ai-tech-stack
开发流程
- 需求:业务目标与模型性能
- 开发:AI模型的选择和优化,在性能和成本间寻求平衡。涉及响应时间、Token数量,以及API调用成本。模型训练和评估
- 测试、运维
| 层级分类 | 具体内容 |
|---|---|
| 应用层 | ChatGPT, AI绘图工具, IDEAI插件, GitHub Copilot |
| 接口(应用开发)层 | Hugging Face(模型训练,如语言模型 BERT), vLLM(模型推理,支持模型如LLaMA) / Ollama(机器学习模型运行), LangChain(模型应用) 优化技术:量化(TensorRT)、模型剪枝、格式转换(ONNX) |
| 模型层 | GPT-4o, Llama2, Deepseek-V2, M2, OpenAI, QLM, OpenLLaMA, Mistral |
| 框架层 | 深度学习,框架:PyTorch(本地), TensorFlow(工业集群部署) 深度学习,模型:CNN(图像)、RNN/Transformer/BERT(序列)、GAN(生成模型)、BERT/GPT(NLP:spaCy工业级文本分析/词嵌入Word2Vec)。 机器学习,框架:Scikit-learn(传统ML)、XGBoost/LightGBM(树模型) 机器学习,算法:监督学习(线性回归、SVM、XGBoost)、无监督学习(K-means、PCA)、强化学习(Q-learning) 数据处理与分析: - 数据预处理:Pandas(数据操作)、NumPy(数值计算)、Dask(大数据并行处理) |
| 基础硬件(硬件)层 | GPU, CPU, SSD |
机器学习神器Scikit-Learn的保姆级入门教程大家好,我是Peter~ Scikit-learn是一个非常知名的P - 掘金
自然语言处理 ( Natural Language Processing, NLP)
强化学习(Reinforcement Learning, NL)
- 计算机视觉(CV)
- 工具库:OpenCV(图像处理)、PIL/Pillow(基础操作)、Albumentations(数据增强)。
- 模型架构:YOLO(实时检测)、ResNet(分类)、Mask R-CNN(实例分割)。
- 应用场景:YOLO用于边缘设备实时检测,OpenCV处理图像预处理。
- 强化学习(RL)
- 算法:DQN(值学习)、PPO(策略优化)、A3C(异步训练)。
- 框架:OpenAI Gym(环境模拟)、Stable Baselines3(算法实现)、Ray RLlib(分布式训练)。
- 应用场景:游戏AI(如AlphaGo)、机器人控制。
- 图像识别,提取图像特征、图像分类,如用于社交媒体的图片自动标签;
- 目标检测,如找特点对象位置,用于自动驾驶道路检测,零售商店的货架商品监控;
- 实例分割:区分同类的不同对象(区分相似对象),用于农作物病害检测、工业生产线的缺陷检测 这属于哪个技术的应用
- 自动化与AutoML
- 工具:
- 超参调优:Hyperopt、Optuna。
- 端到端AutoML:Auto-sklearn、H2O.ai、Google AutoML。
- 应用场景:Optuna用于高效超参搜索,H2O.ai自动化特征工程。
- AI伦理与可解释性
- 可解释性工具:LIME(局部解释)、SHAP(特征贡献)、Captum(PyTorch专用)。
- 伦理框架:IBM AI Fairness 360(偏差检测)、微软Responsible AI。
- 应用场景:SHAP解释黑盒模型,Fairness 360评估数据偏见。
编程语言的优势,如Java
- 编程基础和逻辑思维能力,便于理解和编写代码
- 经验:处理大规模数据和系统集成,如构建数据处理管道,整合不同组件,软件工程(生命周期管理,理解需求,设计高效可靠的系统,解决问题)
例子
从零开始的DeepSeek微调训练实战(SFT) | 阿里云开发者 | 2025年03月11日 08:31:本文重点介绍使用微调框架unsloth,围绕DeepSeek R1 Distill 7B模型进行高效微调,并介绍用于推理大模型高效微调的COT数据集的创建和使用方法。
- 模型:DeepSeek R1 Distill 7B模型,一个DeepSeek R1蒸馏模型,在保持高精度的同时,显著减少模型的大小和计算消耗,适用于资源有限场景
- 推理( 问题,think解题思路,回答)、微调框架:unsloth,调整模型的权重和偏差。
- 非全量参数微调:LoRA( Low-Rank Adaptation)微调,不直接调整原始模型的所有参数,而是通过在某些层中插入低秩的适配器(Adapter)层来进行训练。原始模型的参数保持不变,只是通过少量的新参数来调整模型的输出。QLoRA 会将插入的低秩适配器层的部分权重进行量化(通常是量化为INT4或INT8),在保持性能的同时显著降低模型的存储和计算需求。
- 推理数据集:COT数据集
- 优点:复现仅需7G显存、半小时运行时间即可完成一次最小可行性实验,并获得微调效果
这篇文章聚焦于DeepSeek R1 Distill 7B模型的微调训练,详细介绍了相关概念、环境准备、微调实操过程,对比了微调前后模型的效果,帮助读者掌握大模型微调技术。
- 基础概念介绍
- 微调与强化学习、模型蒸馏:微调基于预训练模型,用少量数据优化以适应特定任务,计算量小、应用广泛;强化学习通过智能体与环境交互试错来学习最优策略,常用于动态决策任务;模型蒸馏是将大模型知识迁移到小模型,实现模型压缩和高效部署 。
- 大模型微调:分为全量微调和高效微调。全量微调利用全部数据重新训练模型,适应能力强但资源消耗大;高效微调如LoRA和QLoRA,通过调整部分参数提升性能,节省资源。LoRA插入低秩适配器层减少参数调整量,QLoRA在此基础上结合量化技术,更适用于显存受限环境。
- 量化,将权重转成有限数字,精度会下降
- 高效微调的应用场景:包括对话风格微调,使模型适应不同对话需求;知识灌注,将专业知识融入模型;提升推理能力,帮助模型处理复杂推理任务;增强Agent能力,优化模型在多任务协作和功能调用场景中的表现。
- DeepSeek R1 Distill高效微调环境准备
- unsloth安装:unsloth是推理、微调一体式框架,可提升微调速度并节省内存,通过
pip install unsloth等命令安装。 - wandb安装与注册:wandb用于监控和分析训练数据,注册后用
pip install wandb安装。 - DeepSeek R1模型下载:从ModelScope模型地址下载,创建文件夹保存权重,使用
modelscope download命令下载。 - 微调数据:选择与DeepSeek R1模型回复格式匹配的数据集,如包含推理和最终回复的CoT数据集。本文选用医学数据集medical-o1-reasoning-SFT,该数据集质量高,适合医疗领域模型微调。
- unsloth安装:unsloth是推理、微调一体式框架,可提升微调速度并节省内存,通过
- DeepSeek R1模型微调实操
- unsloth LLama模型推理:借助unsloth进行模型推理,设置参数读取模型,调整为推理模式后,通过分词器处理输入问题,用模型生成回复并转化为文本。
- 初始模型问答测试:设置医疗领域问答模板,抽取数据集问题测试初始模型。结果显示模型在原始状态下,对部分问题的回答不符合医学规范或直接错误,问答效果不佳。
- 最小可行性实验:从数据集下载500条数据,对文本进行结构化处理,设置微调参数开启微调。微调后模型回答更规范,但仍有错误,可考虑继续大规模微调,微调结束后合并模型权重。
- 微调参数解析:SFTTrainer用于监督微调,适用于多种模型微调;TrainingArguments定义训练超参数;is_bfloat16_supported检查GPU对bfloat16的支持情况。
- 完整高效微调实验:带入全部数据进行高效微调,给出完整代码。该过程耗时较长,完成后可得到效果更好的微调模型。
语言模型
语言模型应用:
- 语言模型是自然语言的概率模型,生成一系列单词的概率。
- 用数据和算法训练机器,寻找规律进行预测。用微调(基础)、思维链(多角度慢思考)、提示工程(增强上下文)、rag(词嵌入),提高特定任务的准确度。
- rag 词嵌入,用 word2vec glove等算法,编码单词含义,输出值是实数的向量
- 语言模型可以实现语言翻译、内容摘要、和内容创建,在问答应用中非常有价值。
人理解语言的方式:词的关联,推断;上下文;
- 如“下雨了,我要赶紧回家收衣服”。“下雨”,“回家”,“收衣服”,是我们经验中的单词。强相关的单词间组合成句子,继而(上下文)推断出句子背后的含义。
语言数字化,词向量,1个单词有一个词向量。通过数字计算距离(欧式直线距离,余弦相似度 两个向量夹角),确定单词间的语义关系。
Embeddings,嵌入,通过分析大量文本中的模式,将单词、句子等转化为向量(数值),计算距离。单词嵌入根据单词的含义和上下文来表示单词,使模型能够理解同义词或类比等关系。
- 计算机理解语言的方式,是二进制 0/1数字。因此,生成式语言模型会将单词,映射成数字。映射方式,是词向量(wordembedding),表达单词。可以通过加减乘除等的运算,表达单词间的距离,继而生成句子。常见两种距离公式,
- 欧式距离,
,两点 间距离; - √余弦相似度,
,两个向量 夹角的余弦值来衡量向量的相似度,关心方向而不关心大小。
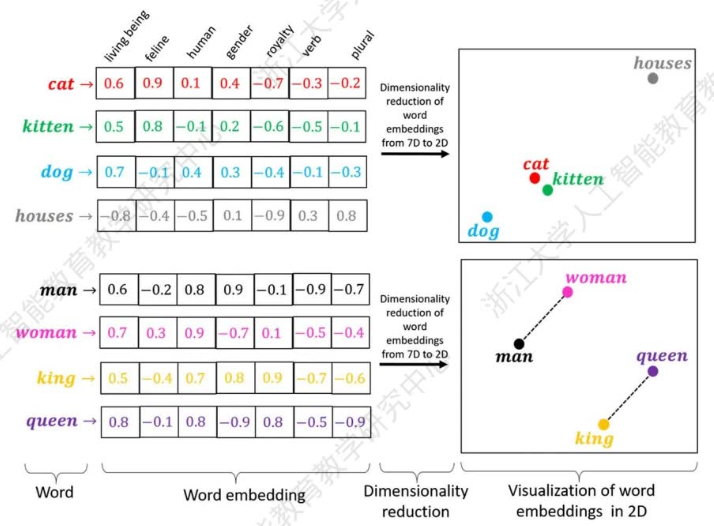
问题1:指示代词“它”,在上下文中可能是不同含义。但词向量, 1个词映射成一个词向量,有一个含义。如何避免歧义?
解决:Transformer框架,词向量=单词含义+其他单词含义(上下文),这个向量的值(注意力权重)=多个单词的加权平均值。
表示序列时,同一个元素在不同上下文中的含义不同/多义词/上下文依赖。大语言模型通过 tramsformer 架构解决。注意力机制,为每个单词生成一个上下文相关的词向量,通过注意力权重实现,一个单词的向量值,是结合上下文的单词向量值的加权平均。
问题2:语言如何生成,产生回答?
解决:模型的参数,代表语言的概率分布规律。使模型在特定的上下文中,预测出最合适(概率最大) 的词。
参数值的确定:
- 预训练。自监督学习,完型填充。句子中挖去一个词,预测这个词。一辆车 (缓慢的)行使在崎岖的路上,预测缓慢。
- 指令微调。给模型明确的任务指令。训练数据多是少量高质量样本,包含用户输入的提示词(prompt)及其对应的理想输出(response)结果
- 指令模型外,有推理模型,多步骤,常用于复杂验证。方式有模型蒸馏。
- 按准确度,反馈评估,奖励强化。
大语言模型通过预训练和微调,提高模型的量化能力。传统是规则化的数据库和信息检索。但大语言模型基于前面的话,在可能的词汇中,选择概率最大的,生成下一个词汇,直到回答完毕。大模型参数包含数据的分布规律,即知识。deepseek v3 671B模型,指的 Billion 十亿
计算机优势:DeepSeek-V3模型的训练语料库包含14.8万亿词元(Token)。若让一个人每秒读1个词,需要47万年才能读完,相当于从智人走出非洲开始昼夜不停读到今天。