data-structure-and-algorithms
- 数据结构是数据容器;
- 算法是操作数据的一组方法,作用于特定的数据结构
- 数据结构,封装算法细节,使算法更有结构
代码评价指标:
- 算法性能-增效-快:数据结构效率够高,算法是不是够优化
- 资源消耗-降本-省:内存够节省
复杂度分析
代码复杂的原因
- 不确定性,异常
- 资源消耗:时间,CPU,存储,IO
因此,有效代码的复杂度不能超过某个阈值
O(f(n)):数据量 n ↑,运行代码的行数 f(n) ↑ 的趋势,O order,表示量级。不是真实的数值,而是一个趋势
设,每行代码执行时间相同,则要使算法效率↑,则需要 代码执行时间 ↓ =a*每行代码执行次数 ↓ = b* maxNum(for ↓ ) (a,b>0,代表正比例)
指标优势:不依赖 软硬件性能、数据规模,来估算算法效率
特性:
- 只关注最内侧循环中的代码执行次数;同级循环相加;嵌套循环相乘;
- 低阶、常量和系数 不左右增长趋势,可以忽略 O(f(n)) + O(g(n))=max(O(f(n)),O(g(n))) O(f(n)) * O(g(n))=O( f(n) * g(n) )
时间复杂度函数
- 常量 1:算法中不存在循环,递归语句
- 对数 logn:
=n - 线性 n
- 线性对数 nlogn
- 组合 m+n m*n:for m{} for n{} 两个规模的数据
- 平方
;立方 ;k次方 - 指数
- 阶乘 n!
查找 a[n] 中存在i
- 最好复杂度:第一个元素就找到
- 最坏复杂度:最后一个元素才找到
- 平均复杂度:有n+1中情况,数组a[n]中某个位置或者不在数组中,sum(num(需要遍历的元素)) =
,考虑到每个元素出现的概率
均摊复杂度
递归
- 递推公式
- 递归树
空间复杂度:数据存储空间之外,需要的操作空间
大纲
物理存储方式:同类型批量存储,内存空间连续/不连续,空间连续是数组,空间不连续是链表。数据只有这两种物理存储方式
逻辑存储方式:
- 线性表:只有前后两个方向,如数组、链表、栈、队列;
- 非线性表:二叉树、堆、图
访问方式:通过地址访问
基本操作:增删改查
- 查找
- 按值查找
- 按下标查找
- 删除
- 按值删除 O(n),先查后删
- 按 数组下标/链表指针 删除;数组O(1),双向链表O(1)
哨兵使用:链表插入删除,字符串处理如KMP模式匹配,二叉树遍历,插入/归并排序,动态规划
由来,特性,解决的问题,使用场景
- 数组 ★、链表;栈,队列 ★
- 数组:索引访问、批量数据处理
- 链表:LinkedHashMap LRU
- 栈:递归、回溯、函数调用、撤销,如表达式匹配
- 队列:线程池中的有界队列、广度优先搜索
- 递归
- 斐波那契数列,阶乘;归并排序,快速排序,二叉树遍历求高度,回溯八皇后,背包
- 排序 、二分查找(前提,有序) ★
- 哈希表
- 拉链法解决冲突的散列表
- 如果循环是为了查找特定元素,那么使用 HashMap ★
- 二叉树
- 遍历;按层遍历,求高度
- 红黑树,平衡二叉查找树
- 堆(完全二叉树)和堆排序 ★
- 优先级队列,Top K,中位数
- 字符串:BF/RK(看懂)字符串匹配算法、Trie树
- 图
- 概念和表示方法:邻接矩阵,邻接表,逆邻接表;
- 图的遍历和搜索:广度-递归、深度-队列
- 算法思想:贪心、分治、回溯、动态规划
- BM、KMP、AC自动机;Hash算法(开阔思路)
- 跳表(看懂),B+树(看懂),红黑树(看懂)
- 拓扑排序、Dijksra 算法、A*算法(知道),位图(看懂,或实现一个位图结构)
数据结构
数组 链表
| 数组 | 链表 | |
|---|---|---|
| 内存空间连续(固定) | Y 内存连续,相同数据类型; - ∈ 线性表,只有前后两个方向 - 按下标寻址,随机访问 O(1) 寻址公式 a[i]=base_address(首地址)+i(偏移量/下标)*data_type_size(数组中每个元素大小)- 为保证内存连续,增删慢 O(n),依次移动值 -- 改进: --- 无序增(新增元素放最后★) --- 标记删(JVM标记清除★,无内存时删) |
N 节点=数据+指针(空间换时间)。 指针指向下一个节点地址,按指针分类: - 单链表:tail.next=null -- 增删 O(1):abXc->abdc aXbXc->ac -- 查 O(n):遍历节点,直到找到 - 双向链表(常用):pre,next -- pre即前驱节点,便于前置插入,删除此节点,有序时向前向后查找 -- 常见容器:LinkedHashMap - 循环链表:last.next = sentinel -- 用于处理循环结构 头尾节点特殊: - 头节点记录链表基地址,可遍历得到整个链表; - 尾节点指向null; - 哨兵简化头尾节点的特殊处理(减少分支判断) |
| 异常 null | ArrayIndexOutOfBounds 访问越界 | 指针丢失的原因:插入顺序;单链表:1 :p(2:new_node)3:new_node.next=p.next; p.next=new_node; 内存泄漏(C++):删除节点后,手动释放空间 边界条件:0/1/2/头尾 |
| 替代 | - ArrayList:封装操作细节,动态扩容;创建时最好指定数组大小★,因为涉及内存申请和数据迁移,比较耗时 - 数组优势:更直观,支持基本类型 |
|
| VS | 插入删除O(n) 随机访问O(1); 连续存储可利用[CPU缓存机制],预读[数组]中的数据,访问效率更高; 预分配数组值不好确定,copy 耗时如1G |
插入删除O(1) 随机访问O(n); 链表消耗额外存储空间,频繁的内存申请和释放导致频繁的 GC |
链表
- LRU latest recently used ★:DoubleLinkedList + HashMap<数据值,链表节点>
- 访问/操作时,
- 链表已存在数据:移动到表头
- 链表不存在数据:
- 容量达上限后:删表尾,删HashMap
- 放表头,增HashMap
- HashMap,快读查数据O(1)
- 访问/操作时,
- 单链表(删,两个指针:pre cur;反转 pre cur next;环 fast slow ★;倒数第N个节点fast slow;中间节点 fast slow)
- 两个有序链表合并 cur1 cur2 mergeHead mergeCur
- 判断一个字符串是回文串,如果字符串是单链表存储?时空复杂度是多少?
链表反转:
ListNode cur=pre.next,next=null;
for (int i = left; i < right; i++) {
// 目标:反转一个元素的箭头指向。这个实现过程需改变3个箭头指向
// print(node.next);
next=cur.next;
cur.next=next.next;
next.next=pre.next;
// System.out.println(cur.val+ " "+pre.next.val);
pre.next=next;
// print(node.next);
}
栈 队列
| 栈 | 队列 | |
|---|---|---|
| 进出(操作受限) 操作受限优势:暴露接口少,有天然的约束保障 |
1端开放, 节点先进后出 push pop,复杂度O(1) |
排队,节点先进(尾)先出(头);队尾加元素,队头删元素 数组:head , tail , count , items[capacity]; - 队空,head=tail;队满,count=items.len 链表:head 哨兵, tail, size, Node(elem,next) - 队空,head.next=null; |
| 应用 | 分类: 顺序栈 链式栈 适用:函数调用、 表达式 ★ 求值、 检查表达式中的括号匹配、 浏览器前进后退 ★ |
分类: 循环:如db 环形事务缓存 阻塞★(队空队满阻塞):生产者消费者模型 并发★(多个线程同时操作数据的安全问题:CAS 或者加锁) 适用:资源有限场景 ★:数组队列,请求排队,超长拒绝 |
栈
- 表达式求值
- 数字栈,运算符栈
- 数字压栈,操作符比大小,
- 比栈顶高,入栈
- 比栈顶低,取出栈中的两个数字和运算符计算后,结果入数字栈;继续比较操作符
- 表达式中的括号匹配:栈保存左括号
- 浏览器前进后退
- 两个栈 A B,首次访问进A;
- 后退,从A进B;前进,从B进A
JVM中的栈是线程私有的,数据结构更复杂,如帧,局部变量表和操作数栈,专用于方法调用和执行上下文。
池结构或场景,用到队列的排队请求:请求、任务、连接、消息和缓存 的管理
- 线程池:web 服务器,数据库、网络连接池,并发编程,
- 消息队列
- 缓存池:内存缓存,分布式缓存
- 文件上传:web 应用确保用户上传的顺序,批处理
无锁并发队列,数组预分配空间:https://blog.csdn.net/crazymakercircle/article/details/128292839
散列表 Hash算法
散列表
- 散列函数
- 冲突解决:链表法,开放寻址 √
- 动态扩容
- 位图
扩展于 数组支持用<下标>随机访问的特性 。使用散列函数 hash func,将编号key 映射成数组table index
Hash函数设计
- 结果值是非负整数
- if key1=key2,then hash(key1)=hash(key2);
- if key1!=key2,then hash(key1)!=hash(key2)
- 散列冲突
Hash冲突
- 开放寻址 open addressing:重新探测一个空闲位置
- 线性探测 linear probing:向后一直找,直到找到;删除时,标记del,遇到 del 的空间,继续探测
- 数据量大时,冲突概率大,探测时间久
- 二次探测 quadratic probing:探测步长,是探测次数的平方 hash(key)+1^2,hash(key)+2^2,hash(key)+探测次数^2
- 双重散列 double hashing:用一组散列函数,冲突换下一个散列函数
- 不管用哪种散列方法,空闲位置少时,散列冲突概率大↑。要尽可能保证散列表有一定比例的空闲空间↓,用装载因子 load factor 表示空位的数量↑=元素个数↑/长度
- 线性探测 linear probing:向后一直找,直到找到;删除时,标记del,遇到 del 的空间,继续探测
- 链表 chaining√:一个节点下一个链表,散列值相同的元素放在链表中;删除时遍历链表删除;查删的时间复杂度O(k),k 是链表长度,理论上,k=n/m,n 散列中数据的个数,m 散列表节点个数
运动会上,运动员参赛编号
- 散列函数:取手机号后4位作为散列值(数据分析法)
word 文档中的单词拼写检查,常用的英文单词个数=20w,设单词平均长度10个字母,平均1个单词占10byte 内存空间,则 20w 单词占 2M空间,可以用散列表存在内存中 - 用户输入单词时,去散列表中查,查到说明拼写正确
- 散列函数:散列值=单词每个字母的 ASCII 值 进位相加%散列表长度
有10w条 URL 访问日志,如何按访问次数给URL排序?
有两个字符串数组,每个数组10w条字符串,如何快速找出两个数组中相同的字符串?
工业级散列表-动态扩容
- 避免散列表中链表长度过长,退化成链表。系统无法响应请求,造成 服务攻击 Dos ,即散列碰撞攻击
- 散列函数:尽可能散列后的值随机均匀分布,不能太复杂
- 装载因子阈值,动态扩容策略:申请新空间,数据搬移到新空间。装载因子0.8,申请2倍空间,则扩容后,装载因子下降到0.4。搬移前,用散列函数重新计算数据位置
- 时间复杂度:最好,不需要扩容,O(1);最坏,O(n)
- 如果内存空间大,执行效率要求高,则降低负载因子阈值,相反,增加阈值,甚至可以>1
- 渐进式扩容:新数据插入时扩容,新数据放新散列表,并且从老散列表中取1个数据放新散列表;查询时,先从新散列表中查,没有则查老表
- 散列冲突
- 优先用链表法。也可以将链表改成其他结构,如红黑树,避免O(n)查询;LinkedHashMap
- 适合存储大对象,大数据量;更灵活,有支持更多的数据结构
- 小规模数据装载因子不高,可用开放寻址 ThreadLocalMap
- 优:1. 存放数组,有效利用 CPU 缓存 2. 无指针,序列化简单
- 缺:1. 删数据麻烦,标记删除 2. 所有数据在一个数组中,冲突概率大,因此,装载因子阈值要小,内存空间需求大
HashMap
- 优先用链表法。也可以将链表改成其他结构,如红黑树,避免O(n)查询;LinkedHashMap
- 初始大小:16,可配置。
- 装载因子,动态扩容:0.75,元素个数> 0.75xcapacity 则扩容,扩容为原来的2倍
- 散列冲突:链表法。JDK1.8 ,链表长度>8,<-> 转成红黑树
- 散列函数:用对象HashCode,比如String 有自己的HashCode
散列表和链表
散列表,高效操作但无序;链表可以保持顺序
- LRU缓存淘汰:散列表查找
- 跳表:用户积分排行榜 key:user ,score:积分;新增散列表<key,value>,查找成 O(1)
- LinkedHashMap:双向链表+散列表,按插入、访问顺序遍历数据;put时,插入链表尾部;重复插入 移链尾;访问后 移链尾。即,LinkedHashMap 本身是一个 LRU缓存淘汰容器
Hash算法
- 任意长度的二进制串,映射成固定长度的二进制串。结果值就是Hash值
要求 - 单向,不能反向推导
- 输入数据敏感,只修改1bit,Hash值也完全不同
- Hash 冲突概率小
- 执行效率高
应用 - 安全加密:MD5 message-digest algorithm 消息摘要算法;SHA secure hash algorithm 安全散列算法,DES,AES
- 唯一标识:图片的二进制取前100byte,中间取100byte,最后取100byte,计算得出Hash值,用于查找图片
- 数据校验:BT下载,网络传输不安全,可能文件错误、文件丢失。使用100个文件块取Hash值,保存则种子文件中,下载完成比对失败,需重新下载
- 散列函数:简单,不要求 反向解密,关注值均匀分布
存储 10w 个用户的ID及积分信息,支持,1. 根据id 快速查找、删除、更新积分 2. 查找积分在某个区间的猎头ID列表 3. 按积分小到大,查排名在第 x 位到y位间的猎头ID列表
- Hash:使用
HSET命令将用户的 ID 和积分存储在一个哈希表中,便于快速查找、删除和更新积分。 - Sorted Set:使用
ZADD命令将用户的积分和 ID 存储在一个有序集合中,以便快速查找积分在某个区间的用户列表和按积分排名查询。- key, score1 member1:按 score 分层存储。1. 目标节点大,移动到下一节点;2. 目标节点小或相等,或到达链表末尾,记录当前节点和下一节点位置,移动到下一层;3. 重复前2步,直到达到最底层
# 除最底层外,待插入数据所在层面
def generate_level(max_level, p=0.5):
level = 0
# <概率,则增加层数
while random.random() < p and level < max_level:
level += 1
return level
// del user
jedis.hdel(USER_HASH_KEY, userId);
jedis.zrem(USER_SCORE_KEY, userId);
// update score
jedis.hset(USER_HASH_KEY, userId, String.valueOf(newScore));
jedis.zadd(USER_SCORE_KEY, newScore, userId);
// select users where score in [minScore, maxScore]
jedis.zrangebyscore(USER_SCORE_KEY, minScore, maxScore);
// sort:score form small to big, select users where user in [start, end]
jedis.zrange(USER_SCORE_KEY, start, end);
分布式应用
- 负载均衡:同一个客户端,一次会话中的所有请求路由到同一个服务器:路由到的服务器编号=hash(客户端IP+会话ID)%服务器个数
- 数据分片:
- 1T的日志文件,统计多个"搜索关键词"出现的次数:数据分片,n台机器并行处理部分。1个关键词分配到一个机器上,机器编号=hash(日志中的关键词)/机器台数n;每个机器分别计算关键词出现的次数。合并最终结果
- 1亿张图片,构建散列表需要的机器数:散列表=hash+图片路径,hash 用md5=128bit=16byte;图片路径上限=256byte,设平均长度128byte;链表法解决冲突,存储指针 8byte。因此,散列表需152 byte。设一台机器内存2g,装载因子0.75,则图片个数=2gx0.75/152byte=1kw张,1亿张/1kw张=10台机器
- 分布式存储:1. 存储机器编号 2. 扩容,所有机器重新计算存储机器,则缓存失效,造成雪崩,压垮数据库。因此,一致性Hash。k台机器,hash in [0,MAX] 通常m>k,分为m个小区间,则每个机器负责区间个数=m/k,加入1台新机器时,将
个小区间的数据搬到新机器上。虚拟环+虚拟节点
3台机器,12个区间;则每个机器负责区间数=12/3=4个;加一台机器,每个机器负责区间数=12/4=3,则将区间 3, 7, 11 迁移到新节点node4
node1 负责分区 0, 1, 2,3
node2 负责分区 4, 5, 6,7
node3 负责分区 8, 9, 10,11
node4 负责分区 3, 7, 11
其他应用:网络协议 CRC校验;Git commit id
二叉 红黑树
- 二叉树
- 完全二叉树(数组存储)、满二叉树
- 平衡二叉查找树(链表存储,左右二分查找,中序遍历有序)、二叉查找树、平衡二叉树
- AVL
- 红黑√
- 多路查找树
- B
- B+
- 2-3
- 2-3-4
- 堆
- 小顶堆/大顶堆
- 优先级队列
- 斐波那契堆
- 二项堆
- 其他
- 树状数组
- 线段树
树
- 节点、连线表示父子关系:父/子/兄弟 节点,根/叶子 节点
- 节点的深度:根节点到节点的边数, 根 from 0;节点的层数:深度+1,根 from 1;
- 节点的高度:节点到叶子节点的边数 叶子 from 0;树的高度:根节点的高度
二叉树
- 一个节点最多两个子节点
- 满二叉树:叶子节点都在最底层,除叶子节点,每个节点都有左右两个子节点(所有层都满)
- 完全二叉树:满二叉树是其中一个特例;叶子节点在最底下2层,最后一层叶子节点靠左排;除了最后一层,其他层的节点个数达最大(只最后一层不满,最后一层满的都是左侧+只最右侧可以是单节点)
- 定义由来,1. 链式存储, data, left, right;2. 数组存储,顺序数组:根节点 i=1(下标0空闲);当前节点的左子节点2i,右子节点 2i+1;反推,已知子节点 i,父节点 i/2。如果是非完全二叉树,浪费空间;如果是完全二叉树,则不需存储指针,通过下标可找到子节点
- 堆是完全二叉树,存储方式是数组
二叉树遍历:print r 在前,中,后;递归,要解决问题A,则解决子问题B、C,假设B、C已解决
- 前序:中左右 preOrder(r)=
- 中序:左中右 inOrder(r)=
- 后序:左右中 postOrder(r)=
- 时间复杂度 O(n):每个节点最多访问2次,所以,复杂度与节点个数n 成正比
二叉查找树 Binary search tree,快速 增删改查
要求:树中,左子节点值<父节点<右子节点值
查找:while p!=null
- <根,左节点
-
根,右节点
- return 根
- end while, return null
插入:查找,[要插入的数据]大并且右子树为空,则插入;[要插入的数据]小并且左子树为空,则插入 - 插入节点一般是叶子节点,特殊的如平衡二叉查找树有一个平衡高度的过程
删除: - 标记删除,占内存但操作简单
- 立即删除:(找个节点,替换删除节点)
- 删除节点没有子节点:删除节点=null
- 删除节点有1个子节点:父节点指向子节点
- 1个子节点,而不是1个不是子树,即子节点没有子节点
- 删除节点有2个子节点:查删除节点右子树的最小节点(更靠近根节点),移到删除节点。即最小节点替换删除节点,并删除最小节点。
快速查找:最大(遍历右节点,直到空)、最小、前驱、后继 节点
中序遍历,可输出有序数据,时间复杂度 O(n)
重复数据:用对象的某个字段作为key,构建二叉查找树,则元素相同时:
- 插入时,∃相同值,当作大值,放入右子树;
- 查找时,∃相同值,继续查找右子树,直到遇见叶子节点。这样能查出值相同的所有节点
- 删除时,查所有要删除的节点,依次删除
时间复杂度: - 好:完全二叉树,和树的高度成正比,则求1棵含n个节点的完全二叉树高度?高度=层数-1;
- 1st 层1个节点,2st 层 2个节点,3st 层 3个节点,k st 层节点个数=
- 完全二叉树最后一层,节点个数∈
,L是最大层; - 节点和∈
,则高度最大为
- 1st 层1个节点,2st 层 2个节点,3st 层 3个节点,k st 层节点个数=
- 坏:链表 O(n)
- 需要构建 平衡二叉查找树,时间复杂度O(logn)
散列表 O(1),二叉查找树
- 散列表无序存储
- 散列表扩容耗时↑
- hash 冲突,导致散列表 操作时间复杂度可能> O(logn)
- 散列表构造比二叉树复杂,需考虑散列函数,hash 冲突,扩容,缩容
- 散列表装载因子小会浪费空间
平衡二叉查找树:避免二叉查找树最坏复杂度
左右子树高度差<=1,高度
初衷:解决二叉树退化成链表的问题。平衡指,左右子树高度差尽量小 。红黑树维护成本低,操作性能稳定,高度大约是
红黑树 read black tree√:最常用的不严格的平衡二叉查找树。
不严格指的是,不满足高度差<=1,但高度稳定的趋近
- 根黑;叶子黑且数据=null
- 红色节点的子节点必须黑
- 因此,红黑树中,红色节点数<黑色节点数
- 当前节点,到叶子节点的所有路径中,黑色节点数目相同
红黑树高度
- 去红色节点,其高度:
- 去红色节点时,祖父节点作为父节点,变成四叉树
- 由红黑树的定义3,则从四叉树中取出某些节点(如4个节点取出2个节点),放在叶节点位置后,四叉树变成完全二叉树;因此只含黑节点的四叉树高度<完全二叉树(高度
) - 放回红色节点,由红黑树的定义2,高度<
红黑树实现难度较高,多用跳表替代
二叉查找树插入时不需要调整父子节点,所以,一般插入到叶子节点。如果调整父子节点,是因为要保持树的高度平衡,如平衡二叉查找树。
完全二叉树,插入后要调整父子节点,因为数组存储,新节点总是被插入到数组的末尾,需要向上调整父子关系,确保仍满足完全二叉树,即数组存储时,根节点 i=1(下标0空闲);当前节点的左子节点2i,右子节点 2i+1;反推,已知子节点 i,父节点 i/2。
堆 堆排序
堆
- 完全二叉树
- 值>=/<=子值,顶值最大叫 大顶,顶值最小叫 小顶
堆存储:数组 - 插入:
- 堆化:放在数组最后(下->上),顺着节点所在路径,比较不满足父子关系(大顶)则交换 while(i/2>0 && a[i]>a[i/2])
- 删除顶:数组最后一个节点替换堆顶(上->下),堆化
- 替换包含,swap(数组第一个节点,数组最后一个节点),then del 数组最后一个节点
- 复杂度:顺着节点所在路径比较交换,则堆化的时间复杂度和树的高度h 成正比,即 O(logn)
堆排序
评价:原地不稳定,时间复杂度 O(nlogn),
实现: - 原地建堆:
- 后->前,上->下,从第一个非叶子节点 idx=
开始堆化 - 叶子节点
;非叶子节点
- 叶子节点
- 时间复杂度:
,公式* 2,错位相减,得 ,又 ,则 O(n)
- 后->前,上->下,从第一个非叶子节点 idx=
- 排序
- 堆顶元素最大,与末尾(非置底元素)元素交换(堆顶元素置底),堆化,直到堆中只剩1个元素
- 堆排序时间复杂度 O(nlogn)
堆排序和快速排序:时间复杂度比快排更稳定,但实际中快排性能好 - 快速排序,顺序访问;堆排序,跳跃访问,CPU缓存不友好
- 快速排序的交换次数<堆排序。堆排序维护结构需要多次的比较和交换
https://www.hello-algo.com/chapter_heap/heap/
应用
优先级队列:队列先进先出,优先级队列按优先级先出
- 应用:赫夫曼编码、图的最短路径、最小生成树算法、PriorityQueue
- 合并有序小文件:100个文件,每个文件100M,存储有序字符串。将100个小文件合并成一个有序的大文件
- 类似归并排序的合并函数:100个文件各取第1个字符串,放入数组,比较大小,把最小的字符串放入合并后的大文件,并从数组中删除。可以数组换成小顶堆,在取最小字符串时,可以避免循环遍历数组。小顶堆中,堆顶元素是最小的元素。删除堆顶元素和向堆中插入元素的复杂度是O(logn),n表示堆中数据个数
- 定时器:定时任务列表维护触发时间,需遍历列表执行任务,遍历低效,换成优先级队列
- 按任务时间,将任务存在优先级队列(小顶堆,最先执行的任务)中。取堆顶任务获取当前时间的时间差T,则设置定时器T s之后,移除堆顶任务执行,计算新的队首任务执行时间,与当前时间的差值,将差值设置为下一次定时任务需执行的时间。如果是重复执行的任务,更新下次执行时间,将任务插入堆中。删除或插入元素后,需堆化。如果任务重复,存储同一时间的任务列表
Top K
- 按任务时间,将任务存在优先级队列(小顶堆,最先执行的任务)中。取堆顶任务获取当前时间的时间差T,则设置定时器T s之后,移除堆顶任务执行,计算新的队首任务执行时间,与当前时间的差值,将差值设置为下一次定时任务需执行的时间。如果是重复执行的任务,更新下次执行时间,将任务插入堆中。删除或插入元素后,需堆化。如果任务重复,存储同一时间的任务列表
- 静态数据集:数据量n的数组,查找前K大数据
- 维护1个大小K的小顶堆。遍历数组,比堆顶元素大,替换堆顶元素,堆化。
- 遍历数组 O(n),一次堆化O(logK),最坏情况,O(nlogK)
- 动态数据集:两个操作 1. add data 2. 查前K大数据
- 维护1个大小K的小顶堆,添加元素时,与堆顶比较,比堆顶大,替换堆顶;比堆顶小,不做处理
- 搜索引擎 Top K:10y 个搜索关键词的日志文件,获取 Top10
- 方法1:MapReduce
- 限制条件:单机,内存1GB,则方法为:
- 因为搜索关键词多重复,因此统计关键词频率,用散列表、平衡二叉查找树等支持快速查找、插入的数据结构。如,遍历这10y个关键词,用散列表存储<关键词,频率>
- 用堆求Top K,维护大小10的小顶堆,遍历散列表,取频率与堆顶关键词的次数进行比较,遍历完散列表后,小顶堆就构建起来了。
- 设每个关键词平常长度50 byte,设1y 不重复数据,则需5G内存>1G内存,无法一次加载到内存,则需要
- 哈希算法,相同数据生成Hash值一致。将10y 关键词分到10个文件。遍历10y 数据,取Hash值 floorMod 10,结果作为文件编号。则一个文件只有亿个关键词,去掉重复后设有1000w个关键词,则一个文件需内存500M=1000w非重复 * 50byte
- 分别做10个堆,10个堆中的100个数据取top10
动态集合中的中位数
- 有序升序数组,数据个数是奇数,第
个是中位数;数据个数是偶数,第 个是中位数; - 动态数据结构,维护两个堆,1个大顶堆(小值)存前半部分(奇数第
个,偶数第 个)数据,1个小顶堆(大值)存后半部分数据。大顶堆堆顶就是中位数 - 加入数据,<=大顶堆堆顶,插入大顶堆。>=小顶堆堆顶,插入小顶堆。当2个堆中的数据个数不满足前半部分,后半部分均分时,从一个堆中连续将堆顶元素移动到另一个堆中(两个堆的堆顶元素数值相近),使满足 大顶堆存前半部分
- 插入需堆化, O(logn);查找堆顶 O(1)
- 接口 99% 响应时间。100个数据,99百分位数就是99,即 <=99的数占总个数的 99%。
- n 个数据,小->大顺序,99% 指 第 n* 0.99 个数据
- 维护两个堆,1个大顶堆(小值)存 n* 0.99 个数据,1个小顶堆(大值)存 n* 0.01 个 数据。大顶堆的堆顶就是结果值
图 广深优先搜索
图
- 存储
- 邻接矩阵
- 邻接表
- 拓扑排序
- 最短路径
- 关键路径
- 最小生成树
- 二分图
- 最大流
图
- 顶点;边;度:顶点的边数;有向图,分入度(指入),出度(指出);带权图,权重 weight;
- 度,关注好友;权重,关系亲密度
存储
- 度,关注好友;权重,关系亲密度
- 邻接矩阵:二维数组。有向无向图,值存度;带权图,值存权重;0表示没关系
- 浪费空间:
- 无向图
a[i][j]=a[j][i]只需存储一个,按对角线划分,浪费1/2空间 - 稀疏图,顶点多边少
- 无向图
- 存储简单,直接获取顶点关系。便于转成矩阵计算
- 浪费空间:
- 邻接表:一维Array+LinkedList,链表存此节点指出的顶点
- 省空间,耗时间。遍历链表。链表可改成平衡二叉查找树,跳表,散列表,有序动态数组
存储微博社交网络的好友关系
操作:(判断)A关注→B,则A是粉丝;分页获取A的关注列表、粉丝列表,按用户名称首字母排序
- 省空间,耗时间。遍历链表。链表可改成平衡二叉查找树,跳表,散列表,有序动态数组
- 1个邻接表,查关注;1个逆邻接表(链表存指入),查被关注
- 跳表替换链表,支持快速增删改查,时间复杂度O(logn),空间复杂度O(n)。跳表中存储的数据本来就是有序的(小到大,数值或字典序),便于分页查找
- 上亿用户
- 方法1:Hash分到不同机器。机器1存 顶点1,2,3的邻接表。机器2存4,5的邻接表。查顶点间关系时,Hash定位机器,在机器上查
- 方法2:外部存储,如硬盘上的数据库,联合索引<userId,followId>
深度和广度优先搜索
- 广度队列;深度栈
- 一个顶点到另一个顶点的路径。
- 回溯,结果不是最短路径
以邻接表存图,无向图为例:
广度 breadth first search:地毯式搜索,先找离顶点最近的,再是次近的,依次向外。 - 复杂度:
- 时间:最坏,遍历整个图,每个顶点进出1遍队列,每个边被访问1次,∴ O(V+E),E是边个数,V是顶点个数。
- 对于1个连通图(图上所有顶点联通),E>=V-1,∴ 可以简写成O(E)
- 空间:visited[w],pre[w],queue。三个的存储空间不超过顶点个数,∴ O(V),V是顶点个数
- visited[w]:记录已经被访问的顶点,避免重复访问。visited[w]=true,则w顶点已经被访问过
- pre[w]:顶点w 从哪个前驱顶点遍历过来的,从后向前的反向路径。pre[3]=2,从顶点2访问到顶点3
- queue:已访问节点(不含)的下层(相邻)待访问节点。记录k层的顶点,便于找k+1层。
BFS(graph, start):
visited = set() // 创建一个集合,用于存储已访问过的节点
queue = Queue() // 创建一个队列,用于存储待访问的节点
enqueue(queue, start) // 将起始节点加入队列
add visited, start // 将起始节点标记为已访问
while queue is not empty:
vertex = dequeue(queue) // 从队列中取出一个节点
visit(vertex) // 访问该节点
for neighbor in graph.neighbors(vertex): // 遍历该节点的所有邻居
if neighbor not in visited:
add visited, neighbor // 标记邻居节点为已访问
enqueue(queue, neighbor) // 将未访问的邻居节点加入队列
queue 是一个队列,用于维护待访问的节点,并保持先进先出(FIFO)的顺序。
enqueue(queue, item) 表示将 item 加入到队列 queue 的末尾,而 dequeue(queue) 表示从队列 queue 中移除并返回第一个元素
深度 depth first search:走迷宫,走不通了退回到上个路口,换路,直到找到出口。
- 回溯思想,适合递归解决
- 复杂度:
- 时间:每条边最多被访问2次,1次遍历,1次回退。O(E),E是边个数
- 空间:visited[w],pre[w](存储路径),递归调用栈。栈的最大深度不超过顶点个数,∴ O(V),V是顶点个数
调用 DFS(graph, start) 时,从指定的起始顶点开始,首先标记该顶点为已访问,然后对其每一个未访问的邻居顶点递归调用 DFS 函数,直到图中的所有可达顶点都被访问为止
DFS(graph, start):
visited = set() // 创建一个集合,用于存储已访问过的节点
stack = [] // 使用列表作为栈
push(stack, start) // 将起始节点放入栈中
while stack is not empty:
vertex = pop(stack) // 取出栈顶元素
if vertex not in visited:
visit(vertex) // 访问节点
add visited, vertex // 标记为已访问
for neighbor in graph.neighbors(vertex): // 遍历所有相邻节点
if neighbor not in visited:
push(stack, neighbor) // 如果未访问,则加入栈中,多个邻居加入栈
graph 是表示图的数据结构,可以是邻接表、邻接矩阵等形式
start 是遍历开始的节点
visited 集合用来记录已经访问过的节点,以避免重复访问
stack 是模拟栈操作的列表,用于保存待访问的节点
https://www.hello-algo.com/chapter_graph/graph_traversal/
查找社交网络3度好友关系
- 社交网络用图表示,适合BFS。与用户距离边数为3的顶点,就是用户的3度好友关系
字符串
字符串匹配
- 在A(主串,长度n)中找B(模式串,长度m)。m< n
单模式:在1个串中查找1个串;
BF brute force 暴力匹配
- 从0向后,取模式串长度,比较。找到/结束则停止
- 时间复杂度:最坏,对比 n-m+1次,∴ O(mn)
- 常用,原因:
- n 通常小,则 执行效率通常<O(mn)
- 简单易修复
RK(名字命名),BF升级
- 引入Hash算法。对 n-m+1 个子串分别求Hash值。比较Hash值。因为Hash值是一个数字,比较很快
- Hash算法:设字符串中共有K个字符,可以用K进制表示一个子串,K进制转10进制来表示字符串。这个算法有个特点,相邻两个子串s[i-1],s[i](i表示子串在主串中的起始位置,子串长度为m),则Hash 计算公式间有交集:
- 前一项和后一项的关系:
,同时,26^n 可以通过查表方式获得。 - 时间复杂度:1. 计算子串Hash值,扫描一遍 O(n) 2. 模式串Hash值和子串Hash 值间的比较,比较次数=n-m+1,∴O(n) ;3. 因此,整体复杂度 O(n)
- 如果模式串很长,计算到的Hash值很大。上面Hash算法没有Hash冲突。可以缩小长度,允许Hash冲突,如把字符串每个字母和作为Hash值;因此,当Hash值相同时,再对比下原串。
BM,性能比 KMP好 2~4倍 - 由现象找规律,当不匹配时,一次性跳过肯定不匹配的情况。
- 坏字符串 bad character rule:模式串从左到右滑动,与主串的匹配从模式串的末尾(右到左)匹配;某个字符无法匹配时,叫主串的坏字符。如果模式串不存在此字符,可以直接移动模式串到此字符后面。
- 好后缀 good suffix shift:已匹配的后缀,在模式串中寻找存在第二次,将第二次和主串对齐
- 用好两个规则:分别计算两规则需继续滑动的位数,取大值
KMP(略)
多模式:在1个串中查找多个串
Trie 树,字典树
- 用字符串间的公共前缀,合并重复前缀。根节点不包含信息;每个节点存储一个字符;到叶子节点的一条路径,表示一个字符串;
- 常见操作:1. 将字符串集合构建成 trie 树 2. 在 trie 树中查找一个字符串
- 使用要求高 1. 字符集不能太大 2. 前缀重合比较多 3. 缓存不友好。因此,在工程中,倾向于用红黑树,散列表做动态数据集合的查找
- Trie 树不适用于精确查找匹配,最好的用法是前缀匹配,自动输入补全,如搜索引擎中的搜索关键词提示,输入法自动补全,IDE代码编辑器自动补全,字符串匹配的时间复杂度O(k),k是要匹配的字符串长度
AC 自动机 - 用户敏感词过滤。维护一个敏感词字典,通过字符串匹配,替换成*,可以用AC自动机实现一个高性能的敏感词过滤系统
- 对敏感词字典进行预处理,构建成 Trie树,AC自动机则改进Trie 树,引入 next 数组,当匹配失败时,将模式串继续多滑动几位。
算法
思路
递归
计算机擅长重复,人擅长顺序展开
条件
- 问题可拆成子问题
- 问题与子问题 解法相同,数据不同
- 存在终止条件
解法:
- 递推公式:问题A可以拆解成子问题 b c d ,只思考A和直接子问题两层间的关系即可。假设子问题已解决,思考如何解决问题A,抽象成一个公式解决
- 终止条件
注意:
- 堆栈过深:递归适用于调用深度小的问题。如果必须,则定义全局变量 递归深度,避免堆栈溢出/ 堆上实现一个调用栈,模拟递归压栈出栈,就没有系统栈大小限制
- 重复计算:跳台阶,想计算f5,先计算 f4、f3;想计算 f4,先计算 f3、f2;f3 被重复计算,解决:HasMap.put( n,fn )
- 函数调用保存现场数据,空间复杂度O(n)
- 脏数据易出现环,需检测环的存在
- 日志+ breakpoint
改写成非递归
- 递归简洁,但空间复杂度高,有堆栈溢出风险
- 递归改成循环
// 爬楼梯
public int climbStairs(int n) {
// 特殊情况处理
if (n == 1) return 1; // 从地面到第一级台阶
if (n == 2) return 2; // 从地面到第二级台阶
// 初始化前两个状态(动态规划的简写)
int prev2 = 1; // dp[1] 从地面到第一级台阶
int prev1 = 2; // dp[2] 从地面到第二级台阶
int current = 0;
// 从第3级台阶开始计算
for (int i = 3; i <= n; i++) {
current = prev1 + prev2; // 递推关系
prev2 = prev1; // 更新 prev2
prev1 = current; // 更新 prev1
}
// 返回到达第 n 级台阶的方法数
return current;
}
应用:
- 推荐注册返佣,A推荐B;B推荐C;A是B、C的最终推荐人;给定一个用户,如何查找其最终推荐人?
/**
* actorId:用户ID
* refer_id:推荐人ID
* 改进:添加递归深度;检测环
*/
long findRootReferId (long actorId) {
Long referId=select refer_id from [table] where actor_id=[actor_id];
if referId=null {
return actorId;
}
return findRootReferId(referId);
}
- 跳台阶:n个台阶,一次可以走1个/2个,问,有多少种走法?
- 如果你在第 n 级台阶,那么你有两种爬法1. 从第 n−1级台阶爬 1 级上来 2. 从第 n−2级台阶爬 2 级上来
- 第二级台阶:1. 从地面到第一级台阶,一种方法;从第一级台阶到第二级台阶,一种方法,则总数就是1x1=1;2. 从地面直接爬二级台阶,1种方法;3. 因此,爬到第二级台阶的方法数是两个方法的总和,1+1=2
- 终止条件:0个台阶,只有一种方法,什么都不做(意义不大,舍去);1个台阶,只有一种方法,爬1级;2个台阶:2种方法
- f(n) = f(n-1) + f(n-2); f(1) = 1; f(2) = 2;
- 排序:快速归并
- DFS 深度优先搜索
- 前中后 二叉树遍历
- 全排列:n 个数据的所有排列
- f(1,2,..n)={最后1位=1,f{n-1}} +{最后1位=2,f{n-1}} +..+ {最后1位=n,f{n-1}}
复杂度分析
- 递推公式
- 递归树
递归树:n(h) 和总时间
归并
- 数据拆分一分二,一个数据的消耗的时间是常量1,一层有n个数据,这n个数据都参与归并操作,则一层消耗的时间是n
- 时间复杂度= 高度h * 单层时间 n,又归并构建的是满二叉树,则h=
,∴ 时间复杂度=
快速 - 单层时间n,时间复杂度=hn,
- 设两个分区大小1,n-1。每次分区很不均匀,令n=10,则n-1=9,但快排的数据拆分不是一分二,则h怎么求?
- 快速排序结束时,待排序的小区间,数据个数=1。则从根节点 n 到叶子节点 1,递归树最短的一个路径 每次 * 1/10,最长的一个路径 每次 * 9/10。经过h次递归调用后,数组的大小应该为1
最短路径 h= ; 最长路径 h= ;,统一写成
- ∴ 时间复杂度=
斐波那契 - f(n) = f(n-1)+f(n-2)
- 每次数据量-1或-2;终止条件,叶子节点数量是 2,1;因此,从根节点到叶子节点,每条路径长短不一。如果每次-1,则大约h=n;如果每次-2,大约h=
- 合并时只需1次加法,记一次加法消耗时间为1,则从上层到下层,需时间
- if h=n, 总时间=
;if h= , 总时间= ;
- 每次数据量-1或-2;终止条件,叶子节点数量是 2,1;因此,从根节点到叶子节点,每条路径长短不一。如果每次-1,则大约h=n;如果每次-2,大约h=
- ∴ 时间复杂度是指数级
全排列 - 所有层,f(n), nf(n-1), n(n-1)f(n-2), .. n(n-1)(n-2)..(n-k+1)..n(n-1)(n-2)..2*1,累加和是时间复杂度。
- ∵ last one= n(n-1)(n-2)..2*1=n!,and 前面n-1个数值< last one,则累加和< O(n*n!)
贪心
greedy
设背包容量100KG,装5种单价和容量不同的豆子,怎么装,背包总价值最大?
按照单价由高到低依次来装
| 物品 | 总量kg | 总价值元 |
|---|---|---|
| A | 100 | 100 |
| B | 30 | 90 |
| C | 60 | 120 |
| D | 20 | 80 |
| E | 50 | 75 |
-
一组数据,定义了限制值和期望值,希望从中选出几个数据,满足限制值,期望值最大
- 限制值 <100kg,期望值 max(总价值)
-
当下选择,是限制值相同的条件下,最大期望值数据
- 重量相同条件下,价值最大。可以通过每一步选择单位重量价值最高的物品来实现
-
举例验证结果最优
- 严格证明结果比较复杂;大部分用贪心解决的问题,正确性是显然成立的
贪心的答案,不一定是最优解;原因:前面的选择影响后面的选择
- 严格证明结果比较复杂;大部分用贪心解决的问题,正确性是显然成立的
-
分糖果:m个大小不等的糖果分给n个孩子,m<n,如何分配?转为,从n个孩子中,抽取一部分孩子分配糖果,让每个孩子的满意度最大
- 基于,对一个孩子来说,如果小的糖果可以满足,则将更大的糖果留给需求更大的孩子;
- 只要满足,不管是满足一个需求大的孩子,还是满足一个需求小的孩子,对期望值的贡献是一样的
- 每次从剩下的孩子中,找出对糖果需求最小的,发给满足他最小需求的糖果,这样的分配方案是满足孩子个数最多的方案
- 钱币找零:支付K元,有面值1元、5元、10元、50元,100元的纸币,张数分别是 c1、c2、c3、c4、c5,最少用多少张纸币?
- 按照面额由高到低依次支付。 直觉告诉我们,在贡献相同期望值的情况下,希望多贡献点金额,让纸币数量更少
- 区间覆盖:假设有N个区间,分别是[l1,r1], [l2,r2]...[ln,rn],选出部分区间,满足两两不相交(端点相交不算),最多能选出多少个区间?
- 这用于 任务调度,教师排课
- 解决:设最左端是lmin,最右端是rmax。问题转为,选择几个不相交的区间,从左到右将 [lmin,rmax]覆盖上。 按起始端点从小到大的顺序对n个区间排序。每次选择的是,左端点和已覆盖区间不重合,右端点尽量小的。让剩下的未覆盖区间尽可能大,就可以放置更多空间
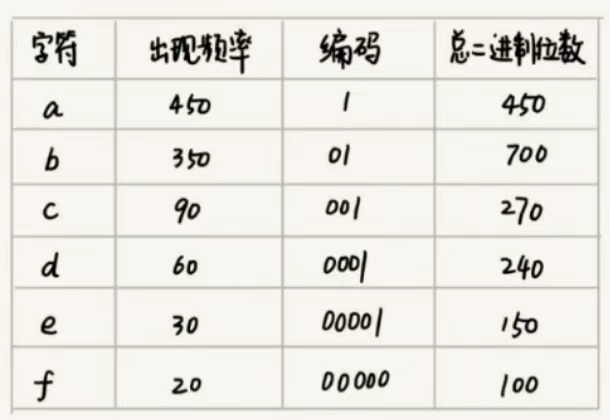
- 霍夫曼编码:文件1k字符,每个字符1byte=8bits,存储需要8kbits,找更节省空间的存储方式
- 设,统计发现,1k字符,只有6种字符。3bit可以区分出8个不同的字符;因此每个字符可以用3bit表示,1k个字符只需要3k bit
- 更省空间的存储方式。霍夫曼编码压缩数据,节省存储空间。压缩率在 20%~90%间,会考察文本中多少个字符,每个字符出现的频率,根据频率不同,选择不同长度的编码;试图用不等长的编码方法进一步压缩。使用贪心算法,频率高的字符用短编码
- 解码:不等长编码为避免歧义,要求字符的编码之间,不会出现某个编码是另一个编码前缀的情况。解压时,每次读取最长的可解压二进制串
- 编码:根据出现频率不同,给不同字符不同长度的编码:每个字符看作一个节点,字符的频率放到优先级队列中, 队列中取出频率最小的两个节点A、B,新建一个节点C=A+B,作为 A、B的父节点(树)。把C放入优先级队列中,重复,直到队列中没有数据。给结果树的边加权重,左子节点边=0,右子节点边=1,则从根到叶的路径,就是叶节点对应字符的霍夫曼编码。
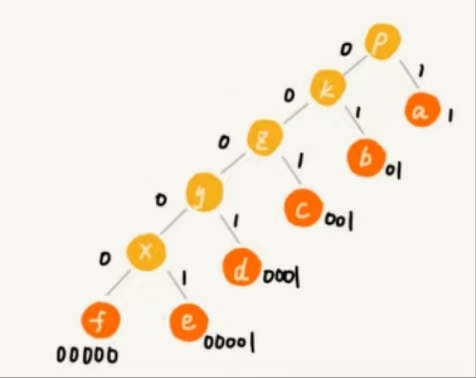
Huffman_Encoding(frequencies):
priority_queue = PriorityQueue() // 创建一个优先级队列,按照频率排序
// 将所有字符及其频率作为叶节点加入优先级队列
for each character, frequency in frequencies:
node = Node(character, frequency)
enqueue(priority_queue, node)
// 循环直到优先级队列中只剩下一个节点
while size(priority_queue) > 1:
left = dequeue(priority_queue) // 取出频率最小的节点作为左子节点
right = dequeue(priority_queue) // 取出下一个频率最小的节点作为右子节点
// 创建一个新的内部节点,其频率等于两个子节点频率之和
new_node = Node('*', left.frequency + right.frequency)
new_node.left = left
new_node.right = right
enqueue(priority_queue, new_node) // 将新节点加入优先级队列
// 队列中剩下的节点即为霍夫曼树的根节点
root = dequeue(priority_queue)
// 使用深度优先搜索来构建霍夫曼编码
huffman_code = {}
DFS_Build_Code(root, "")
return huffman_code
// 深度优先搜索构建霍夫曼编码
DFS_Build_Code(node, code):
if node is a leaf:
huffman_code[node.character] = code // 如果是叶节点,则保存编码
else:
// 否则递归地对左右子节点进行编码,左子节点添加'0',右子节点添加'1'
DFS_Build_Code(node.left, code + "0")
DFS_Build_Code(node.right, code + "1")
更多应用 ,Prim 和 Kruskal 最小生成树算法,Dijkstra 单源最短路径
分治
MapReduce 的本质是分治。Google MapReduce 在倒排索引,PageRank 计算和网页分析等搜索引擎技术上有大量应用
- 数据间有关系:统计文件中单词出现的频率
- 数据间没关系:网页爬取,清洗,分析,分词,计算权重,倒排索引的任务调度
devide and conquer:大问题化成相同解法的小问题,递归解决问题再合并,每层递归都涉及:
- 分解:原问题划为子问题
- 解决:递归求解子问题;当子问题足够小,直接求解
- 合并:结果合并
分治算法问题满足: - 原问题可以分成相同算法的子问题
- 子问题独立求解,子问题间没有相关性
- 分解有终止条件,问题足够小时直接求解
- 结果合并的复杂度不能太高,否则无法减少算法的总体复杂度
应用: - 指导编码,降低问题的复杂度
- 求一组数据的有序对个数或逆序对个数。设n个数据,小到大有序,其有序度=
,逆序度=0 - 从 n个不同元素中选取 2 个元素的组合数,记作 C(n,2)=
- 分治法求数组A的逆序对个数。数组拆成2个小数组A1,A2,分别计算逆序对个数K1,K2;再计算A1与A2间的逆序对个数(归并排序,合并时计算逆序对个数),则总的逆序对个数=K1+K2+K3。
- 从 n个不同元素中选取 2 个元素的组合数,记作 C(n,2)=
- 二维平面上有n个点,如何快速计算出两个距离最近的点对?
- 有2个nxn矩阵,如何快速求解2个矩阵的乘积 C=AxB
- 海量数据处理
- 10G订单文件按金额排序,单机内存3G,无法一次加载到内存解决:
- 先扫描一遍订单,划分金额区间,如金额1-100的放到一个文件,使每个小文件可以单独加载到内存排序。最后合并有序小文件
- 如果订单数据存储在GFS这样的分布式系统上,每个文件可以并行加载到多台机器上处理。最后将结果合并
- 但注意,数据的存储和计算机器是同一个或网络很近(一个局域网内),这样数据存取速度比较快
回溯
常用于搜索问题,枚举所有的解,找出满足期望的解
为做到不重不漏,要把问题分成多阶段,每个阶段都会面临一个岔路,随机选择一条走,不通的时候回退到上一个岔路口,走其他的路,必要时剪枝避免搜索所有情况
// template
public void backtrack(参数列表) {
// 基本情况:如果已经得到了问题的解,那么直接返回或者进行处理
if (满足结束条件) {
// 处理解,例如添加到解的集合中
return;
}
// 特殊情况:如果当前的尝试不可能产生解,直接返回
if (不可能产生解) {
return;
}
// 尝试每一种可能的选择
for (选择的可能选项:选项列表) {
// 做出选择
选择;
// 递归调用,探索做这个选择后的新问题状态
backtrack(新的参数列表);
// 撤销选择,回溯
撤销选择;
}
}
八皇后
- 8x8棋盘,放8个棋子,使行、列、对角线上的棋子不重复
- 解,划分8个阶段,依次放入第1~8行,放置时检查满足要求。满足则继续,不满足则换一种方式继续
// 主函数
Solve_N_Queens():
board = create an 8x8 matrix initialized with 0 // 表示棋盘,0表示空格,1表示皇后
solutions = [] // 存储所有可能的解决方案
Place_Queens(board, 0, solutions) // 从第0行开始放置皇后
return solutions
// 放置皇后的辅助函数
Place_Queens(board, row, solutions):
if row == 8: // 如果已经到达最后一行的下一行,则找到了一个解决方案
solutions.append(board.copy()) // 将这个解决方案添加到solutions列表中
return
for col in range(8): // 在当前行尝试每一列
if Is_Safe(board, row, col): // 检查在[row,col]位置放置皇后是否安全
board[row][col] = 1 // 放置皇后
Place_Queens(board, row + 1, solutions) // 递归地放置下一行的皇后
board[row][col] = 0 // 回溯,移除刚放置的皇后并尝试下一列
// 检查放置皇后是否安全的辅助函数
Is_Safe(board, row, col):
// 检查同列是否有其他皇后
for i in range(row):
if board[i][col] == 1:
return False
// 检查左上对角线是否有其他皇后
for i, j in zip(range(row, -1, -1), range(col, -1, -1)):
if board[i][j] == 1:
return False
// 检查右上对角线是否有其他皇后
for i, j in zip(range(row, -1, -1), range(col, 8)):
if board[i][j] == 1:
return False
return True // 如果没有冲突,那么放置是安全的
board 是一个二维矩阵,用来表示棋盘的状态
solutions 是一个列表,用于存储所有有效的解决方案
Place_Queens 函数是一个递归函数,它尝试在棋盘的每一行放置一个皇后,并且通过调用 Is_Safe 函数来确保新放置的皇后不会与已放置的皇后相冲突
0-1背包
- 动态规划解决更高效
- 1个背包最大Wkg,n个物品,每个物品重量不等,且不可分割(要么装,要么不装)。放物品到背包中,<=背包容量,求最大重量?
- 每个物品两种选择,装进背包或不装进背包,不可分割,最优解依赖所有物品的组合,而贪心是局部最优,所以无法用贪心算法解决。
- n个物品有
个选择。过滤超出总重量的,选择总重量->Wkg的,如何枚举 个选择呢? - 物品依次排列,分n 个阶段。每个阶段选择1个物品
Knapsack_Optimized(W, weights, values, n):
// W 是背包的最大容量
// weights 是一个数组,表示每个物品的重量
// values 是一个数组,表示每个物品的价值
// n 是物品的个数
// 创建一个一维数组 dp,其中 dp[w] 表示当前背包容量为 w 时的最大价值
dp = array of size (W+1), initialized with 0
// 填充 dp 数组
for i from 1 to n: // 遍历物品
for w from W down to weights[i-1]: // 从后往前遍历所有可能的容量
if weights[i-1] <= w: // 如果当前物品可以放入背包
// 尝试放入当前物品,并更新 dp[w] 为最大价值
dp[w] = max(dp[w], dp[w-weights[i-1]] + values[i-1])
return dp[W] // 返回 dp 数组的最后一个元素,即为最大价值
使用了一个一维数组 dp 来存储状态。数组的每个位置 dp[w] 表示在背包容量为 w 的条件下能够装入的最大价值。由于每次迭代的状态仅依赖于上一轮迭代的状态,因此我们不再需要二维数组来存储所有的中间状态。关键的优化点是内层循环的遍历顺序。我们从后往前遍历,这样可以确保在计算 dp[w] 时所依赖的状态 dp[w-weights[i-1]] 还未被当前轮次的迭代更新,从而避免了覆盖还未使用的数据。这种方式称为“逆序更新”。这种优化方法假设每个物品只能选择一次(0-1 背包问题的特性)。如果物品可以选择多次,则必须正序更新。
正则表达式匹配
- 设,正则表达式只有* 和 ?两种通配符。* 表示匹配>=0个,?匹配0/1个
- 遍历表达式中每个字符。非通配符时进行字符匹配,相同则继续,不同则回溯。通配符时,随意选择一种满足条件的,继续下一步,中途失败则回到岔路口,选择另一种方案,继续。
应用:深度优先搜索,编译原理的语法分析,经典数学问题(数独,图的着色,八皇后,0-1背包,旅行商,全排列)
动态规划
动态规划适合求解最优问题,显著降低时间复杂度,提高代码执行效率
为什么需要动态规划? 大部分动态规划问题可通过回溯算法解决,不过动态规划效率高,用空间换时间。
动态规划问题特征:构建多阶段决策最优解模型,每个阶段对应一组状态,找这组的决策序列使能产生解的最优值
- 最优子结构:问题的最优解,可以通过子问题的最优解推导出,即前面的状态可推导出后面的状态
- 无后效性:推导时,只关心前面的状态值,不关心状态是怎么一步步推导出来的;某阶段的状态值一旦明确,就不受后面阶段的决策影响
- 重复子问题:不同的决策序列,当达到相同的阶段时,可能会产生重复的状态
解题思路,
- 状态转移表:回溯算法实现-定义状态-画递归树-找重复子问题-画状态转移表-根据递推关系填表-将填表过程翻译成代码
- 状态转移方程:找最优子结构-写状态转移方程-将状态转移方程翻译成代码
0-1背包
- 问题分解为多个阶段,每个阶段决定一个物品是否放进背包里,每个物品做完决策,背包重量会有多种情况,记录可达的状态集合(去重,避免指数级增长),通过当前状态推导下次
- 复杂度
- 时间:O(n* w),n 是物品个数,w 是背包可以承载的总重量;
- 空间:O(w+1)。用一维数组记录,由大到小遍历
升级:一组不同重量、不同价值、不可分割的物品,选择几个放入背包,前提是满足背包最大重量,实现装入价值最大?
- 用二维数组
status[n][w+1],记每层可达到的状态,二维数组存储当前当前状态的最大总价值 - 复杂度:时间 O(n* w),空间 O(n* w)
双十一购物满减,n个商品中选出几个,在满足满(200)减的条件下,怎样最赚?
- 二维数组
status[n][x]记录决策后的状态。薅羊毛,x值远大于200更有意义,可以设置x=1000+1,来求总价格既>=200的所有选择中的最小值 - 用
status[n][x]倒推出最小总价格对应的商品。ifstatus[i-1][j]=true可达,则没买第i 个商品 ;else ifstatus[i-1][j-value[i]]=true则买了第i 个商品
矩阵最短路径
递推公式 min_dist(i,j)=w[i][j]+min(min_dist(i-1,j),min_dist(i,j-1))
搜索引擎的拼写纠错
- 量化两个字符串的相似度↓,编辑距离 edit distance↑,1个字符串转成另1个字符串的最少编辑次数。两个相同字符串的编辑距离=0
- 字符串差异大小的编辑距离,符合多阶段决策最优模型
- 递归树
- 状态转移方程:
if a[i]!=b[j],min_dist[i][j]=min(min_dist[i-1][j]+1,min_dist[i][j-1]+1,min_dist[i-1][j-1]+1); else min_dist[i][j]=min(min_dist[i-1][j]+1,min_dist[i][j-1]+1,min_dist[i-1][j-1]) - 二维状态表
- 代码
- 举例找规律; 多练
最长公共子串长度
- 状态转移方程
if a[i]==b[j],max_lcs[i][j]=max(max_lcs[i-1][j],max_lcs[i][j-1],max_lcs[i-1][j-1]+1); else max_lcs[i][j]=max(max_lcs[i-1][j],max_lcs[i][j-1],max_lcs[i-1][j-1]) - 代码
商业优化 - 取编辑距离最小的top 10,根据其他参数,如 搜索热门程度,决定拼写纠错单词
- 统计用户搜索日志,得到拼写出错的单词列表(次数倒序)及正确单词的映射,找到后直接返回
- 引入个性化因素,搜索次数最大关键词中,找编辑距离最小的
性能分治优化 - 多机部署,负载均衡分配机器,计算编辑距离
- 纠错词库分到多个机器上,多台机器并行计算,比对合并得最优
算法对比
四个算法都是求最优解,贪心、回溯和动态规划是求多阶段决策,分治不是多阶段
-
回溯是万金油,枚举所有情况,对比得到最优解;时间复杂度高,指数级
-
动态规划要求高,必须最优子结构,无后效性和重复子问题。分治要求分割的子问题不重复,而动态规划相反
-
贪心是动态规划的一种特殊情况,解决问题更加简洁高效,但解决的问题更加有限,需满足,最优子结构,无后效性,贪心选择性
- 贪心选择性:通过局部最优选择,产生全局最优选择,每个阶段,选择当前看起来最优的决策
-
分治:强调将问题分解成子问题,递归解决,然后合并结果。分治算法通常用于可以线性分解的问题,如排序和查找。
-
回溯:强调试错和剪枝,适用于需要搜索所有可能解决方案的问题,如组合和排列问题。
-
递归:是一种编程技巧,允许函数调用自身。递归算法通常需要明确定义基本情况和递归步骤。
分治和回溯算法可能会使用递归来实现。
方法
Basic
- 临时变量:避免数据丢失,用于交换值
排序,二分查找
排序算法
升序排序
| 算法 | 时间复杂度 | 基于比较交换 | 稳定 | 原地 |
|---|---|---|---|---|
| 两个区间: 冒泡、选择; 插入✔、希尔(插入的多区间版) |
O n^2 | Y | 选择 N | Y |
| 多个区间: 快速✔、归并、堆排序 |
O nlogn | Y | 快速 N,堆N |
归并 N |
| 要求特定数据: 桶、计数、基数 |
O(n) (线性排序) O(n+a),a 是数据范围 O(dn),d 是维度 |
N | Y | N |
| 稳定:相同的两个数字位置固定 |
- 订单按下单时间和金额排序:按下单时间排序;用稳定算法按金额排序
- 选择非稳定:5 8 5 2 9,找到第一个最小元素2 与 5(第一个) 交换,则2个5的顺序变了
原地:不需要额外的存储空间
有序度:有序(从小到大)的元素对个数 a[i] <= a(j), if i < j
- 倒序 5 4 3 2 1 ,有序度=0
- 无序 2 4 3 1 5,有序对个数=6,(2,4) (2,3) (2,5) ; (4,5); (3,5); (1,5)
- 有序(满有序度) 1 2 3 4 5,完全有序下,有序对数量=C(n,2)
; 1到n-1的连续整数和 - 逆序度,从大到小, a[i] > a[j], if i > j = 满有序度 - 初始有序度;因此,不管算法怎么改,交换次数是固定的。交换1次,有序度+1,逆序度的值,就是需要交换的次数
排序,就是一个增加有序,减少逆序,直至满有序度的过程。一次排序,尽量确定多个元素对的有序。
| bubble | select | insert -> shell | |
|---|---|---|---|
| 操作 | 遍历unsort 区间;大值放后面(相邻比较交换) | 遍历 unsort 区间,最小放前面(遍历1次找到1个最小值,交换) | 向前遍历 sorted 区间,unsort[0]放前面(相邻比较交换) |
| 有序区间在? | 后 | 前 | 前 |
| 排序比较 | 交换,需3个动作 | 非稳定 |
- 1次交换,至少1个元素移动到最终位置,N次交换,确保N个元素移动到最终位置;一次交换的时间复杂度 O(1)
| quick 原地 | merge | |
|---|---|---|
| 操作 | 1. 选择基准分区:小于基准-基准元素-大于基准。基准在最终排序位置上 2. 基准左侧快排,右侧快排 递推公式:quickSort(p..r)=quickSort(p..q-1) + quickSort(q+1..r);pivot=p; 终止条件:p>=r |
1. 拆分小数组 递推公式:mergeSort(p..r)=merge( mergeSort(p..q) + mergeSort(q+1..r) ), q=p+(r-p)/2; 终止条件:p>=r,小数组内只有一个元素 2. 合并两个有序数组成一个有序数组用:临时数组,再copy 回原数组[p..r] |
| 比较 | 1. 处理顺序:↓ 向下;分区,处理子问题 | 1. 处理顺序:↑;处理子问题,合并 |
| 图解: | ||
| https://www.hello-algo.com/chapter_sorting/quick_sort/ | ||
| https://www.hello-algo.com/chapter_sorting/merge_sort/ |
- O(n)的时间复杂度,找到无序数组中的Top K(第 K 小元素)
- 快排思想,分区,0..p-1, p , p+1..len-1,pivot =len-1
- p+1=K,则 p 是结果
- p+1< K,K大元素出现在 p+1..len-1,则 在 p+1..len-1 递归查找
- p+1> K,在 0..p-1 递归查找
- 时间复杂度 O(n) :1次分区查找,遍历 len 个元素,2次分区查找,遍历 len/2 个元素,依次 len/序数 个元素,直至区间=1。每次遍历元素个数加和 (等比数列)= n+ n/2 +... +1 =
,则时间复杂度 O(n)
- 快排思想,分区,0..p-1, p , p+1..len-1,pivot =len-1
- 快速排序:∀ 节点 pivot 分区点,遍历数据,小的放左边,大的放右边, pivot放中间
- pivot 的意义:排序的最终位置,是第 pivot +1 大的元素
- 分区函数 partition :
- 原地✔不稳定:类似 选择排序,r 是 pivot ,下标 i (已处理区间的最后一个元素) 将 [p..r-1] 分成两个区间,前面的是已处理区间。从未处理区间取元素 A[j] < A[r] ,swap(i,j), i++
- 非原地:两个临时数组 X Y,小的放X,大的放Y,copy 回原数组[p..r]
- 复杂度
- 时间:设需要时间 Tn, 分成两个子问题的时间是 Tn/2,列式 T(1)=C , T(n)=2T(n/2) +n n>1 = 2^k * T( n/2^k ) + k * n,k是序数,当 n/2^k=1时,k=log_{2}{n},T(n)=Cn+nlog_
- 快速的 pivot 分区非常不均衡(少见情况),复杂度退化到 O(n^2)
- 空间:merge 时申请 额外空间,但合并完成后,临时申请的空间被释放。因此,任意时刻,CPU只有一个函数在执行,申请的空间申请最大<=len
- 时间:设需要时间 Tn, 分成两个子问题的时间是 Tn/2,列式 T(1)=C , T(n)=2T(n/2) +n n>1 = 2^k * T( n/2^k ) + k * n,k是序数,当 n/2^k=1时,k=log_{2}{n},T(n)=Cn+nlog_
| bucket | count | 基数 radix | |
|---|---|---|---|
| 操作 | 数据分m个区间,区内排序,按顺序取出; 分区:len个元素,平均放到 m 个桶,每个桶有元素个数 a= len/m; - buckets = new int[bucketNum][0]- 输入 bucketSize,则 m=bucketNum=(maxValue - minValue) / bucketSize + 1 桶内排序:快排 |
桶排序的特殊情况:使用中间数组计数,1个值1个组,组内存数值的个数,根据值与顺序和关系排序 - |
稳定算法,从后向前,先按最后一位排序,再按倒数第二位重新排序... 遍历一遍即有序 |
| 复杂度 | 快排复杂度 O(aloga ); m个桶 O(maloga ), ∵ a=len/m,则 m个桶 O(len loglen/m ) when len=m, log len/m = 0,即 O(len) |
||
| 条件 | 1. 数据易分成 m 个桶,桶间有大小顺序 2. 数据在桶间数量差不多,否则时间复杂度会高,极端情况退化到 O(nlogn) |
1. 数据范围小 2. 数据是非负整数。其他类型需要转成非负整数 |
1. 数据可以分割成独立的位来比较,位间有递进关系,如果高位上,a值>b值,则低位不用比较 2. 每位的数据范围不能太大,可以用线性算法排序 2. 非等长数据,高位补位为0,ASCII中,所有字母>0 |
| 适用 | 1. 外部排序,数据存在磁盘,内存有限无法全部加载 |
- 10G 的订单,按金额排序
- 桶排序:1.遍历一遍,查找金额数据范围 2. 金额划到100个桶,理想状态金额均匀分布,每个桶100M的订单数据,桶内用快排进行排序;桶很大时继续划分小桶,直到所有文件都能读入内存
- 省内50w考生的高考成绩排名,满分900;根据年龄给100w用户排序同理
- 计数排序:桶范围 [0,900]
- 计算考生在排序数组中的位置:
- A[8] 从后向前遍历,A[8]=3=Cidx,C[3]=7,则 数值 3 是排序后的第7个数字,其排序后的下标值=7-1=6
- 从C[3] 从取出一个数字3(C[3]=6),放入 R[6]中
- 遍历完数组A,则R是A数据的有序排序(小到大)
| idx | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| A[8] 原数组,值是数值 | 2 | 5 | 3 | 0 | 2 | 3 | 0 | 3 |
| C[6] 中间数组,计数排序,值是个数 | 2 | 0 | 2 | 3 | 0 | 1 | ||
| C[6] 排序后顺序求和,值是个数和 | 2 | 2 | 4 | 7-1 | 7 | 8 | ||
| R[8] 数值在有序数组的存储位置,值是下标 | 3 |
- 10w 个手机号排序
- 特点:两个号码A B 排序,A 前几位大,则A大,不需要继续排序
- 基数排序:使用稳定算法,从后向前,先按最后一位排序,再按倒数第二位重新排序... 遍历一遍即有序
通用高性能的排序函数
优化快排:避免退化到 O(n^2),分区点形成的两个区间,数据量差不多。-> 选分区点
- 三数取中:从区间两端和中间取三个数,用中间值
- 随机:概率上效果好
c.glibc qsort() :
- 数据量小1k 2k:归并,使用额外的1k,2k的空间
- 数据量大 100M,快排;分区点:三数取中;避免堆栈溢出:堆上实现栈
- 快排时排序区间<=4时,用插入 ,插入时用哨兵简化代码(少做1次判断,常用) ;O(n^2)>O(nlogn) 指的增长趋势,但值小时,受常数、系数和低阶函数的影响,n^2可能更小
二分查找
有序查找
- 二分查找适用于有序数组,使用下标O(1)访问特性
- 有序链表:如果完全内存操作,红黑树(常用的平衡二叉查找树,中序遍历有序)和跳表(存储小到大,数值或字典顺序)效率高,如果数据量很大,B+树的更高
二分查找是有序集合的查找算法
- 复杂度O(logn) :数量个数n,每次查找数据个数减半,直到找到或结束。变化是一个等比数列
次数= ,时间复杂度就是 O(logn) - 对数的反函数是指数
- 实现:有序数组∄重复元素,查找值=给定值的元素
- 循环:1. 循环退出条件 low<=high 2. mid = low + (high - low)>>1 3. low=mid+1,high=mid-1
- 递归:f(left, right) 表示在数组从索引left到right之间查找目标值target的过程
// 循环
left = 0
right = length(array) - 1
while left <= right:
mid = low + (high - low)>>1 // 避免内存溢出,位运算速度更快
if array[mid] == target:
return mid # 找到目标值,返回其索引
elif array[mid] < target:
left = mid + 1 # 目标值在右半部分,更新左边界
else:
right = mid - 1 # 目标值在左半部分,更新右边界
// 递归
f(left, right) =
if array[mid] == target then mid
else if array[mid] < target then f(mid + 1, right)
else f(left, mid - 1)
- 局限
- 必须是数组,必须数据有序
- 数据量适中:太小,查找速度差不多;太大,数组需要连续空间1G;
- 特殊:数据比较耗时,不管数据量大小,用二分查找。如,数组存长度>300的字符串,字符串间的比较用二分查找
- 示例
- 猜字游戏,0-99间的数字
- 1000条订单,已按金额小到大排序,金额不重复,最小单位是元,问是否存在金额=19元的订单
- 1kw个整数数据,1个整数8byte,查找某个整数在集合中
- 数据占内存 80M=1kw×8/2^20,先排序,再二分
- 不适合用散列表和二叉树,需要额外的内存空间,100 M 空间太小
- 12w [IP区间,归属地],快速定位出一个IP区间的归属地?
- 不常更新,进行预处理。 IP 从小到大排序,IP转32位整数-> 有序数组中,查找最后一个≤给定值的元素
- 变形:有序数组∃重复元素(小到大)
- 查找 第1个/最后1个值=给定值 的元素:
if(a[mid] == value) {if (mid==0 || a[mid-1]!=value {return mid} else {high=mid-1})} - 查找 第1个≥给定值的元素;最后1个值≤给定值的元素
if(a[mid] >= value) {if (mid==0 || a[mid-1]<value {return mid} else {high=mid-1})}
- 查找 第1个/最后1个值=给定值 的元素:
跳表
链表的二分查找,可替代红黑树
实现:加1层索引,查找时遍历的节点数↓
时间复杂度:
- 链表节点个数n,每2个节点抽出一个索引节点,则索引层数=?
- 1 st 索引个数=n/2,k st 索引个数=
,最高级索引个数=2, - 包含原始链表这一层,整个跳表高度
- 如果每层都遍历 m 个节点,查一个数据的时间复杂度就是
- m=3,即每级至多遍历3个节点。∵ 每2个节点抽出一个索引,上层是两个节点的区间,下层就是3个节点的区间,下层的这三个节点,就是每层至多遍历的3个节点
空间复杂度 - 每2个节点抽出一个索引节点,每层节点个数:
,节点和=n-2,所以空间复杂度 O(n)
- 每3个节点抽出一个索引节点,每层节点个数:
,节点和=n/2,所以空间复杂度 O(n),并且减少一半的存储空间 - 实际开发中,不必太在意内存空间占用,∵ 索引节点存指针,而不是对象。当对象很大时,索引占用的空间可以忽略
插入删除 - 插入:定位,插入;
- 删除:删数据删索引,单链表要查定位到前驱节点,双链表可以直接看到前驱节点
- 索引更新:随机函数,插入数据时将数据同时插入部分索引层中:随机函数生成值K,则将节点添加到第1~K级索引中
- 红黑树,AVL树 这样的平衡二叉树,通过左右旋,保持左右子树的大小平衡
Redis 用跳表实现有序集合
- 红黑树,AVL树 这样的平衡二叉树,通过左右旋,保持左右子树的大小平衡
- 核心操作,增删改查遍历+区间查,跳表区间查更有优势
- 跳表更容易实现(可读),更灵活(改变索引构建策略,平衡执行效率和内存消耗)
用户积分排行榜
- userId 查积分信息;积分 区间查 userId; key(数据):userId,score(索引,查区间):积分
前缀和
双指针
用于线性结构,移动指针,减少不必要的比较和遍历
数组
- 有序数组中,两数和=目标值。从两侧向中间查找
- 有序数组中删除重复元素。一个指针指向唯一元素的位置
链表
- 检查环。快指针每次移动2步,慢指针每次移动1步
合并2个数组或链表
数组/字符串,找子序列
用于查找时,和 map 组合,提高效率。
leetcode-287-find-the-duplicate-number
滑动窗口
一种特殊的双指针。都是用2个指针求解。
逻辑:
- 初始化:定义两个指针,通常称为
left和right,分别代表窗口的左右边界。 - 扩展窗口:移动
right指针扩展窗口,直到窗口内不满足特定条件。 - 收缩窗口:移动
left指针收缩窗口,直到窗口内再次满足条件。 - 更新结果:在每次窗口满足条件时,根据问题需求更新结果(如最大值、最小值、计数等)。
- 重复:重复步骤2和3,直到
right指针到达数组或字符串的末尾。
适用于求解:
[最大/最小] + [子数组/子串] 问题:例如,找到最大/最小和子数组、最大/最小乘积子数组等。
连续 [子数组/子串] 问题:例如,找到连续子数组中的最大和、连续子串中不同字符的数量等。
[子数组/子串] 包含特定元素的问题:例如,找到包含所有特定字符的最小子串长度。
滑动窗口内的统计问题:例如,计算滑动窗口内奇数和偶数的数量。
// template
int result = 初始化结果;
int left = 0;
for (int right = 0; right < s.length(); right++) {
// 扩展窗口
if (需要收缩窗口) {
left = 更新left指针;
}
// 更新结果
result = 更新结果;
}
return result;
并查集
了解
数论
计算几何
线性规划
拓扑排序
拓扑排序特别适合依赖关系处理。得到一个合理的执行顺序,确保所有前置任务都在后续任务开始前完成。特别适用于有向无环图。
它是一种线性排序,其目的是对于给定的有向图G=(V, E),将所有顶点排成一个线性序列,使得对任意边(a, b)∈E,都有a比b先出现在这个序列中。换句话说,对于图中的每一条有向边u->v,顶点u在排序后的序列中都位于顶点v之前。
实现拓扑排序的常用算法包括Kahn算法和基于深度优先搜索(DFS)的算法。Kahn算法的基本思想是反复选择入度为0的节点,将其输出并从图中删除,直到图为空或者找不到入度为0的节点为止;基于DFS的算法则是利用递归回溯的思想,在遍历过程中记录下访问的顺序,最后反转即可得到拓扑排序的结果。
编译器通过分析源文件或配置文件,来获得两个文件间的依赖关系,那如何通过两两关系,确定一个全局的编译顺序呢?
将问题背景,抽象成具体的数据结构:源文件间的依赖关系,抽象成一个有向无环。如何实现拓扑排序?
kahn
- 贪心
- 某个顶点入度=0,则不被依赖,可执行
- 已执行顶点从图中删掉,可达顶点的入度-1
- 遍历,直到所有顶点被输出,输出序列就是结果
- 时间复杂度:每个顶点、每条边被访问一次,O(v+e),v是顶点个数,e是边个数
dfs - 深度优先遍历。遍历图中所有顶点
- 用邻接表构造逆邻接表
- 递归处理每个顶点,先输出所有可达顶点,再输出当前节点
- 时间复杂度:每个顶点被访问2次,每条边被访问1次,O(v+e)
检测图中环的存在
- 记录已访问用户ID,当用户ID被第二次访问,则存在环
改进,数据库中所有用户的推荐关系中,存在环,用拓扑排序
最短路径
地图软件计算最优出行路径
有权图,min(边的权重和)
- 最短路线
- 最少用时
- 最少红绿灯
地图中,路的长度是权重。地图可以抽象成1个有权有向图
单源最短路径法(1个顶点到1个顶点),最常用的是Dij法
翻译系统,翻译句子,通过翻译单词,返回单词列表,根据可信度选用翻译
位图
网页爬虫中的URL去重
- 方法1:分治+散列表
- 方法2:Bloom Filter,是对位图的改进
位图 BitMap:有1kw个整数,整数范围是1~1y,如何快速查找一个整数在1kw的范围内?
位图解决,申请大小1y,boolean 类型的数组,将1kw个整数作为数组下标,设置成true。查询整∈1kw时,只需要将对应的数组值取出来,看是否=true。boolean类型大小一般是1byte,而我们只需要一个二进制位 1bit就可以。1y个二进制位,只需要12M内存
Bloom Filter,用 Hash算法,将数字,超过1y,如10y,落在1y范围内,只需要求模取余。Bloom Filter 处理hash 冲突,用多个hash 函数一块定位数据。如果都是true,说明数值存在,∀一个false,则数值不存在。这种方法容易误判,但只要调整Hash函数个数、位图大小和数字个数间比例,就可以将这个错误降到最低,适用于爬虫判重。
Bloom 多在Hash计算耗时,所以CPU密集;而散列表在处理冲突时需匹配原链接,涉及内存操作,是内存密集的。CPU一般快于内存,所以Bloom快于Hash
Bloom Filter 应用广泛,如Java提供BitSet,Redis 提供 BitMap,Guava 提供 BloomFilter
概率统计
过滤垃圾短信
- 方法1:黑名单
- 方法2:规则
- 方法3:概率统计
工程中,可以结合三个方法,并且通过具体场景具体测试调整策略,提高判断准确率和召回率(找到所有垃圾短信)
向量空间
音乐推荐系统
- 偏好相似用户听的
- 喜爱歌曲相似的歌曲
简单向量空间的欧几里得距离
B+树
定义问题:限定范围。常见SQL:
- 查 where=
- 区间查 where in
对于非功能需求,考虑性能。执行效率和存储空间
B+树,二叉查找树的延伸。
让二叉查找树支持区间查找,可以让树的节点不存数据,只存索引。并且,把叶子节点串在一条链表上,链表数据从小到大有序。像跳表。
因为索引量大,内存无法全部存储,因此将索引存储在硬盘。为尽量减少磁盘IO,要降低树的高度。因此,把索引构建成m叉树,m的大小,尽量让每个节点的大小是1页的大小,读取一个节点,只需要一次磁盘IO操作。
索引可能导致写入变慢,因为数据的写入,涉及索引更新。当写入超过m,可以将一个节点分成2个节点,这个分裂会影响父节点,从下到上,直到根节点。
索引导致删除变慢。设置阈值m/2,如果子节点个数<阈值,则合并兄弟节点。合并可能>m,则分裂节点。
索引的B+树,叶子节点是双链表,便于增删时重连节点。
搜索
游戏中的寻路。用A* 搜索算法。
当下是起点,鼠标是终点,在地图中绕过障碍物,找到一条最短路径。
A* 算法是对 Dijkstra 的改造。是一种启发式算法,使用估价函数,贪心的朝着最优可能到达终点的方向前进。
索引
海量数量中快速查找某个数据。如 redis 中的 kv结构。
软件开发本质是对数据的存储和计算。一旦存储数据变多,需要关注存储相关系统的性能,如MySQL,分布式文件系统,消息中间件 MQ。
索引设计
- 功能需求:格式化数据?静态数据?内存存储?单值查找?单关键词查找?
- 非功能需求:空间消耗小,索引查询效率,维护成本
常见数据结构 - 散列表:查找O(1),Redis;构建在内存中
- 红黑树:查找O(logn),Ext文件系统,磁盘块索引;构建在内存中
- B+树:多叉树,磁盘索引,MySQL,Oracle
- 跳表:可以灵活调整索引个数和数据个数的比例,如Redis 中的有序集合
- 位图和Bloom Filter:内存占用少,避免读磁盘索引
- 有序数组:静态数据抽取关键词,组成有序数组,用二分查找查数据
并行
排序:给8G数据排序。排序常用时间复杂度是O(logn)的算法,归并、快速和堆;进一步优化
- 归并并行化:8G划分成16个小的数据集合,每个集合500M,用16个线程,并行排序后合并
- 快速并行化:扫描一遍数据,找出数据所属的区间范围。划分成16个区间,启动16个线程,并行排序,16个线程都执行结束,得到有序数据
- 都是分治思想,数据分片,并行处理。第一种随意分片;第二种按数据大小划分区间
- 如果要排序的规模不是8G,而是1T,则一定存在硬盘中,无法一次加载到内存,则磁盘IO就是优化重点
查找 - 散列表。动态数据,调整装载因子并扩容。可以将数据随机分割成K份如16份,每份数据只有原来的1/K,则针对小集合分别构建散列表。维护成本变低,可以单独对小的散列表扩容。查找数据时,通过16个线程,并行在16个散列表中查找,比大散列表效率高。向散列表添加数据,可以选装载因子小的那个散列表,减少散列冲突。
字符串匹配 - 如果查找文本大,可以拆分成小文本,每个文本一个线程处理。同时,需在小文本的开头结尾各取m个字符串,在2m字符串中找一遍,避免拆分文件引起字符串分割。
搜索 - 搜索算法:广度、深度,Dijkstra最短路径,A* 启发式
- 广度并行:逐层,基于当前一层,启动多个线程,并行搜索下一层顶点。用2个队列完成顶点扩展工作。多线程并行处理队列A中的顶点,将扩展得到的顶点存在B中,A扩展完后清空,并行的扩展B中顶点,将扩展结果存在A中,循环使用。
MapReduce 是并行计算框架
应用
lib-redis
- 有序数组
- 双向链表
- 散列表
- 跳表
搜索引擎
一台机器,8G内存,100G硬盘,实现简易搜索引擎
- 搜集:爬虫
- 互联网是一个有向图,每个网页是一个顶点。一个网页引用另一个网页,则建立边指向→,可以用图的遍历算法,广度优先搜索,从知名的种子网页开始,获取互联网中的网页
- 解析页面获取链接:一个页面是大的字符串,用字符串匹配算法,搜网页标签
- 链接存储 links.bin,支持断点续爬,机器断电后不会丢
- 避免重复爬取,bloom 过滤器。因为 bloom过滤器存在内存,为避免宕机清空,可以定期(每半小时)将bloom持久化到磁盘,存储在bloom_filter.bin,即使宕机,只丢失部分数据
- 原始网页存储:用于离线分析,索引。多个网页存在一个文件,避免文件过多,每个网页通过标识符分隔,方便后续读取。网页编号-网页大小-网页。单个文件大小超过1G,则创建新文件。
- 网页编号,给网页分配唯一ID,可以按网页爬取顺序,维护中心计数器,+1,将网页编号和链接存在 doc_id.bin
- 分析:内容抽取、分词,构建临时索引,计算PageRank值
- 抽取网页文本信息,除去JavaScript代码,CSS样式等标签,用AC自动机这种多模式串匹配算法,在网页中一次查找多个标签,删掉遍历到的标签及包含的字符串
- 英文分词,只需要空格、标签符号等分隔符,将单词分隔开。中文需要字典(词库、常用词)和规则的分词(最长匹配,匹配尽可能长的词语)算法,构建成 Trie 树,
- 分词后,得到一组单词列表。把单词(单词编号term_id)和网页(网页编号doc_id)关系,写到一个临时索引 temp_index.bin。单词编号用中心计数器生成,用散列表记录已经编号过的单词,没有才生成编号。编号和单词映射,写入文件 term_id.bin
- 索引:用临时索引,构建倒排索引
- 倒排索引,记录单词和对应的网页列表。因为临时索引文件很大,无法一次加载到内存,则使用多路归并排序实现。先对临时索引文件,按单词编号大小排序,分割多个文件,先对每个小文件独立排序,再合并,可以直接用MapReduce。临时索引排序完,相同的单词被排列到一起,顺序遍历文件,就可以找到每个单词对应的网页文件,存到倒排索引文件中。单词编号在倒排索引文件中的位置偏移,记录在term_offset.bin,便于快速查找单词编号在倒排索引文件中的位置。
- 查询:请求响应。根据倒排索引获取网页,计算网页排名,返回结果
- doc_id.bin,网页链接和编号;term_id.bin:单词和编号;index.bin:倒排索引,单词编号和对应的网页编号;term_offset.bin:单词编号在倒排索引文件的位置。
- 除index.bin外,其余文件偏小,直接加载到内存,组织成散列表
- 用户查询时,先对查询内容分词,设得到k个单词,find in term_id.bin,term_offset.bin,index.bin。针对查到的网页编号,用散列表统计次数,小到大排序,次数多,则含更多用户查询单词。doc_id.bin 分页显示给用户
Disruptor
循环有界数组队列
线程间传递消息的内存消息队列,用于 camel, log4j。比 ArrayBlockQueue 性能高一个数量级。
因为机器内存有限,所以有界队列应用更广泛,不可控的因素,会有潜在的风险,极端情况下,无界队列会导致OOM out of memory。
循环队列,避免消息搬移。
当有多个生产者并发往队列里写数据,可能导致数据覆盖丢失;多个消费者消费同一条,可能重复消费。可能解决
- 加锁,或CAS优化
- 无锁。2阶段写入,写入前加锁,用于申请多个连续的内存空间,则写入无需加锁;
- 存在的缺点,必须先申请的内存空间先消费
接口鉴权限流
接口鉴权匹配拦截
- 不同应用有不同的规则集合,可以用散列表存储,value 是一个字符数组。因此规则不常变动,可以按字符串大小给规则排序,组织成有序数组,查找某个URL是否匹配时,可以用二分查找,时间复杂度O(logn)
- 前缀匹配:规则集合适合Trie 树存储。一层节点可以组成有序数组,匹配时可以用二分查找,决定跳到哪个子节点
- 模糊匹配:因为字符串回溯匹配代价高,可以把通配符和非通配符分开,先精准匹配非通配符,再匹配通配符。通配符规则存储在数组,因为量少,所以可以接受
限流 - 限制接口调用频率,如每秒少于100次调用,超出后,拒绝服务。限流可以分为,限制一个应用对某个接口的访问频率,限制单个接口访问频率,限制所有接口的总访问频率
- 精准限流:
- 固定时间窗口限流法。选定一个时间起点,当有接口请求到来,计数器+1,在当前时间窗口内,超出限流阈值拒绝访问。当进入下一个时间窗口后,清零重新计数。可能的问题:突发流量。
- 滑动时间窗口限流:限制任意1s内,接口请求数<阈值K。维护一个循环队列,大小K+1,当新请求到来,将与新请求时间差>1s的老请求,从队列中删除。如果循环队列仍有空闲,则把新请求存在队列尾部,否则拒绝。
- 但基于时间窗口的限流算法,不能避免短时间的流量激增,因此,有更平滑的限流算法,如令牌桶,漏桶
短链
长网址转成短网址。访问时,重定向到原始网址。
长网址转成短网址:
- Hash算法,不关注反向解密的难度,只关心计算速度和冲突概率。MurmurHash,广泛应用于 Redis等软件。有32bit的hash值。将10进制的hash值转成更高进制如62进制,短网址会更短。
- Hash冲突:保存短网址和原始网址间的映射,在数据库中。拿生成的短网址去数据库查,已存在,如果原始网址一致,则直接用库内的短网址,如果原始网址不一致,则冲突,可以给原始网址拼字符串“[DUPLICATED]”,计算Hash值,这个概率会小的多,若还冲突,继续拼字符串。将短网址和拼接字符串的原始网址一起存数据库
- 当用户查询,用短链查长链。长链有特殊字符,则去掉后返回
优化Hash算法生成短网址的性能 - 给短网址加唯一索引,即短网址不能重复。
- 方法1:生成短链后,直接尝试保存,违反唯一约束后再“查询、写入”。因为冲突概率小,所以可行
- 方法2:短网址构建bloom过滤器,长度10亿的bloom过滤器,只需要125M左右内存。先查bloom过滤器,再尝试直接保存
概念
https://mp.weixin.qq.com/s/om0plD_OuI31ksQHWCjwfw
>>
8的二进制是1000,4的二进制是0100,
存储转换
1Byte =8bit
1 KB = 2^10 Byte,500字作文
1 MB = 2^10 KB,50w=500,000汉字
1 GB = 2^10 MB,5亿汉字
1 TB = 2^10 GB,300亿汉字,1000 部电影
实时统计业务接口中99%响应时间?堆结构
offset
偏移量,如分页查询(fetch,limit)