math-basic-know-probability
概率统计
函数将变量间的关系确定下来,方程将未知数确定下来,而概率研究的不确定性中的规律。
随机性导致结果变得不确定。但对于特定的随机事件,结果具有规律性,于是创造了 概率 这个概念 来描述 有规律的不确定性。
| 定义方式 | 概率的本质 | 数学基础 | 适用边界 |
|---|---|---|---|
| 古典定义 | 对称性导致的等可能性 | 组合计数 | 有限、对称结果 |
| 频率定义 | 长期重复的稳定频率 | 极限理论 | 可重复试验 |
| 公理化定义 | 满足三条公理的测度 | 测度论/集合论 | 所有随机现象 |
| 主观概率 | 理性主体的信念量化 | 贝叶斯推理 | 信息不完全的决策 |
拉普拉斯定义概率及计算方法
基本事件:一次试验的每一个可能结果;
- 基本事件有等可能性
==古典定义(先验概率)==公式:P(A)=k/n=事件A所含基本事件的个数/基本事件总数
必然事件:事件A所含基本事件的个数=基本事件总数,即 P(A)=1
掷两个骰子a,b,
n=36,即a=1,b=1~6; a=2,b=1~6 ... a=6,b=1~6;
两个骰子点数加和是5的 个数k=4,即 a=1,b=4; a=2,b=3; a=3,b=2; a=4,b=1; 则 P(A)=4/36=9;
而 点数和为2或12的概率最小,P(A)=1/36;
点数为7的概率最大,P(A)=6/36=1/6
因此,掷两个骰子,点数加和的概率是不一样的
古典概率的漏洞:
- 现实中存在可能性不相等的基本事件
- 为了求概率,先定义了基本事件。但基本事件基于概率来定义。循环定义
- 要先知道 基本事件总数,才能计算一个随机事件的概率。对于预测未来的事,无法列举随机性,如 保险公司无法确定一个60岁的人在未来3年得大病的概率。
伯努利试验-随机性的规律
单词实验(伯努利分布)
随机试验的规律性(概率),与试验结果存在偏差。如,扔一次硬币,正面朝上的概率是1/2,但不能保证,扔N次硬币,事件A=朝上的次数=总次数N*每次发生的概率p=N*1/2;实际上,事件A发生多少次都有可能。那如何解释这种偏差呢?
伯努利试验告诉我们,事件A发生的次数=N*p 的可能性 最大,即 不确定的规律性,只有在大量随机试验时才显现出来,当试验次数不足时,则表现为 偶然性和随意性。
- 频率定义(经验概率):用长期重复试验中事件发生的稳定频率逼近概率,适用于可重复的随机实验。
伯努利试验:每次试验互不影响,只有两个事件 A,
如 掷硬币,两个基本事件,事件A=正面朝上,事件B=反面朝上;
定义:单次随机试验,只有 两种互斥结果:
“成功”(通常记为 1),概率为 p (0 ≤ p ≤ 1)
“失败”(通常记为 0),概率为 1-p
概率函数 (PMF):
或等价写为:
- 为什么是乘积? 独立 ⇒ 横条和竖条互不干扰 ⇒ 重叠区变长方形 ⇒ 面积 = 长 × 宽 ⇒ 乘法公式成立。
- 为什么指数形式?
k次成功(每个概率p)和n-k次失败(每个概率1-p)的连乘简写。
概率是“测度”——它把“事件”变成了可以像长度、面积一样去量、加、乘的几何对象;
- A∪B 对应两段线段的 总长度。
- A∩B 对应两段线段的 重叠长度。
- 当 A、B 独立时,重叠面积 = 各自长度相乘:P(A)·P(B)。 独立 ⇒ 横条和竖条互不干扰 ⇒ 重叠区变长方形 ⇒ 面积 = 长 × 宽 ⇒ 乘法公式成立。
- 用面积模型表示 事件的 权重,概率。
- 我们发现,几何面积能优雅地处理连续随机现象;面积“转正”为概率的度量。
用面积算概率,是因为它同时满足公理、经得起大数定律检验、又能被实验测量;三者缺一,就不合适。
-
公理系统:面积天然满足三条
• 非负:面积 ≥ 0
• 归一:整个蛋糕面积 = 1
• 可数可加:把互不相交的若干块面积加起来,总面积 = 各块面积之和
这正好是 Kolmogorov 对概率的公理化定义。
换句话说,面积模型是公理的一个具体实现;换别的模型,只要也满足这三条,照样合法,但“面积”最直观,于是大家默认用它。 -
频率稳定性:面积 ≈ 长期频率
做 n 次独立实验,事件出现的次数 k/n 随 n 增大几乎必然收敛到 P(A)。
如果面积模型算出来的 P(A) 跟 k/n 不一致,我们就弃用这个面积切法。
因此面积不是随意画,而是被实验数据“校准”出来的。 -
实际可测性:面积必须能被测量
事件必须对应实验中可以分辨的结果集合;
面积必须对应我们能在现实中“数”或“量”的东西(计数、长度、体积、时间占比……)。
若某事件无法被任何仪器反复观测,我们就无法给它分配面积,模型也就失效。
重复试验(二项分布)
人们不只关心单次试验,更关心 重复 n 次独立试验中的总成功次数 X(如抛 10 次硬币出现正面的次数)。
关键假设
- 独立性 (Independence):第
i次试验的结果不影响第j次。 - 同质性 (Identical Distribution):每次试验成功概率恒为
p。
伯努利通过试验发现,N次试验,事件A的次数符合二项(每次试验有两种结果)分布。
抛掷一枚硬币,重复10次,恰有5次正面朝上的概率
X服从二项分布,记作 X~B(n,p),形式为
- 组合数
,从 n 次试验里选出哪 k 次是成功的,共有多少种选法。 ,选出的这 k 次都成功,每次成功概率为 p,连乘 k 次。剩下的 次都失败,每次失败概率为 ,连乘 次。每条路径(每种选法)的概率(由<独立性,联合概率等于边缘概率乘积> 和 同质性保证)
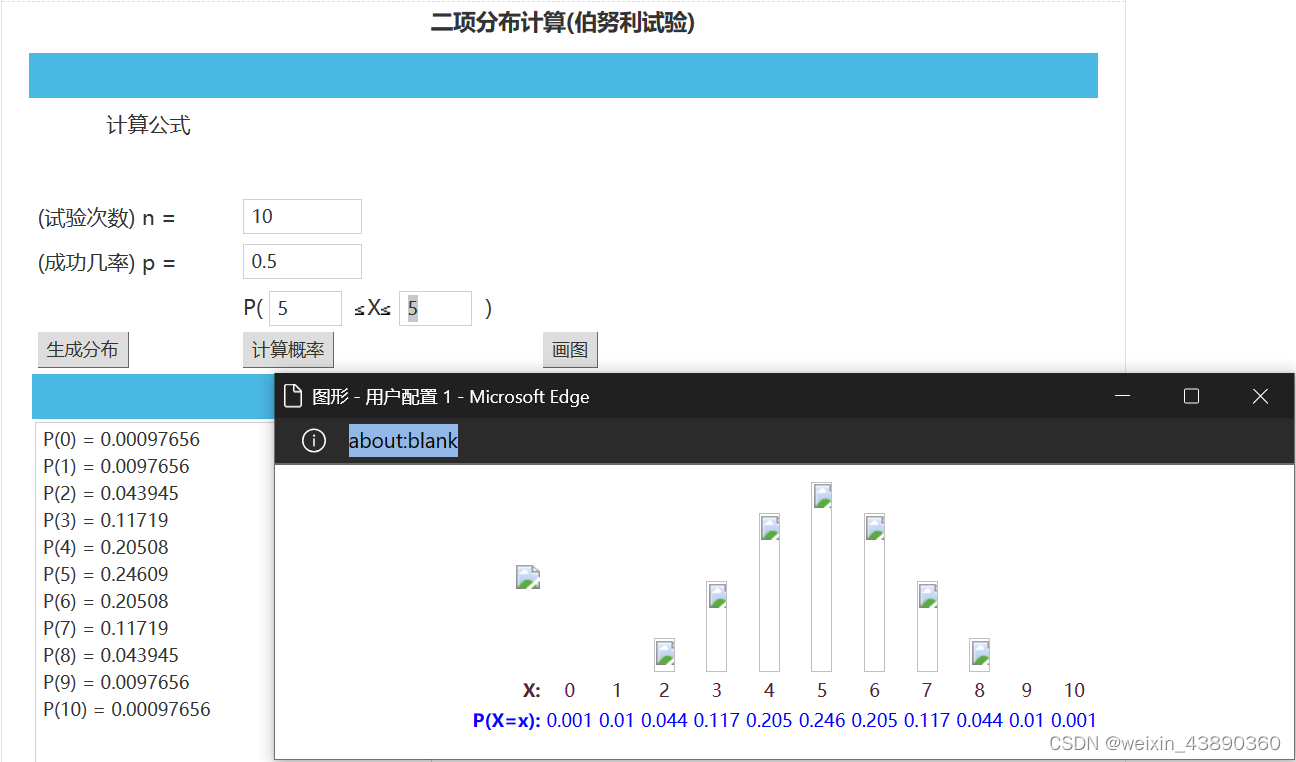
二项分布计算(伯努利试验) - 常用计算器 - 微波射频网 (mwrf.net)
重复100次试验,会发现,80%的情况下,正面朝上40~60次。
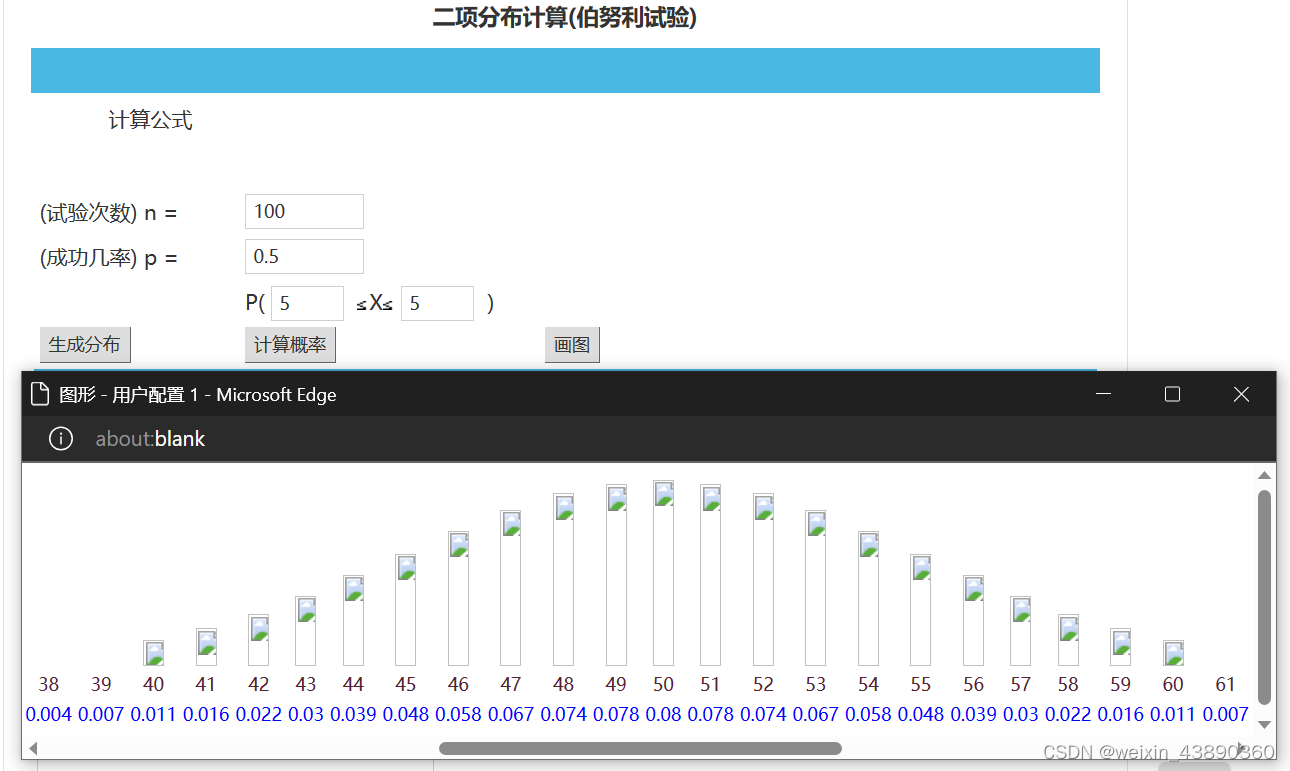
如果继续放大试验次数,会发现,正面朝上的次数在一半左右浮动。正面朝上占比特别少或者特别多的可能性很小,不像一开始那样什么情况都有可能。
定量描述偏差:
- 平均值(数学期望、期望值,理论上的平均次数):N*p,N次试验概率是p的事件A,平均发生的次数,也是最有可能发生的次数。随着试验次数的增加,实际发生的次数会越来越接近这个理论值
- 平方差(方差):度量 与平均值的误差,误差做一个加权平均
- 标准差:简单理解为 方差开根号
试验次数越多,误差越小,方差和标准差越小,概率分布越集中在 平均值上
100次试验 标准差=5,平均值=50,10%的误差;
10000次试验 标准差=50,平均值=5000,1%的误差;
因此,越是小概率事件,如果想确保它发生,需要重复次数足够多。
提高单次成功率,比多次试验更重要。凡事做好准备,争取一次性成功,远比不断尝试更靠谱。
泊松分布
特殊伯努利试验-泊松分布:事件A发生的概率很小,但试验次数n很大;如发生车祸的情况。
用一个“栗子”讲透让人迷惑的泊松分布_泊松过程 无限小的时间段-CSDN博客
定义:事件A发生的概率是p。n次独立试验,发生了k次,则
P(X=k)=
泊松分布,描述单位时间/空间内稀有事件发生次数的概率分布
- 事件平均发生的次数=事件发生次数的离散程度(波动大小)。
- 面对 λ 小的事件(如罕见故障),要警惕其 “发生次数少(均值小),但波动/不稳定极大(与均值相当)” 的风险;
公司100个人,10个停车位,每个员工早上8点前开车来上班的概率是10%,那么8点停车场还有车位的概率是多大?
-> 开车上班的员工数少于等于 9 人的概率

泊松分布在线计算工具,在线计算,在线计算器,计算器在线计算 (osgeo.cn)
如果增加3个冗余车位, 8点停车场还有车位的概率上升到80%
->开车上班的员工数少于等于 12 人(即X≤12)
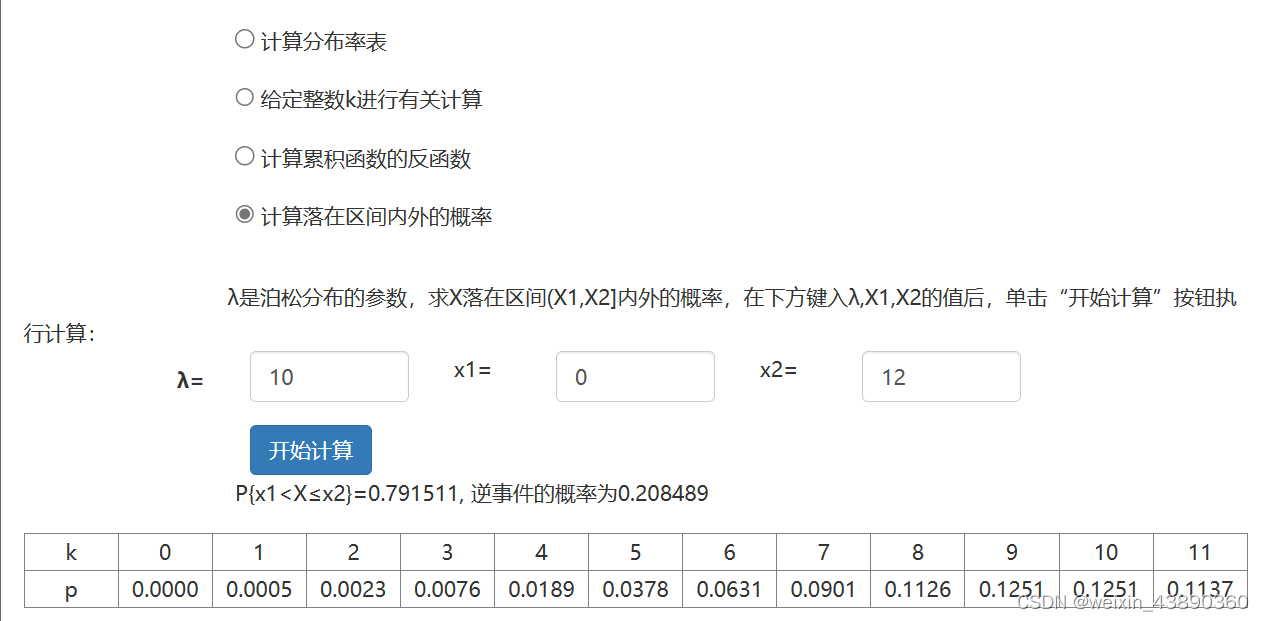
因此,冗余增加的数量并不多,却能解决大问题。
公司40个人,4个停车位,每个员工早上8点前开车来上班的概率是10%,那么8点停车场还有车位的概率是多大?

因此,试验次数越大,越能抵消随机性带来的误差
高斯/正态分布
大概率事件(概率>1/2),试验次数大
很多变量接近于正态分布:
- 人群的身高
- 成年人的血压
- 员工回家所需的时间
正态分布特性:只用 均值和标准差 就能解释整个分布,
正态分布密度图中, - 均值是曲线的中心,是曲线的最高点,大多数点都在均值附近
- 均值左右曲线对称
- 曲线内的面积,是所有值的概率和=1
- 如果一个随机变量的取值符合高斯分布,
- 如果标准化相同,两个正态分布的函数形状相同,标准化差小则高瘦
有68%的可能性,动态范围在平均值+-标准差 内;
95%的可能性,动态范围在 平均值+-2*标准差 内;(随机性的结论只需要 95%)
99.7%的可能性,动态范围在 平均值+-3*标准差 内
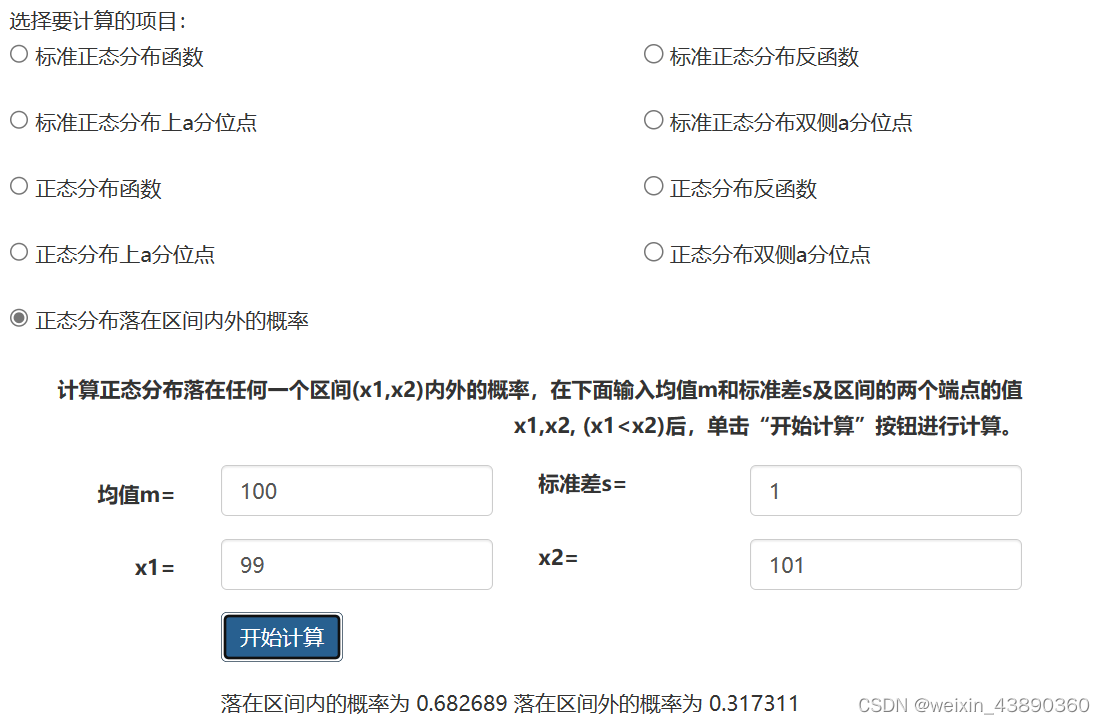
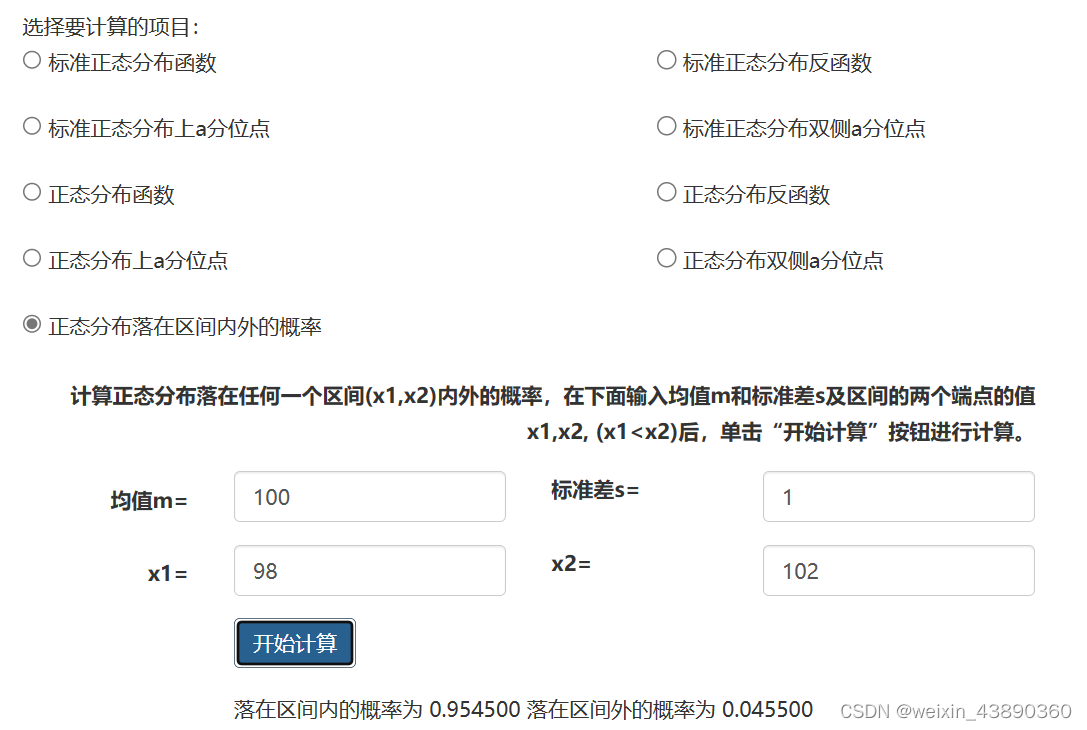
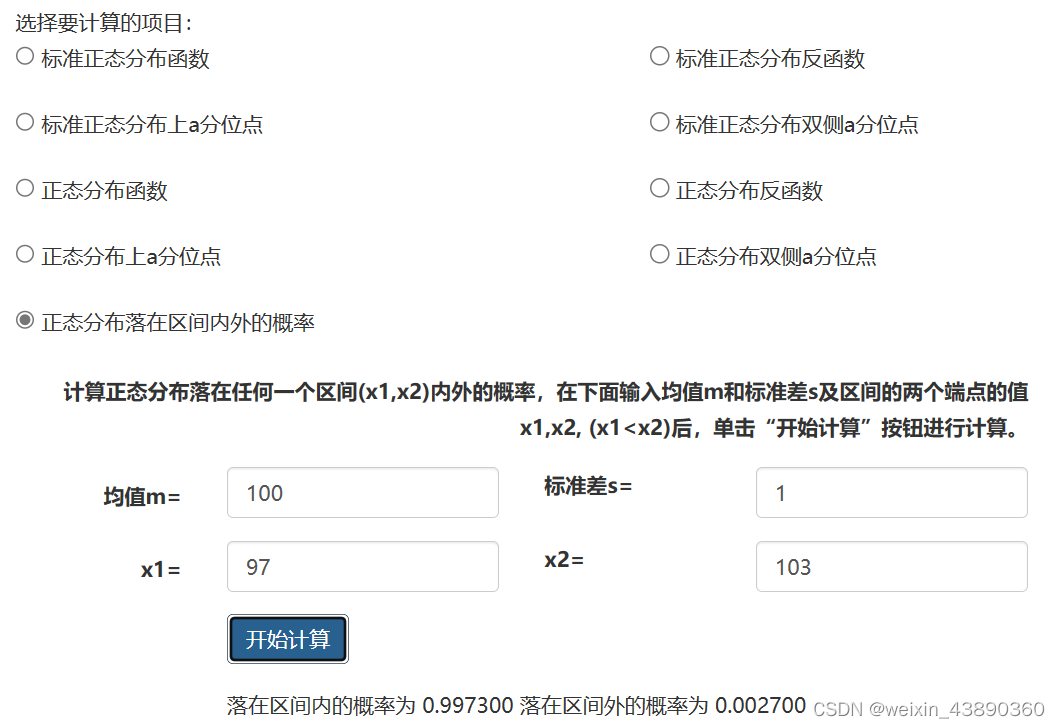
举例说明 均值、标准差和发生概率的关系:
两个班级的成绩。一班成绩在60~100分之间,均值是80;二班成绩在70~100分间,均值是85;其正态分布图如下:
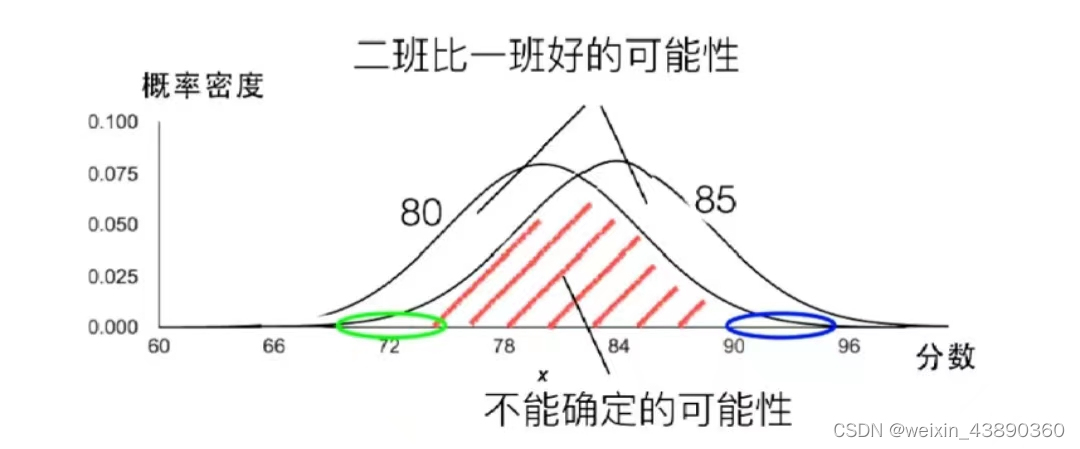
一班有一个小概率的可能性>90分,蓝色区域;二班也有一个小概率的可能性<75分。有多大的把握说,均分85分的二班一定比均值80分的一班强呢?要看两个班成绩的平均浮动范围,即标准差。
设,两个班的标准差都是5分。
使用两个独立正态变量的差值分布计算
- 定义差值
。 - 由于
和 独立: - 均值
- 方差
,标准差
- 均值
- 所以
。 - 求
: - 标准化:
- 标准化:
- 利用标准正态分布的对称性:
- 查表或计算:
- 插值:
- 因此,
(即76.02%),二班比一班成绩好的概率是 76.02%。
同时,对于样本均值,我们可以通过t分布获取其置信度下的置信区间。增加样本数量,可以扩大置信区间。要增加样本数量,可以增加统计人数,或者增加考试次数。
条件概率和贝叶斯公式
前面的试验都是独立的,条件概率讲 特定条件下的试验发生的概率,即条件概率。
条件概率由于条件的存在,其值不是 通常情况下的概率。一旦具备条件,有些大家认为不可能的事,就成了大概率事件。
如何计算条件概率?
在条件X下,1件事Y发生的条件概率P(Y|X)= 条件X和事件Y一同发生的联合概率P(X,Y) / 条件X的概率P(X),即
P(X,Y)=P(Y|X)*P(X)=P(X|Y)*P(Y)
联合条件概率比较难求,通常由 易求 推导 难求,设P(X|Y)易求,则P(X,Y)=P(X)*P(Y|X)=P(Y)*P(X|Y),P(Y|X)=P(Y)*P(X|Y)/P(X)
- 源语言句子
:“I went to the bank to withdraw money.” - 可能的目标语言翻译
:“我去了【银行】取钱。” - 可能的目标语言翻译
:“我去了【河岸】取钱。”
用条件概率计算和 ,选概率更高的那个。
主观概率贝叶斯定理提供了一种将条件概率 P(Y∣X) 分解为 翻译模型 P(X∣Y)和 语言模型P(Y)的方法。可以独立训练两个模型,最大化 P(X∣Y)⋅P(Y),综合翻译的准确性和语言的自然性,找到既符合中文语法语义的句子Y,又符合英文句子的X,达到最优翻译。
根据贝叶斯定理,
- P(Y):先验概率(初始信念)。
- P(Y∣X):后验概率(观察到证据 X 后的更新信念)。
关键看两部分:
(1)翻译模型
:“我去了银行取钱”翻译成英文时,“银行”对应“bank”的概率很高(因为在金融场景中,“银行”和“bank”是常见对应)。 :“我去了河岸取钱”翻译成英文时,“河岸”对应的英文是“riverbank”或“shore”,和“bank”对应的概率很低(很少有人会去河岸取钱)。
(2)语言模型,Y的先验概率/边缘概率:句子合理性,语言模型(可通过马尔可夫模型计算出来),目标语言译句本身合理(符合语法和语义)的概率。 :“我去了银行取钱”是符合中文语法的常见表达,通顺度高。 :“我去了河岸取钱”虽然语法正确,但语义不符合常识(河岸不是取钱的地方),所以 很低。
注意:
最终结果:因为
翻译模型和语言模型的结合可以有效地捕捉翻译的双向性质。但并不意味着最佳的正向翻译也是最佳的反向翻译,因为语言之间的词汇、语法存在天然差异;只是模型在学习正向的同时,也在学习如何反向翻译,有助于模型更好的理解和生成自然语言。
概率公理化
定义概率论
- 样本空间:一个随机实验所有结果的集合。
- 结果 → 样本空间 Ω 的元素,随机试验的最小不可再分的观测值,ω ∈ Ω。(e.g., 掷骰子得到"1")
- 事件 → Ω 的子集,结果的集合(e.g., "得到奇数" = {1,3,5})。
- 集合,样本空间 Ω 的子集的集合,包含:
- Ω 本身(必然事件),
- 空集 ∅(不可能事件),
- 函数,为每个事件分配一个值(概率)。
公理化定义把概率看作事件集合到[0,1]区间的特殊函数,只要函数满足三个公理,则称为 概率函数。
- 非负性:任何事件的概率是在 [0,1] 之间的一个实数
- 规范性:样本空间的概率为1
- 可加性,互斥事件相加:如何两个随机事件A,B互斥,即A发生则B一定不发生,则 事件的概率=A发生的概率+B发生的概率
效果:兼容古典定义和频率定义(前者是离散均匀测度,后者由大数定律保证)
基于公理,推导定理:
- 互补(A发生和A不发生)事件的概率和=1 公理2+公理3
- 不可能事件的概率=0 定理1,两个互补事件合在一起就是必然事件,必然事件的概率是1,必然事件与不可能事件互补,则不可能事件的概率必须=0
大数定理
理论计算出的概率,和大量统计得到的结果一致。正是有这种一致性,大数据方法才有了理论基础
统计学和大数据
统计学,是一门关于收集、分析(数据规律性、因素相关性)、解释、陈述数据的科学,用于预估未来的变化和发展。
大数据使用误区:
- 霍桑效应:被观察者知道自己成为被观察对象,而改变行为倾向的反映。
- 数据稀疏带来副作用。
- 因果反用
用好数据的五个步骤:
- 设立目标,确认你的假说,否定备用假说。避免盲目使用数据,有意识地过滤数据中的噪音
- 设计试验,选取数据。数据需要便于量化处理。
- 根据试验方案进行统计和实验,分析方差。
- 分析,提出新假说。
- 使用研究结果。将统计结果用于产品,也报告给别人。
古德-图灵折扣估计
黑天鹅事件的发生,就是错将小概率事件看作零概率事件。
小概率事件特点:
- 二八定律:多数情况下,80%的结果来自于20%的原因
- 词频分布特性:一个词的排位(词频排名) * 词频(词在文本中出现的次数) ≈ 常数;词频 * 相同词频的词的数量 ≈ 常数
解决方法一:古德-图灵折扣估计 解决零概率事件。通过给高频词打一个折,多出来的词频给到低频词。
解决方法二:插值法,小概率事件估计不准
零和博弈
博弈:研究竞争中的最优解。会考虑到多方策略。最优策略是平衡。
最优解:在对方给我们造成最糟糕的局面种,选择相对最好的. 这被成为最小值中的最大值策略
零和博弈:双方利益互斥,一方所得必然是另一方所失。
问题1:双人博弈的下棋问题
设 X,Y两个人下围棋.X要走下一步棋,有方法 x1,x2,x3;Y 有方法 y1,y2,y3;X 的胜率,就是Y的输率
两个人的策略有3x*3y=横x竖=9种组合方式,写成一个3*3矩阵
当X采用x1策略,考虑对方应对,
- 如果Y采用y1策略,X的胜率会增加7点;
- 如果Y采用y3策略,X的胜率会减少10点.
若根据目标,X选择策略:最小值中的最大。则X1 在最糟糕的结果中(每行最小),-10,1,-4,选择最大的1,即x2策略
若根据目标,Y选择策略:最大值中的最小,则从 -7,-1,-4(每列最大),选择最大的-1,即y2策略
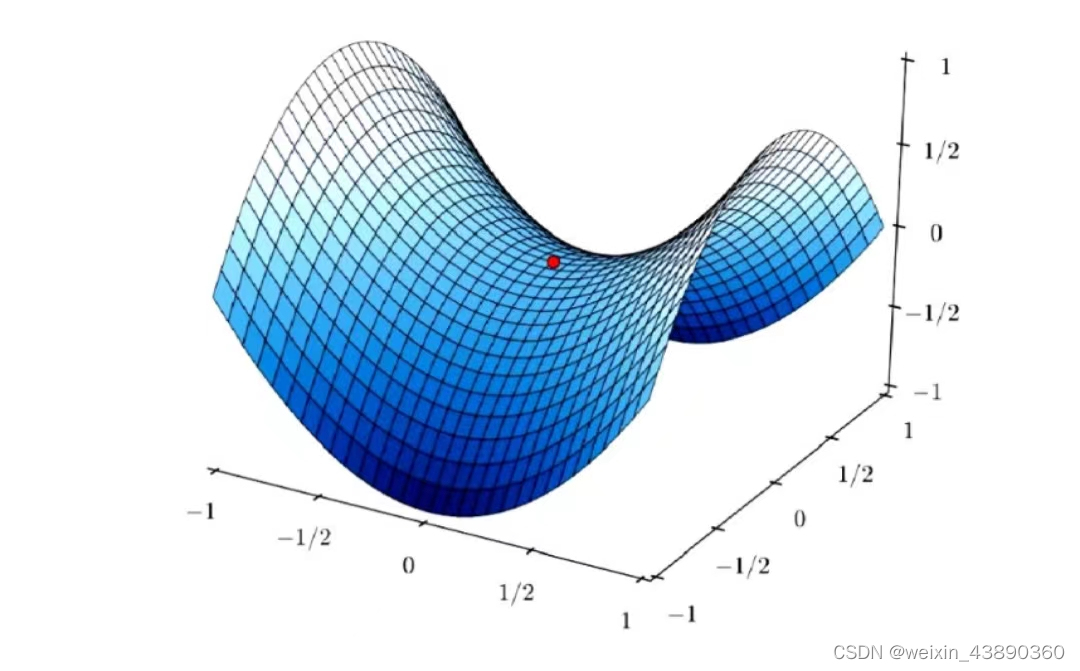
平衡点:X、Y理性时,矩阵 (2,2)位置,第2行的最小值第2列的最大值,是对双方来说最好的点。
上述矩阵,画在一个三维图形中,就是一个马鞍形。马鞍点就是(2,2),即在X看来,它是最低点中的最高点,在Y看来,是最高点中的最低点。
简单的马鞍图如下,红色点是马鞍点
设X知道自己行棋后,Y采用 y1,y2,y3 的概率是 70%,20%,10%,则X采用x1策略是最好的。知道对方走过每步棋后,需要重新计算平衡点。
问题2:多人博弈的投篮问题:
设10个选手投篮,投篮的准确性和篮筐的距离有关,离篮筐越近,准确性越高。现有比赛规则,第一个选手站篮筐9米处,如果投进,就是赢家;否则,第二个选手站篮筐8米处,如果投进就是赢家... 直到0米,一定投中。按此规则,第几个出场,获胜率最大?
要看命中率和距离间的关系。设命中率是1/(投篮距离+1),
9米远,命中率是 1/(1+9)=1/10
8米远,命中率是=他的命中率* 第一个人失败的概率= 1/(1+8)*0.9=1/10
由此,每个人获胜的概率都是1/10
如果命中率=1/(投篮距离+1)^2,就是最后一个出场的人获胜率最大。
非零和博弈
非零和博弈是双赢。
囚徒问题:设囚徒X,Y 一起作案被抓,要定罪。为防止串供,将两人分开审讯。如果两人都认罪,刑期5年;如果一个认罪,另一个抵赖,则认罪释放,抵赖判10年;如果两人都不认罪,都判1年,那么,X,Y应选择认罪还是抵赖?
(X,Y) 认罪 抵赖
认罪 (-5,-5) (0,-10)
抵赖 (-10,0) (-1,-1)
考虑最坏情况下的最好结果,则两人都抵赖,是双赢结果。需要对方彼此信任。
因此,囚徒策略一直被用来证明 双赢的可能性。但现实生活中,双赢的概率很小。
智猪问题:按1下按钮,食槽+10磅猪食,猪-2磅成本。如果一只猪跑去按按钮,再转身去食槽,一些猪食会被另外一只猪抢吃掉
净收益:
(大猪,小猪) 按按钮 食槽旁等待
按按钮 (5,1) (4,4)
食槽旁等待 (9,-1) (0,0)
无论大猪是否按按钮,小猪的最佳策略就是等待。大猪按,小猪1,4√;大猪不按,小猪-1,0√;
如果大猪等待,虽然可能获得9磅收益,但如果小猪也等待,则双方所得都是0,因此大猪最小值中的最大值策略是按按钮,至少可得4磅收益。而小猪策略应该是等待,这样结果能达到双赢,是双方博弈的均衡点,是稳定的。
- 均衡点指的是博弈的稳定状态,即在该状态下,没有任何一方有动机单独改变其策略,因为改变策略不会带来更好的结果