Distributed Denial of Service 攻击和发垃圾信息。僵尸网络用作产生浏览信息,这个行为是宿主电脑的用户,无法感知的。应对方法是,检测IP或DNS产生的流量,是否发生根本性变化
- 竟者攻击 Competitor Attack。
- 广告商的竞争对手,用点击欺诈,产生无效点击信息,消耗广告商预算。因此,攻击者因为竞争减少,可以小成本拿到广告位;
- 调竞争对手的广告但不点击,而广告平台依赖点击率排序。点击率低,在无法赢得竞价,间接打压竞争对手
欺诈检测
- “同访问”图,分析异常的浏览行为为。假设,大多数用户,对两个不同网站有不同程度的喜好。除非网络非常流行。即对于多数网站,用户群体不同。如果用户和网站关系发生变化,则是异常。这可以是无监督学习任务,但有无标签的困难。
- 分析用户花多少时间,浏览显示的像素。用于检测0像素的展示欺诈。实验发现,50%以上的像素,多数用户需至少1~3s观看。因此,停留时间可以是一种检测。
- 普遍,把广告欺诈看作监督学习任务,通过特性、过去已知欺诈数据,当作训练数据学习。难点是,欺诈数据少,分类不平衡。
计算机视觉
这是人工智能的核心方向。人工智能用计算机技术mock人的感官,如视觉、听觉、触觉和思维,建立起逻辑推断等能力。
输入是现实中的场景,但需要借助其他感知仪器 Sensing Device,如照相机、摄像机,获取原始信息。通过算法理解,构建语义信息。
难点:
- 数字化的图像信息和需要理解的语义信息。数字,具体图像中的物体,图像语义。一个200x200的RGB 图像,是由12w个数字组成的矩阵,这个矩阵可能代表复杂图像。
- 尝试构造人类视觉系统特性。如反应快;对世界认知的理解,依靠过去的记忆或经验,或其他外界知识,判断图像的物体
应用:日常接触的,如面部识别、光学字符识别 OCR、电影特效、视觉搜索;自动驾驶、无人商店、虚拟现实、增强现实
基础操作和模型
像素表达 Pixel。将图像信息用像素(矩阵)表达很直观。
- 黑白图像,是0/1的二元矩阵,矩阵中每个元素是一个像素。0黑1白;
- 灰度图像,矩阵中每个元素是灰度的“强度” Intensity,从0 黑~255白
- 彩色图像,用RedGreenBlue模型,任何一个彩色像素,是RGB三种颜色的叠加,即 RGB 代表三种不同的通道 Channel,每个通道是图像在原始颜色下的矩阵像素表达。每个像素代表0~255的值。即一个彩色像素在RGB模型下,是一个张量 Tensor,三个矩阵叠加的结果
像素,是对真实世界的采样 Sample,每个像素是一个整数,整个像素表达是离散的表达。把世界连续信号采样到离散像素中,难免失真。不同分辨率的失真程度不同。
过滤器
- 基本思想:用线性代数做矩阵变换,用于操作图像。很多计算机视觉的操作,本质是过滤器操作。这种操作,可以理解是函数在特定区间的操作。如移动平均 Moving Average,针对每个像素点,计算周围9个像素点的均值。这会得到一个新矩阵,矩阵用像素表达视觉化,就是在原图像基础上,进行了柔化处理。
- 如果说移动平均,是把图像看作一个函数F在某个区域的取值,即针对F在某点(像素)的取值,用同样的函数F在周围取值,得到新的计算值。特殊的过滤操作,卷积 Convolution,除了在周围取值,还用函数H针对F进行操作。
边界探测 - 找到图像边界。特征是遇到变化,如色彩、景深、照明。在像素或函数表达的情况下,用导数或者梯度 Gradient,涉及大小和方向,来描述函数变化。为减少错误,先边界平滑(如高斯柔化 Gaussian Blur) 和链接,再通过大小和方向,对边界定位 Location
特征提取
理解图像语义,图像中具体的物体,如哪里是一只动物。或图像表达了怎样的社会关系或场景关系,如会议室图像,不仅关心陈设和人物,还关心整体气氛,及气氛是不是传递出了更复杂的,人物间的社会关系。
方法是,抽象底层的图像,建模。
除了对图像本身的理解,可能结合文字,对某个物品或某件事进行描述,如电商网站的商品信息,有图片有介绍。再同时理解图片和文字的任务中,容易想到的方式是,分别抽取特征,建模。
小的计算机视觉任务,有2个步骤,1. 把任务抽象成提取特征 2. 转成机器学习任务,如回归或分类。也可以是非监督学习任务。在学习框架中,一般在一个架构下训练,效果好。
难点,图像信息复杂。如两张人民大会堂的建筑图片,一张地面拍的,一张空中拍的,虽然图片在角度、色彩、位置上不同,但两张照片描述的对象一致。我们希望找到多个变化元素中不变的成分。一个思路是从局部信息 Local Information 开始,从图像中提取特征,这比全局特征稳固。构造局部特征,整体思路是从局部找到有代表性的特征,把因各种因素,造成的特征变化,归一化。
- 找到一组关键点或像素
- 在关键点周围定义一个区域
- 抽取并归一化这个区域
- 从归一化的区域提取局部描述子 Local Descriptor。用于匹配
问题是,可能得到的关键点和局部描述子不一样。所以,构建局部特征描述子很重要。
深度神经网络
深度学习,从数据或特征 Feature 中,构造多层或深度变换,得到非线性的表征 Representation。
可以构造非线性特征,用线性模型把非线性特征串联起来。如网页搜索,用 PageRank 表征一个网页的重要性,这是对非线性的对,网页图的一种表征,由此构建线性模型。对于很多深度学习模型,即使进行复杂的表征转换,在最后一层,对最终输出建模,用的是线性模型。
非线性特征外加线性模型的问题。如何系统性的找到非线性特征,用机器学习的特征工程 Feature Engineering。有时,找到好的特征需要灵感和领域知识。要让模型从数据中发现非线性关系,
- 决策树 Decision Tree 和 树模型。树模型在搜索和推荐场景下有好的表现。它可以表达非线性关系,但层数不能太大,最多3~4层。
- 概率图 Probabilistic Graphical Model。特别用于非线性关系。如文本挖掘中的LDA,推荐领域的矩阵分解。优势是,融合在数据和问题处理上的直觉,让模型有可解释性。甚至因果性 Causality。问题是算法不通用,每个模型都要单独计算训练算法,不适合大数据。
- 深度学习,可以自动挖掘数据中的非线性关系,找数据中的隐含规律,规律可能是非常多层次的非线性转换。并能在计算机上通用,不同模型可以共用一个计算框架。
特点:
- 有不同模型和模型计算框架技术
- 基础模型是深度神经网络 Deep Neural Networks。把多层简单的非线性操作叠加,希望发现更复杂的非线性关系。理论证明,在有足够的内部隐含变量下,深度神经网络可以表达任意复杂的函数关系,即有希望对现实世界中 的复杂现象进行建模。
- 深度神经网络有助于特征工程,学到的特征比手动挖掘的更健壮
- 计算有普适性。用简单的梯度下降,能对复杂网络进行计算,可以针对不同模型,降低应用代价。
深度学习模型
基本模型
前馈神经网络 Feedforward Networks。
线性模型是 x->y,学到一组向量,也叫系数w,通过x 预测 y。在图像中,输入的是向量,输出的是向量,则学到的是矩阵。只叠加多层线性模型,只要每层变换是线性的,得到的结果也是线性的。要构建多层的非线性模型,就需要每层变换是非线性的。最小的改动是,激活函数 Activation Function,如 Sigmoid 函数,把-∞~+∞ 的实数,映射到 0~1 范围内。也叫对数几率回归。用 Sigmoid 激活的线性模型,本质是做二元分类。但 Sigmoid 的值不稳定,因为梯度可能溢出或归零,模型就无法学到参数。解决是线性整流函数 Rectified Linear Unit,Relu 函数,将 set <0=0。
经过非线性的多层转换,最后一层是把已有信息映射到最终输出上,这可以是回归问题,或分类问题。最后一层是线性模型层。中间层用原始信息,自动提取数据特征。
前馈神经网络用到图像处理,最直观表达图像数据的方法是,把图像看作矩阵数据。如 长32像素x 宽32像素x3颜色通道的图像=3072个需要学习的系数或权重。如果长宽改成200像素,则是12w个系数。如果用更简洁的方法表达,要用 卷积神经网络 Convolutional Neural Networks,CNN,方法是
- 试图用向量描述一个矩阵信息,用两个特殊架构对图像数据进行总结 1. 卷积层 Convolutional Layer 2. 池化层 Pooling Layer。
- 卷积神经网络处理图像的架构。卷积层,线性整流函数,池化层,全连接层(前馈神经网络),向量表达。优势是直接处理3层数据,进行3维的变换。卷积层直接作用在3维输入上,用另外一个3维的过滤器 Filter 对原始数据进行卷积操作。如32x32x3的图像,用5x5x3的过滤器进行卷积。卷积操作,是用一个小的过滤器,对原始的大图像,进行函数变换,希望提取到图像的局部特征。有了卷积层,就不需要对原始图像进行表达,只学习过滤器上的参数,减少参数数目。
- 池化层,对数据进一步高度总结。针对某个矩阵的局部,用均值,最大值,总结区域的矩阵数值。如4x4矩阵,用2x2区域 进行最大值池化,有4个单元的2x2 矩阵,每个单元是 2x2 矩阵 区域中的最大值。
- 经过卷积和池化,提取到图像的关键特征。传给 前馈神经网络融合,完整的总结数据。最终是线性决策层,可以是回归或分类。,
优化
区分模型、目标函数和优化过程。以线性模型为例,期望用一组特征,对输出反馈,进行线性预测。线性指的是,针对反馈变量的参数是线性的。
线性模型是数学模型,不限制模型参数如何得到。即数学模型的设置,和得到的参数间,相互独立。得到参数的过程,叫模型训练,或模型优化过程。
线性模型,常用最小二乘法,构造参数学习的目标函数。可以得到一个解析解 Closed Form Solution,也能通过梯度下降法进行数值优化。
模型优化过程
- 选目标函数。机器学习有2类目的,回归和分类。回归用最小二乘法,即 平方损失 Squared Loss 作为目标函数。分类用 对数几率损失。损失,和模型是否是线性的,没有直接关系。但模型往往是线性的,如果目标函数是这2类,用的模型就是线性回归和对数几率回归。
- 根据目标函数找参数的最优解。写出参数梯度。
- 尝试解析解,则不需要通过迭代得到结果值。而迭代只是近似值,解析解是确切值。参数梯度=0,看能否有解。理论上的解析解因为数值稳定性的因素无法得到。
- 没有解析解,则用梯度下降法,这是求一个函数最小值的数值流程。如果求最大值,则用梯度上升。梯度下降只能找到局部最优解。对于凸问题 Convex Problem,局部最优=全局最优。非Non凸问题,梯度下降能收敛到一个局部最优解,但解能不能被接受,不确定。找到最优解的速度,即算法的收敛速度是另外一个问题。
深度学习优化
需要目标函数对参数进行有效学习。深度模型,充当更复杂的特征提取的角色。特点是多层
- 优化梯度计算,因为模型的多层而复杂。在当前迭代下,得到针对模型参数的梯度,梯度包含每个隐含层的参数。计算梯度的方法,叫反向传播 Back Propagation,为了有效快速的计算梯度。
- 因深度模型复杂和高度的非凸性,无法得到解析解。如何用梯度下降求得近似解,是研究重点
- 好的初始值,让优化过程变得容易。梯度下降中,用 Dropout,批量归一化 Batch Normalization,可以有效计算梯度,也有好的数值稳定性
AlexNet
ImageNet 有120w张训练图片,5w张验证图片,15w张测试图片。分属于1k个类别。图片的分辨率都是 256* 256。AlexNet 直接在图片的RGB 像素点上建模。
AlexNet 有 8层网络结构,5层全联通层(前馈神经网络)。每层提取的信息越来越高度的概括。
- 用 ReLu 作为激活函数。减少训练时间,提升模型性能
- 用 GPU 训练和计算。释放模型的大小
- 用局部响应归一化 Local Response Normalization ,对每层的单元进行归一。局部响应归一弃用,但归一化很重要
- 重叠池化 Overlapping Pooling。池化是从周围单元中总结出必要信息。一般池化不会重叠,但重叠池化能降低错误率。后面弃用
- 防止过拟合 Overfitting。模型在训练集上好,但无法泛化 Generalization 到测试集,即预测能力差。
- 数据增强 Data Augmentation,增加 “虚拟数据”,来自真实数据的变形,用于增加数据的多样性,让模型更健壮
- Dropout,训练时,随机把一些单元置零。模型会更稳定。
VGG & GoogleNet
是对 AlexNet 的改进。
VGG,加深层次,获得更好的模型泛化能力,实现更小的分类错误率。改卷积层的过滤器,增加到19层,使得错误率下降1半。
ResNet
图像物体识别和分割
Object Recognition,Segmentation,输入图形,希望模型分析出有哪些物体(物体分类),定位物体的位置(位置分析),图像中的每个像素属于某个物体(像素级分割)。即目标是更仔细的理解图片中的物体。
R-CNN。输入图片,输出选定框 Bounding Box 和相应标签。
- 尽可能多的生成选定框,看究竟哪个选定框对应一个物体。针对图像,用不同大小的选定框扫描,尝试把类似的色块、类型、密度的像素划为1类。
- 用 AlexNet 变形,对候选 Proposal 的选定框进行特征提取 Feature Extraction。
- 最后一层用支持向量机 Support Vector Machine,判断选定框是否是某个物体。
- 判断后,用一个线性归回对选定框的坐标进行微调。缺点,由多个模块组成,繁琐。
Fast R-CNN
- 步骤2,每个选定框需要特征提取,这是一个神经网络,耗资源。并且候选选定框的重叠,导致计算重复。用神经网络替代 R-CNN 中间的4个模块,效果差不多,但时间快了9倍。
视觉问答
根据一个图片,进行基于自然语言的问答。
产生式模型
不仅针对已有数据建模,也能产生新数据。新旧相似,以假乱真。产生数据的工具
- 概率分布。正态分布或高斯分布,对一个连续变量建模,如某地温度,可以得到均值和方差。产生所有文档的可能值。设温度服从这个正态分布,则可以认为可能值是这个地区可能出现的温度。
- 概率图=概率论+图论,对复杂的联合概率分布进行描述。很难建造,用产生式对抗网络 Generative Adversarial Nets,GAN,有数据的产生器 Generator,判别器 Discriminator,迭代,直到判别器无法分出真伪。这不是对数据的产生过程建模,而是定义一个流程,用流程产生数据,直接对真实数据 mock。但问题是gan 在限定条件下不是对整个数据分布建模。这是研究重点。
人工智能
在实践中学。通读这个知识点的相关内容,相同内容多看不同观点。
和每篇论文背后的作者进行一场对话。
背景,作者群,对应学术机构和公司
解决的问题,核心贡献(主线),方法
演讲报告
讲座 tutorial:总结好的,系统性的研究成果
研讨班:work in progress
跟踪活跃、有权威的学者,研究组或公司
- 在领域内有重要贡献,特别是贡献了核心思想
- 关注其论文数目和影响力
- 看领域中引用度最高的前几篇,看学者过去的论文发表经历,判断是否在领域内持续研究
了解主干,便于清楚技术的时效性
- 文献综述
- 顶会的讲座
- 主干内容可循环使用,如深度学习有前馈、卷积、递归神经网络。了解是什么,这种结构要达到什么目的,解决怎样的问题
深入学习少量模型 - 工业界,掌握线性、树、神经网络模型,就可以解决超过80%的业务需求
- 了解原理,从数学的角度进行推导,理解模型本身和优化算法的区别,优化算法的好坏
- 动手写模型的基本实现
- 模型的特点,适用场景
技术选择
- 当很多学术会议都在讨论某个技术时,可以做评测。看这样的技术在自己工程环境中的数据有效性
- 理解其他公司的技术选择思路,比分享内容本身更重要。公司的技术选择,与做选择时的因素相关。如一个大的机器学习系统,与公司的其他业务需求,数据基础、基础设施和团队工程水平相关。公司技术发展不能摆脱内外限制,需批判的看待结果
- 重点是理解组件间的逻辑关系,关键技术背后的推理和取舍
成果转化
- 理解论文是怎么写成的,可以更快挖出论文的核心价值;把自己手上工作总结成论文发表,真正参与到学术社区的建设;用研究的标准要求日常工作,可以让工作更严谨
- 针对某一问题,有新方法、新见解或新结果;发现新问题,新领域。就有发表的潜质
- 可能的创新点,如AB测试。判断网站的新功能是否好于现有版本。问题1,用作AB测试的流量小,可能需要2~3周才有结果,验证时间长;问题2,如果测试的功能和收入相关,但无法在实验过程中动态调整预设比例
- 如推荐系统,相机复购的概率不大,则不适合重复推荐
- 做研究:
- 总结当前场景,要解决的问题。即针对要研究的问题进行建模归纳。如电商相机不重复推荐,要解决的问题是把重复(类似)过滤掉,还是推荐相机相关的附件,还是推荐相机的替代品。或从根本上理解这样情况是怎么产生的,消费者的心理预期是什么样的。所以,即便解决同一个问题,也有不同切入点,要先找准切入点。
- 了解前人工作,查找和学习相关文献。可能你设想的方法前人已经尝试过了。看前人在你设想的问题中,如何找到方案,和你的思路是不是一致。针对差异性提供进阶思路。
- 选择一些标准可信赖的测试数据集和一些基线方法进行比较,用于说明新方法好在哪,了解系统设计和整体思路在社群中的位置,将系统和类似系统进行比较,便于技术选择
## 基础
### 热点
### 研究
### 技术选择
### 学术会议
## KDD 2017
### 线性支持向量机
## EMKLP 2017
## ICCV 2017
### Mask R-CNN
### 目标函数:焦点损失
### 视觉问答系统:深度强化学习
### 非凸优化
### KSD测试检验两个分布的异同
### 非完美信息博弈
### 位置偏差估计
### 挖掘商品的替代和互补信息
### 深度学习上下文
### 商品的图片美感建模
### 推荐算法 BPR改进
### 从文本中提取高元关系
### 计算机视觉任务间的关系
### 从整体上对人体进行三维建模
### 排序学习计算复杂度高
### 偏差和流行度
### 对抗学习增强排序模型的普适性
### 对搜索页面的点击行为进行序列建模
### 对抗样本对模型的攻击
### 机器学习算法的公平性问题
### 优化目标函数,可能放大了不公平
## ACL 2018
### 问答系统,提出好问题
### 对话中的前提触发检测
### 端到端的语义Hash
数据科学团队
建设周期
团队小,则需要通才。主要工作:
- 搭建公司的数据平台,数据引入、整合、清理
- 计算简单的产品运行指标 Metrics,在仪表盘 Dashboard 上展示出来。
- 数据分析主导,和产品经理、工程师一块分析产品问题,为产品迭代的决策提供数据支持。
- 算法建模优势不大,若有需求,需快速识别和实现基本的模型
团队大,则需要专才。主要工作
- 数据分析:一类是,设计A/B实验,设计和分析产品指标;另一类是,对产品领域进行长时间的分析数据内涵
- 算法建模:针对不同业务流水线,招聘单独人才,如图像处理、搜索系统。不要寄希望招聘通才来发现专才,这个训练的时间周期长。分清形势招聘专才是必须进行的任务目标
概率统计
离散场景还是连续数值建模
离散:
- 伯努利:用于二元问题,用户是否点击、是否购买。
- 分布参数是[0,1]间的实数
- 多项:多于2种选择;文本建模,从千万中选出最恰当的。
- 泊松:可数的整数,如一些物品的总个数
连续 - 正态分布:由于中心极限定理存在,在大规模数据下,其他分布都可以用正态分布来近似或模拟
概率分布,建立关于随机数和参数的概念。随机数是连续还是离散。所有分布都有分布和参数估计两个过程
了解贝叶斯统计,针对概率分布定义先验概率,推导后验概率。如针对用户是否购买某件商品,可以用一个伯努利分布建模,如果想描述男女对商品的不同偏好,可以对男女分别引入不同的参数。两个参数都来自一个共同的先验概率分布(可以认为是全部人群的购买偏好),因此,我们建立起一个具有先验的模型来描述数据。
假设检验:
一个产品,持续做A/B测试,引导产品迭代,这就是做假设检验。
假设检验的基本设定,把现在的系统情况如用户点击率、购买率当作零假设H0,把改进的系统或算法结果叫做备择假设H1。
选择检验模型:看目前的实验环境,是否满足要求,如T检验、Z检验(默认用,当有大量数据可用时)
计算统计量。根据统计量和检验模型,可以得到一系列数值,如P值,比较P值和预设范围值(如0.95),确定,H1在统计意义上和H0不同。
正确对待结果:只能说不支持H0,不能说更支持H1。把结果当工具,结合更加复杂的决策流程,从而产生综合分析。
置信区间,广泛用在推荐系统的”利用和探索“策略中
因果推论 Causal Inference
用于 1. 不可测试的产品,通过数据研究得到期望的结果 2. 想在有偏差的数据中,进行无偏差的训练和评测
机器学习
解决,监督学习和无监督学习的基本思路,是机器学习。
- 把现实问题抽象成数学模型,怎么假设 ⭐
- 用数据工具,对数学模型参数进行求解。取决于模型复杂度和成熟度,多用现成软件包求解
- 根据实际问题提出评估方案,评估模型,看是否解决了实际问题
监督学习:通过外部的响应变量,指导模型学习我们关心的任务,以达到目的。目标是使模型可以准确对需要的响应变量建模。如系统通过一系列特征,来预测某地区的房屋销售价格,预测电影票房,可能购买的商品。这里的”销售价格“、”票房“、”可能购买的商品“,都是响应变量。
- 标注、训练、测试
- 用于回归、分类
无监督学习:没有明显的响应变量。核心是希望数据发现内部结构和规律,提供下一步的参考。如利用数据特征对数据进行分组(聚类)。聚类可以是某一数据∈某类,或∈多个类,不过每类概率不同。
因为监督学习可以发现内部结构,所以,监督学习可以辅助无监督学习。
- 用于聚类
监督学习基础
- 线性模型:如线性回归,对数几率回归
- 假设响应变量和数据特征间存在线性关系。数学假设是 1. 系数(参数)和特征的线性组合=响应变量的预测值;2. 响应变量真实值和预测值中有误差,误差服从正态分布,分布期望值是0,方差是
的平方 - 求解参数。1. 线性回归的解析解。但涉及矩阵的逆运算,运算量大,只用于理论分析 2. 梯度下降法,对部分数据扫描后就可以更新参数
- 评估模型。因为是进行实数预测,最简单的评估法是看预测值和真实值间的绝对误差,所有数据点计算平均误差
- 假设响应变量和数据特征间存在线性关系。数学假设是 1. 系数(参数)和特征的线性组合=响应变量的预测值;2. 响应变量真实值和预测值中有误差,误差服从正态分布,分布期望值是0,方差是
- 决策树模型
- 神经网络模型
处理 - 分类:用模型判断数据点的类别。类别一般是离散的,如2类或多类
- 回归:用模型输出一个预测值。数值一般是连续的实数
了解
- 了解模型的数学含义,理解模型的假设和解法
- 了解什么场景下使用模型最合适,怎么把实际问题转成模型应用,如果不能转差距在哪
- 写实际代码或伪代码描述模型算法,达到对模型的真正掌握
无监督学习基础
- 根本问题是,不同的学习方法对数据内部结构有不同假设,因此,不同模型间常有很大差别。
- 聚类模型, K均值算法 K-means;基于概率的聚类方法,如高斯混合模型
- K均值算法 K-means
- 假设,数据由K个类别组成,每个类别内部的数据距离近,类别间的数据距离远。数学假设:定义数据到一个类别的距离,即距离函数本身。K均值算法中,数据到一个类别的距离=类别平均点的距离,距离函数用欧几里得距离,衡量两数据点的远近
- 求解K均值的目标函数是一个NP难题,多用贪心算法求解。
- 无监督学习没有一个真正目标,所以不易评估算法好坏。对于K均值算法,简单的指标是看类内部数据点的平均距离(小)和类别两两间所有点的平均距离(大)。
了解
- 理解和掌握核心的概率分布,包括离散和连续分布
- 理解假设实验
- 理解因果推断
系统
要求
- 基本的编程能力,了解数据结构和算法。Pyton,Hadoop,Spark
- 搭建人工智能系统,如搜索、人脸识别、图像检索、推荐
Pipeline:数据采集(数据要可靠、可重复)处理-产品。产品是一个自动化的闭合环路。
同步、异步:对于交互性强的产品如电商、搜索引擎、社交媒体,用户打开页面到页面展示内容如推荐商品或搜索结果,这个响应时间就是同步,一般几百毫秒。
如,构建一个垃圾检测系统。如一个二分分类器,需训练这个分类器的参数。训练逻辑回归,需大量训练数据,或用更复杂的二阶算法,不能在几百毫秒完成,则是异步运算。此外,数据收集、特征生成、放在异步。可以将所有邮件,输出到一个特征产生的模块;特征产生后进行邮件判断,保存结果。用户查询时,直接返回结果。但当有大量突发数据来临,需要更新模型。
分析、评估产品
分析
- 场景到算法的翻译能力。如看到一个真实产品,如京东的搜索,科大讯飞的语音识别,搜索引擎查询关键词拼写检查组件。设想如果你是设计者,你会怎么做?
- 把思路、方案,清晰的传递给同事。此外,社区演讲、参与讲座活动,都需要沟通表达。试着用一两句话总结你的方案,不带任何术语。这个训练方法可以让你反复思考,直到找到一个最简洁有力的表达
智能决策:人工智能,带给产品的,不只是核心模型和算法,而是数据驱动的决策过程。 - 数据驱动:通过数据检测、分析,加深产品认识,提出更好想法。
- 不确定下的智能决策:依靠数据决策,快速迭代
- 非智能决策的问题 1. 强依赖执行者能力,具有偶然性和主观性 2. 结果不可复制,决策方法不随时间和数据变化。3. 数据量大,选择可能性太多,决策复杂度变高
- 用于电商网站代替商店导购,自动驾驶代替人工驾驶。可以针对不同人群展示不同界面,为大量用户服务
- 寻找更好的创意,产品迭代方法
评估
- 做一个社交网站,怎么制定检测指标?终极目标是经济收益(赚钱)。需要思考
- 如何衡量经济收益
- 衡量收入现状
- 衡量收入增长
- 能否用经济收益直接指导产品构建:经济收益有时是副产品,如社交网站的广告收入是副产品,但用户来到网站的目的不是点广告
层次化评估体系
- 页面和组成页面的区块。如点击率、驻留时间、用户活跃指标,和产品、工程团队运作有密切关系
- 用户在一个/多个会话中的表现。建立用户模型,通过统计方法建模,来理解用户行为。如在一个会话中检测用户购买商品,及商品的总价值。需要测量和建模流程中每个操作环节的影响。可以通过A/B测试观测,不过需要仔细的设计实验
- 用户和产品的长期目标。如月活跃用户,年活跃用户。无法A/B测试
提高产品性能:提升品质,吸引更多用户
- 优化长期目标。建立产品指标检测体系。如季度利润增长,年利润,月活跃用户等,这些指标和最终目标相关,却难以衡量。
- 建立层级间的指标。如给用户推荐打高分的视频,和产品的长期目标有什么联系?这个联系不仅是逻辑联系,而且是数据链联系,用数据提供证据。可以从所有用户群体中找到用户样本,通过数据研究,用户活跃度和被推荐视频评分间的关系。从高维度看,是建立一个回归问题,如用户向活跃度作为月响应变量,被推荐系统平分作为特征变量,和可以引入其他重要变量来排除这些重要变量的干扰,变量有性别、年龄组、地区等。做这个分析,可以很好的优化对象和长期目标的联系
- 指标和长期目标有正向联系,就是持续推动产品的重要动力。产品才能不断试错但不失去大方向
- 尽可能多记录指标,需要数据,也需要经验。确定好指标后,可以把指标当前算法的目标函数,重新设计算法,使其能优化新的指标
能力要求
基础:机器学习、统计、计算机
现实场景和技术挂钩:用人工智能描述这个场景
动手,代码编写,数据结构
-
清晰说出解决的问题和解决思路。清楚模型细节甚至公式细节。把实验目的、数据、比较算法讲清楚。合作者的贡献
-
清晰讲出基础的概念和知识。这是能够依赖的,提供解决方案的最初的工具
-
诚实的说明自己懂什么,不懂什么。有足够的自信说自己的专长是什么,自己的局限在哪里
-
项目的贡献,职业规划,看职业规划和简历吻合。在一个公司待了长时间但没有升职,询问为什么没有机会
-
一场1h左右的学术报告会。看候选人有较强的语言组织能力,能清晰的表达自己,因为有些人连自己的工作都讲不清楚。在公开场合接受各种质疑和对自己工作的挑战。包含承认自己工作的局限和不足,能有礼貌且一语中的to the point 的回答技术问题。
-
和招聘经理讨论可能的技术方向。招聘经理可以说一些公司的产品或项目,看候选人是否感兴趣,通过一些简单的产品介绍,问出一些有科学价值的问题。会问问题,是一个非常重要的技能。招聘经理可以稍微深入讨论一两个产品的具体实现问题 ,看候选人能否快速说出一些解决方案或思路。在整个谈话过程,体会候选人是否只有学术经验,而没有产品或产业的感觉。有些候选人显得没法把谈话进行下去,完全是倾听,问不出任何问题。这需要招聘经理仔细控制谈话,看候选人是否对新事物有好奇心,能否跟上思路,是否对新领域新问题有快速的思考。主要考察候选人在一个类似的环境,能否半独立的完成解决方案的设计和实现。沟通很重要,很多条件、约束需要有效沟通来理解清楚,而不是独立解决问题的场景。
-
候选人整体的思维模式 1. 提出一个可能的多步骤解决方案,然后看能否简化步骤,再看能否提出较规范的数学模型。 2. 先提出数学模型,再根据实际情况简化,提出更加快速的算法
-
提出解决方案或数学模型后,用自己掌握的方法,把问题的细节算法写出来,分析算法的各方面特征。考察候选人解决问题的连贯性和独立性。
-
候选人遇到领域外的问题,是如何思考的。小心翼翼的用基础知识,尝试解决问题,或把新领域的问题转成熟悉的
-
除了考察提出优秀的解决方案,还看候选人是否有全局观。比如对这些问题的考量,如何设计更有效的数据通路,没有数据怎么办,上线后系统表现不好怎么办
-
对候选人在白板上进行基本的编程能力测试。除了考察基本的算法问题,还考察能否对普通的机器学习算法进行编程,即是否能把一些模型或算法实现出来。
-
留意观察,候选人的表现是否在有压力或者劳累的情况下有重大波动,优秀的候选人能通过沟通缓解自己的压力。
能力培养,5~6年为周期的换代更新
跨团队的组织、协调和沟通。分清主次。把自己的解决方案说清楚,用通俗的语言解释复杂问题,把主要思想梳理明白,并传递出足够多的信息
不管什么团队,产品或工程师,都是为了产品的进步和提高出谋划策的,希望产品越做越好。但团队分工和专业背景不同,在让产品越来越好的目标上,可能有不同意见
- 设计人员可能认为产品下一步的最大可能性,来自于更简洁明亮的设计风格
- 产品营销人员可能认为,用户对下一场促销更感兴趣
- 工程师可能认为,下一步需要团队重写一个框架代码,让页面渲染速度得到提升,使得用户体验得到改善
- 数据科学家或算法工程师,考虑开发一个更复杂的机器学习模型,提升产品的智能响应
- 产品经理想做一个全新的手机界面,展示一种新的用户生活体验
一个专业,可能过度自信,如过度强调算法和模型对产品带来的影响,忽略产品是一个有机整体;也可能被过度依赖,抱有不切实际的幻想,给这个专业带来大的压力。
产品的最优,往往是各方面的一个复杂的协调平衡,如产品外观设计的改变促进使用,营销手段促进产品转化。让一个专业融入产品的完整图谱中,比提高某个点更有意义
数据分析
- 了解概率统计
- 使用假设检验分析数据,假设检验如非参数假设检验,快速学习和查询到相关方法
- A/B实验,实验设计
- 用因果推论对数据进行分析
- 对时间序列下的数据进行分析
领域知识 - 数据分析工具,如R或 python
- SQL
- Hadoop 等大数据处理工具
- 算法
算法模型
- 了解概率统计
- 机器学习算法模型,如分类、回归、聚类
- 概率图模型、深度学习模型、优化算法
- 计算机:数据结构、数据库、操作系统
- 领域内模型,如信息检索,推荐系统,计算广告系统,计算机视觉,文本挖掘和分析,自然语言处理
- 使用计算机语言,如 Python, C++, Java 实现机器学习算法
- 使用和扩展现有机器学习工具,如 Scikit Learn, XGBoost, Vowpal, Wabbit
- 使用 Hadoop 为基础的大数据工具,如 Hive, Pig, Spark
- 了解深度学习框架,如 TensorFlow, Caffe, MxNet, Torch
工作衡量
绩效评定 Performance Review。规则必须在团队建立初期就明确,否则一些不定因素,对招聘、培训和留住人才,有不可估量的影响。
数据科学最大价值,就是为企业或团队引入数据驱动和持续决策。
- 帮助建立和推动,数据驱动的链路。思考如何更快更好的解决数据问题。包括获取、整理、分析和利用数据的整个流程。
- 实验平台、围绕实验平台进行决策的工具,如图表,更复杂的假设检验工具,如因果推断
- 针对某产品提出可行的机器学习解决方案,和产品部门及其他工程部门一起,让解决方案落地。这依赖数据、产品
- 持续学习。参加会议、发表论文、参与学术讨论、发表开源软件等。初创公司暂时没这样的能力组织时,也要思考如何评价员工在学习
初级:用模型和算法,对整个业务提供解决方案,即翻译业务的能力
中级:有可能的新方向
高级:对某类产品解决方案有深刻洞察,对新场景有快速和成熟的理解
对业务和产品有深入理解,包括需求、数据和工程技术,对产品提出合理和成熟的解决方案。
团队
- 理解团队在工程、技术上的需求
- 和技术社区有积极交互
- 专业性强,能对方案进行评估
工作流
保证项目达到质量标准的方法。增加产品成功的可能性,减少问题的发生
开发:研究项目中,开发的目的是完成文章发表需要的实验结果,但容易变成无人维护和不能更新的情况。用版本管理工具,使用分支,隔离开发进度
部署:CI/CD,对代码的不同分支进行测试运行
数据:数据在第一位。即便有正确的代码,如果数据有偏差,都对结果产生重大影响。任何对数据的改变,如改字段名,都需要面向相关团队的沟通。同时,数据检测很重要,避免垃圾进垃圾出。
值得合作的产品
- 已有产品,有数据,有技术积累
- 是公司的核心项目。即和公司利润或核心用户数据有关
- 要投资组合,投入/回报。
- 特征工程 feature engineering 是高回报。如果基于现在的数据链路做,只计算一些数据的简单统计量,只把每天的统计量做一些叠加,则是低投入
- 核心算法的改进,如改进排序算法,属于高投入,有较长时间的研发周期,升级换代往往需要基础设施或平台级的变化。回报不容易估算,线性改成树,可能有5%~10%的提升,加入适应树的特征,则10%~20% 的提升。