lib-kafka
quick start
- 运行、改接口验证。
- 功能
- 运维监控(指标参数)
- 客户端:
- 数据存储:提交日志 下标访问 #低延迟 ->可重复消费 #高可用
- 生产者:分区 #高吞吐 (均衡问题),同步副本集ISR #高可用 ,压缩 #高吞吐 ,无消息丢失配置 #高可用 ,TCP连接管理,幂等 #可用
- 消费者:组 #高吞吐 rebalance #高可用 ,consumer 消费后 位移主题 提交 #高可用 ,异常处理,TCP连接管理
- 1 broker=1 kafka 实例=最好1个机器,N生产者=N default 1 主题,1主题=N分区,1分区=N Replication 副本=1 Leader+ (N-1) follower in ISR,N分区=1 group 中的1 consumer,不同group 中的consumer 可以消费同一个分区。均衡:key+ 轮询;
- 关注可靠性和性能,通读文档,理解参数
- 高级功能,流处理
低延迟:优化消息处理和减少数据传输
定义
发布订阅模式,可通过 Java Message Service 的API管理
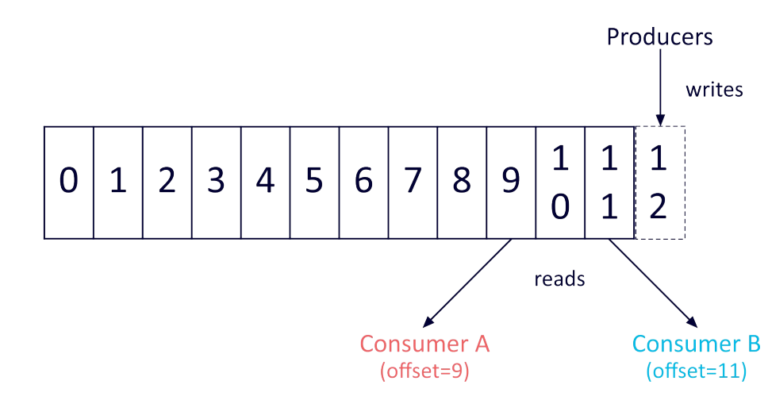
Kafka 本质上是一个具有简单数据结构的提交日志(Replication 作为 #数据容器):
二进制编码 #通用-编码 ,有序存储,数据只追加不删除,定期删除老的Log Segment日志段。按Offset下标 读取 #性能-响应速度-下标。producer 发送,consumer 拉取,达到应对 #并发-异步 的”削峰填谷“
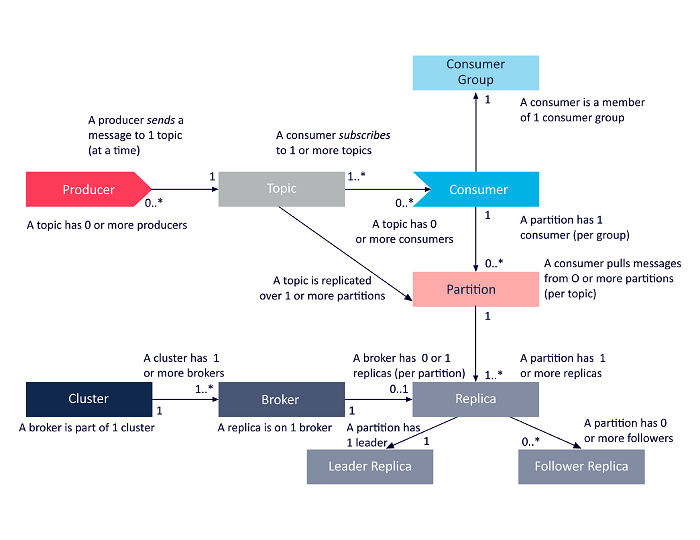
apache-kafka-architecture[1]
- Producer生产者,Broker代理,Consumer 消费者
- 最好1个Broker(1个Kafka 实例) 1个机器,避免宕机 #可用:负载 。分区和副本会被均匀地分配到各个Broker上
- 消费者组,瓜分(不重复消费)消息,当一个消费者挂掉,自动给消费者重新分配分区
- 每个消费者有个Offset 偏移量字段,消费者位移是下一条消息的偏移量,一个consumer group中,consumer:replica=1:n,确保消息处理的顺序性;不同组中的消费者可以消费同一个分区(消息重复使用)
- Topic 主题,Partition 分区 #并发-增减机器-伸缩 ,Offset 偏移量
- 分区分布:当创建一个topic时,可以指定该topic的分区数。分区讲topic 消息均匀分散在集群中的不同 Broker 上。例如,假设有一个包含 3 个 Broker 的 Kafka 集群,并且创建了一个有 6 个分区的主题,那么每个 Broker 上将会有 2 个分区
- 消息在分区的位置用 分区位移 表示
- Replication 副本 #可用:冗余
- 生产者和消费者,和分区中的Leader Replica 交互
- 副本存储 topic 数据,有自己的日志文件,即日志段隶属于副本
主题、broker 与分区
- 一个Broker上的某个分区,如果是Leader副本,就不是Follower副本
- 一个机器(1个 broker 实例)有这个主题的一部分或全部
- 常见分区策略 ,1. 轮询√,1个主题3分区,消息1到分区0,消息2到分区1 ... 2. 随机 3. 消息key √
- 默认:先 key 再轮询
- 具有相同键(如
userId)的消息总是被发送到同一个分区,从而保证这些消息在该分区内的顺序- 3个分区,`hash(key1) % 3 = 0,hash(key4) % 3 = 0
2 topic, 2 broker, 2 partition;生产者和消费者与 Leader 副本 交互;
不均衡体现在 1. 分区在borker间的分配不均,如下,定期检查并调整分区的Leader副本,以保持均衡 2. 消息不均,见分区策略
Broker 1
- 3个分区,`hash(key1) % 3 = 0,hash(key4) % 3 = 0
- Leader 副本: orders-partition0、orders-partition1、logs-partition0、logs-partition1
- Follower 副本: 无
Broker 2 (与 Broker 1的 leader follower 互换) - Leader 副本: 无
- Follower 副本: orders-partition0、orders-partition1、logs-partition0、logs-partition1
副本
follower replica 异步拉 Leader Replica 的数据,不提供读,因为
- 方便 read your writes
- 对于消费者,不会看到一个消息一会在一会不在
- 不存在与 leader 实时同步风险。ISR in sync peplica是1个集合,一定含 leader。用replica.lag.time.max.ms 定义允许follower 允许落后的最长时间间隔(阈值),在阈值内的follower 加入集合。
- leader 挂了,ISR为空,怎么选leader。1. 允许非ISR的follower 选 x unclean.leader.election.enable=false
流处理
生产者
压缩
trade off,时间换空间
Producer 压缩:确保生产者用的压缩算法,Broker支持,避免隐性的压缩转换
Consumer 解压
cpu资源充足时用压缩算法zstd,性能差但占用宽带少
消息不丢失配置
谁负责谁解决
对已提交的数据做持久化配置。
- 已提交:可以是N(>=1)个 Broker 保存成功消息
- 持久化:N 个 Broker 至少1个存活
消息丢失 - Producer 丢失:使用回调函数,失败处理:瞬时错误重试;消息格式错误,改代码
- Consumer 丢失:1. 先消费消息,再更新位移。可能重复消费。2. Consumer 使用多线程,使用手动提交位移,避免线程消费失败。多线程很难处理消费者位移情况,可能重复消费
- 冗余;broker follower 落后太多,不要竞选leader
管理TCP连接
- 使用 TCP 原因:自动重传丢失的报文。使用者可能用高级功能,如多路复用请求,在一个物理连接上创建若干虚拟连接,每个虚拟连接流转各自的数据流
创建连接 - 创建实例时建立 TCP连接,与所有 Broker 建立连接(与所有连接不合理)。但 Producer 一旦连接到集群中的任意一台 Broker,就能拿到整个集群的Broker 信息。
- 还有2个创建地方:发现没连接时创建连接 1. Producer 更新集群的元数据后,2. 消息发送时
- 更新元数据场景 1. Producer 尝试给不存在的主题发消息,Broker 告诉 Producer 主题不存在 2. Producer 通过 metadata.max.age.ms 参数定期更新元数据
关闭连接
- 更新元数据场景 1. Producer 尝试给不存在的主题发消息,Broker 告诉 Producer 主题不存在 2. Producer 通过 metadata.max.age.ms 参数定期更新元数据
- 用户主动关闭√
- Kafka 自动关闭:connections.max.idle.ms default=9min。被动关闭会产生 CLOSE_WAIT连接,用户没机会观测到连接已被中断
幂等事务,消息可靠性
- 至少一次,消息不丢,可能重复发送。若Broker 提交消息成功,但应答没有返回给 Producer,如网络抖动,则Producer 重试,则消息重复。
- 如果允许消息丢失,但不能重复,可以使用最多一次。
- 精确一次:消息不丢,不重复。幂等+事务实现。幂等用空间换时间,多保存一些字段,发现重复后默默丢掉。但只能保证单分区的幂等,单会话(Producer 单进程,重启消失)的幂等,其他情况由事务满足,原子性写入多个分区,Producer 重启回来后也只有一条消息保存在 Broker。全部失败后,配置 事务隔离级别,read_committed,确保 Consumer 只读到全部成功的消息。如果没有开启事务,或者隔离级别是 read_uncommited(默认),则能看到全部消息。不过,事务开销大。
- 事务隔离级别的实现依赖于锁机制和多版本并发控制(MVCC)
消费者
消费者组:支持消费者实例共同消费一个主题中的所有分区,是可扩展,且容错的消费者机制
可扩展,负载:可增/减消费者实例,
- consumer 实例数量:最好=组内订阅所有主题的分区总数。3个主题,分区数分别是1,2,3;则总分区数=1+2+3=6,如果6个consumer,则 1个 consumer 2个分区;如果 8个 consumer,则空闲2个consumer=8-6。
- 消费者独有的消费者位移保存在Broker的内部主题中
容错:通过reblance 确保负载均衡。重新给consumer 分配分区。发生时机 1. 组内 consumer 增减 2. 订阅主题数变 3. 主题分区数变。分配策略:尽量公平,每个consumer 拿到较平均的分区数。避免有的闲死,有的忙死。 - 缺点:gc stop the whrld,所有线程停止工作,应用程序卡住。reblance 也有这样问题。
- 降低 reblance 数,提升 TPS:避免参数不合理导致组成员退出,如 1. consumer 消费时间过长,则 max.poll.interval.ms 设置大些,避免 consumer 离组;2. full gc 导致长时间停顿,引发 reblance
位移主题
- 位移数据作为普通 kafka 消息,保存在_consumer_offsets,这需要高持久性和高频的写操作。kv 结构保存,key: <group id,topic,partition>,value:位移值+其他如时间戳(过期)
- 消息格式:1. 用于保存位移值的kv 2. 保存 consumer group消息的未知格式 3. 用于删除过期位移和过期 group消息的kv,v=null,写入时机:group 下的consumer 停止+位移数据都被删除,则写入位移主题,表示要彻底删除group
- 位移主题的创建时机:集群的第一个consumer 被创建时自动创建位移主题,默认分区数 offset.topic.num.partitions=default 50,副本数是3 offsets.topic.replication.factor =default 3。可以手动创建位移,使用 API,但因为kafka 内部硬编码,所以不建议手动创建。
- consumer 提交位移:自动提交+定期删除旧位移,或手动提交√。手动可控,100条消息提交一次位移,异步提交避免阻塞,consumer 关闭前,同步提交确保保存正确的位移数据。
- CommitFailedException,位移提交时出错,不可恢复。可能场景 1. 消息提交总时间超预设,max.poll.interval.ms,解决:优化消费逻辑;增加消费时长;减少每次 poll 返回的消息数。
多线程消费
- 多线程+多 consumer 实例:消息获取和消息处理用一个线程,consumer impl runnbale
- 优点:1.实现简单,避免安全处理 2. 顺序消费
- 缺点:1. 占用资源多,N个线程N个实例,占用 TCP,内存 2. 线程数受限于总分区数 3. 处理消息易超时,触发 reblance
- 单线程+单consumer 实例+消息处理线程池:消息获取和消息处理用各自的线程;consumer.poll,拉取消息返回后,遍历消息,交给单独的线程池。
- 优点:独立调节
- 缺点:无法保证顺序消费,正确位移提交困难,可能消息重复消费。
管理TCP连接
- 创建连接:拉消息时 1. 消费者协调 coordinator 管理组成员和位移,consumer 向coordinator 发请求或连接 2. 消费数据
- 创建1个连接,获取集群信息;发消息时连接到要发送的broker
- 如果循环拉消息,连接定期发给 broker,实现长连接。否则 手动关连接 connection.max.idle.ms
- 最好使用 <主机、端口、broker id> 定位 socket tcp 连接。只用broker id定位,无法明确broker,只能创建新连接,造成大量连接
消费进度监控,kafka 监控指标,集成到 zabbix,也可以用 jsonsole 打开。lag,lead 差,判断消费滞后,可以监控到分区级别
Kafka
处理请求 reactor:多个客户端并发向服务器发请求。client dispatch threadpool,
- dispatch:分配分区:轮询,简单避免数据倾斜。
- threadpool:num.io.threads default=8,请求队列线程共享,响应队列线程专享,即 dispatch 只用于请求分发,而不做响应回传。队列分延时队列,等待所有副本写入成功,才将响应放入响应队列。
- 以上是数据类请求,和控制类请求隔离。数据类请求处理收发消息;控制类请求用于获取或变更主题、分区和 Broker。分离原因:设leader中的数据请求已积压,突然收到控制请求,要换leader,则 follower 不再向 leader 拉数据。如果存在”延时等待所有副本写入成功“的设置 acks=all, Leader 副本在处理数据请求时,会等待所有 ISR 列表中的副本写入成功后才确认消息,又 follower 不再向 leader 拉数据,因此,控制请求之前的延时的数据请求都无法正常完成,只能重试直到请求超时返回。控制类请求会直接让数据请求失效!如果kafka 优先处理换leader的控制请求,则 broker 立刻抛异常,快速标识挤压的请求已经失败,这样降低请求处理时间。即使 acks!=all,积压的请求能成功写入 leader 副本日志,但leader 变成 follower,也要执行显示的日志截断 log truncation,即leader 变成 follower 后,会将写入但未提交的消息全部删除。
- 如果使用优先级队列,控制请求优先处理。但问题是,如果优先级队列满,则无法容纳新请求,则即便设置优先级,也无法处理新的控制请求。
- 可以 copy 处理代码,提供不同 listener 配置。
- 直接替换数据队列最前面的数据进行处理,处理完控制队列,再将数据消息插到队头 √
水位,用消息位移表征,水位下的消息是已提交消息,以上是未提交消息,消费者只能消费已提交消息。用于实现kafka 对外消息可见性,实现副本机制。
分区的高水位是leader 的高水位。每个副本都有自己的水位。
reblance
- 触发条件:1. 组成员数变 2. 订阅主题数变 3. 主题分区数变
- 通知消费者实例:消费者定期发送心跳请求到 broker,broker 触发 reblance,通过心跳线程,通知其他消费者实例。heartbeat.interval.ms 心跳的间隔时间,控制重平衡通知频率
- reblance:消费者组状态机,进行状态流转。所有成员退出组后,消费者状态是 empty,这是kafka定期删除过期位移的条件
- 会选出领导者,收集成员订阅信息,分配分区
部署
机器配置
操作系统:Linux
- IO模型:多路复用,在Linux 上交 epoll
- 网速:零拷贝,用于数据流经 磁盘-内核-网络
- 社区支持
磁盘:机械磁盘,成本低,易损坏,√因为顺序存储+软件层面的冗余+分区;固态硬盘,性能好 - 容量:接受数据量1亿/天,大小1k/条。保存2份留存2周,则
- 一天的总空间大小=1亿x1KBx2/1000/1000=200G;预留索引数据等10%的空间,200Gx1.1=220G
- 2周的总空间大小:220Gx14≈3T
- 设压缩比=0.75,则总空间=3Tx0.75=2.25T
宽带 - 设机房千兆网络,即 1Gbps=1Gb数据量/s,每台机器不混布其他服务,假设用到70%的宽带,常规使用1/3的宽带(相当保守),则1台机器的宽带是 1Gbpsx0.7/3=240Mbps
- 若要处理速度1TB/s,即 2336MB/s,则需机器 2336MB/s / 240Mbps=10台
- 若需额外复制2份,则需30台机器
参数配置
when, where, how many
Broker
- 存储路径 log.dirs,目录最好挂载到不同的磁盘;
- 通信:listeners <协议名称,主机名,端口号>;
- Topic:自动创建 Topic ,auto.create.topics.enable=false;unclean.leader.election.enable=false,只有数据多的副部才能竞选 leader;没有数据量多的副本则不竞选 leader;auto.leader.reblance.enable=false,不定期 reblance
- 留存:留存时长 log.retention.{hour|minutes|ms},hour=168 7天;总磁盘容量 log.retention.bytes=-1,或者用于限制租户使用过多磁盘;Broker 能接收的最大消息 message.max.bytes,线上设的大些,不浪费什么磁盘空间
Topic,覆盖全局 Broker 配置 - 留存:留存时长 retention.ms 默认7天; log.retention.bytes 默认-1
- 设置时间:创建或修改√
JVM - 堆大小heap size,6G通用;
- gc,用默认的 G1
操作系统 - 文件描述符限制, ulimit -n 1000000,不浪费什么资源,但容易报错 too many open files
- 文件系统类型,XFS
- swap=1,一旦设置成0,当物理内存耗尽,操作系统会触发 OOM killer,随机杀掉一个进程,没有预警。而设置成小的值,起码能观测到Broker 性能急剧下降,争取到诊断时间
- 提交时间/flush 落盘时间,数据写入页缓存 page cache 算成功写入,操作系统根据 LRU算法将缓存刷到磁盘上,过期时间(提交间隔)默认是5s。可以适当增加提交间隔,降低物理磁盘的写操作,机器宕机数据会丢失,但鉴于Kafka 软件层的冗余机制,可以用大点的提交间隔换取性能。
监控
主题
动态配置
重设消费者组位移
工具脚本
认证授权
跨集群备份
监控
调优
ref:
[1]. Apache Kafka® Architecture: A Complete Guide https://www.instaclustr.com/blog/apache-kafka-architecture/
1 ↩︎