model-invoke-langchain
项目案例:
- 致谢:sheishituanziya/LangChain-DeepSeek-Practise: This project is a series of practical examples based on the LangChain framework and the DeepSeek API, incorporating the latest open APIs from DeepSeek to demonstrate a range of applications from basic to advanced levels.
- 延伸:https://github.com/314yang/LangChain-DeepSeek-Practise
支持 python(pip install) 和 javascript(npm install)。
功能:一个框架,便于用语言模型开发应用。扩展模型的问答调用。python版本 可用 Pydantic 数据校验,利于功能稳定性
chain -> agent -> tool:question_answer_messages(rag /prompt / 内存/持久化)- model(function calling模型自定义/mcp通用)- output_parcer
- chain:固定流程,逻辑控制,Input → Model → OutputParser
- agent:动态流程,组合工具调用,Input → 决策 → 调用 Tool → 决策 → 输出
适用于多模型交互场景:模型切换,交互,对比最优。
相关框架:Agentic AI: 开源框架(CrewAI AutoGen 、LangGraph、Agno、Pydantic AI 等)对比 | AI智能践行 | 2025年04月19日 19:31:我们都听说过 CrewAI 和 AutoGen,但你知道吗,现在有几十个开源的智能代理框架 — 其中许多是在过
封装问题:
- 模型、工具兼容性问题,维护成本高。大模型迭代快,接口参数变动时,Langchain 的封装不支持模型原生接口, 导致不适应新特性。
- 执行流程间的组件交互不直观。代码量多,深层嵌套,难以阅读。
- 默认参数不开放配置,难以扩展。
其他建议:
- Dify:内置AB测试模块,支持分布式系统追踪;工具有限。
- 基于知识图谱来构建大模型,以更好地匹配知识和答案。
- AutoGen:可与LangChain集成;擅长代码任务的多智能体编排,能从Google Search、网页抓取、向量存储等来源收集数据。
- Kani:更轻量。专为基于聊天的语言模型和功能调用设计
- LlamaIndex:专注于文档检索 RAG。依赖外部agent框架。
- AutoGPT:能够自动生成任务并自主执行,以实现特定目标,如智能助手、自动内容生成等,但可能需要更多的人工干预和调整。
相关概念:
- 模型 model:
功能
模型调用
封装(扩展)模型调用,实现模型问答。
模型单次调用,如langchain_deepseek/chat_models.py at master · langchain-ai/langchain-github
- 创建模型实例
- 答answer_messages =调用模型(问questionmessages,工具)
- 调用方式
- 请求:同步、异步;
- 响应:流式
- 消息,可结构化
- 调用方式
模型多次、组合调用 -> 调用链chain,串联方式有 表达式语言LCEL(逻辑简单) 或 LangGraph(逻辑复杂,运行时可视化)。
以LCEL 为例,支持的逻辑有:
- 顺序
|,如 问答的基本语法是chain = prompt | model | output_parser - 并行
RunnableParallel({ , }) - 分支
RunnableLambda( if - else )
历史(上下文)对话,内存存储/持久化:存储用户输入和模型输出。
- 可持久化(自己的数据库如 PostgresSQL,可自动建表,需确认索引,也可手动建表)
- 通过(与模型会话的)session_id 查询,
工具调用
- @tool 自定义工具,或实例化内置工具。
agent= create_react_agent(tools=tools,model=llm)组合模型与工具。- 可从 模型响应
response查看工具调用情况。
Prompt
写了一个月的 prompt,体会是什么? | AI 产品自由 | 2024年11月14日 08:44
- prompt = 流程化(拆分,不重不漏)+用词具体(最小可执行、评价指标)、精准(高度依赖场景,如灰姑娘-
毒苹果而不是坏苹果) - cursor 是好的文本编辑器,预测用户意图 → 提供选项 → 用户确认。伪需求?能预测出来的,是必要但不重要的?
AI Prompt 工程师认证&学习指南 - Datawhale x 讯飞星火
- 可以让模型生成提示词。
# 简单理解:你是具备__技能的__专家,要完成__目标。必须满足__标准,绝对不能__。
# [任务名称] 提示框架
## 1. 核心定位
专业角色:`<领域>+<专业身份>(如:教育领域高校咨询师)`
任务边界(上下文背景):`<任务相关环境/约束条件/前置信息如数据源>`
核心目标:`<数量><单位时间内>达成<KPI><可量化的具体目标,用SMART原则描述>`
## 2. 行动架构
主行动线:
- 阶段1:`<需求解析>` → 交付物:`<指标确认清单>`
- 阶段2:`<数据验证>` → 交付物:`<关键产出,如可信数据源标记>`
- 阶段3:`<结构化输出>` → 交付物:`<最终成果>`
扩展模块(按需启用▼):
▨ 限制条件:`[格式/风格/禁忌/目标受众等要求]`
▨ 示例系统:`[正例/反例/对比样本]`
▨ 流程控制:`[里程碑节点/检查机制]`
▨ 思维引导:`[分析框架/质疑角度]`
▨ 个性调节:`[语气/情感/拟人化程度]`
▨ 迭代机制:`[优化标准/版本对比]`
✓ 权重优化:`[[自动校准指标权重]]`
✓ 决策辅助:`[[提供选择建议公式]]`
## 3. 输出规范
格式要求:`<结构化呈现>+[[可视化建议,如雷达图/柱状图]]`
质量维度:
- 准确性:`<误差容忍度>`
- 完整流畅性:`<必须覆盖的要素>`
- 创新性:`<差异化要求>`
避雷指南:`<绝对禁止事项>`
## 4. 动态适配
▶ 简单任务:执行`主行动线阶段1` + `基础输出规范`
▶ 中等任务:启用`1-2个扩展模块` + `全阶段行动线`
▶ 复杂任务:激活`全模块协同` + `多轮迭代验证`
使用说明:关键融合逻辑:
- 分层嵌套设计
- 基础模块作为必选主干(1-3章)
- 扩展模块作为可折叠/展开的插件(2章扩展部分)
- 动态适配指南实现复杂度可视,控制资源投入(4章)
- 符号化标记系统,降低认知负荷
▨表示可选模块开关,✓表示必须使用的模块▶提示复杂度适配策略→显示行动与成果的因果关系[[ ]]是可扩展的智能填充内容
- 结构化占位符
- 用
[ ]标注需要自定义的内容类型 - 用
< >定义内容填写规则 - 用
""包裹示例说明(实际使用时可删除)
- 用
应用示例(商业分析报告):
# 行业竞争分析提示框架
## 1. 核心定位
角色定义:资深战略咨询顾问
上下文背景:新能源汽车市场,客户为二线电池制造商
核心目标:3天内输出包含3个差异化战略的可行性报告
## 2. 行动架构
主行动线:
- 阶段1:收集TOP5厂商技术专利 → 交付物:专利对比矩阵
- 阶段2:构建SWOT-PEST模型 → 交付物:机会风险热力图
- 阶段3:设计蓝海战略方案 → 交付物:战略路线图
扩展模块:
▨ 限制条件:"禁用专业术语,用比喻解释技术概念"
▨ 示例系统:"参考宁德时代2023出海战略白皮书第5章"
▨ 思维引导:"先用波特五力否定前两个方案,再生成第三个"
## 3. 输出规范
格式要求:PPT故事板+Excel数据包
质量维度:
- 准确性:市场数据误差≤2%
- 完整性:必须包含成本测算模块
- 创新性:提出至少1个跨界合作模式
避雷指南:不提及友商未公开的财务数据
## 4. 动态适配
▶ 本次任务复杂度:中等 → 启用3个扩展模块
延伸
更多参考:
Prompt Library | DeepSeek API Docs
f/awesome-chatgpt-prompts: This repo includes ChatGPT prompt curation to use ChatGPT and other LLM tools better.
例子:prompt-case
RAG
RAG:先检索相关知识,再基于检索结果生成回答,提高结果的准确度。
- 评估 RAG 应用程序的性能以了解其优缺点至关重要。为此,我们有如 RAGAS、Giskard、Trulens 等库。
流程:数据源加载 load-> 长文本分割 split -> 用embedding模型实现 txt2vector ,并进行向量存储store -> 检索 retriever -> 问答链QA chain
- 分割方法包括基于字符、句子、段落、语义和滑动窗口的分割。
- 向量存储:
vectordb = Chroma.from_documents(documents=splits,embedding=embedding,persist_directory=persist_directory)- 数据库用
Chroma;保存在本地磁盘persist_directory
- 数据库用
- 问答链:
qa_chain = RetrievalQA.from_chain_type(llm=llm,retriever=vectordb.as_retriever(),chain_type="refine",verbose=True)- 用问答链调用模型:
result = qa_chain.invoke({"query": question})
- 用问答链调用模型:
【RAG技术实战】-- 18种RAG技术测评(part1-11种方法对比) | AI智能践行 | 2025年03月20日 21:48:这几天一直想做一个工作测试所有rag的效果,但是鉴于不同框架实现可能导致效果评测有差异。
- 【RAG技术实战】-- 18种RAG技术测评对比(part2-7种方法对比) | AI智能践行 | 2025年03月22日 20:30:Self RAG(自反检索增强生成)到目前为止,我们的RAG系统主要是被动的。它们接收查询,检索信息,然后生成响应。本文对18种RAG技术进行测评对比分析。
- https://github.com/FareedKhan-dev/all-rag-techniques
- 自适应RAG:自动对查询分类(精确事实、主题分析、主观问题的不同观点、上下文),选择合适的检索方法。
evaluate_system_prompt
# Define the system prompt for the evaluation system
evaluate_system_prompt = "You are an intelligent evaluation system tasked with assessing the AI assistant's responses. If the AI assistant's response is very close to the true response, assign a score of 1. If the response is incorrect or unsatisfactory in relation to the true response, assign a score of 0. If the response is partially aligned with the true response, assign a score of 0.5."
# Create the evaluation prompt and generate the evaluation response
evaluation_prompt = f"User Query: {query}\nAI Response:\n{ai_response.choices[0].message.content}\nTrue Response: {data[0]['ideal_answer']}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### OUTPUT ###
... Therefore, the score of 0.3 being not very close to the
true response, and not perfectly aligned.
# auto rag output
### === 评估自适应检索与标准检索 ===
从 PDF 中提取文本...
对文本进行分块...
创建了 42 个文本块
为文本块创建嵌入向量...
将 42 个文本块添加到向量存储中
#### 查询 1:什么是可解释人工智能(XAI)?
##### --- 标准检索 ---
##### --- 自适应检索 ---
查询分类:事实性查询
针对“什么是可解释人工智能(XAI)?”执行事实性检索策略
增强后的查询:可解释人工智能(XAI)在机器学习和深度学习中有哪些关键应用和技术?
##### --- 检索结果 ---
**标准检索结果**:根据提供的上下文,可解释人工智能(XAI)是一套旨在使人工智能决策更易于理解的技术,使用户能够评估其公平性和准确性。XAI 的目标是……
**自适应检索结果**:可解释人工智能(XAI)是人工智能(AI)的一个子领域,旨在使人工智能系统更加透明和易于理解。XAI 的主要目标是……
### === 评估结果 ===
xxx( natural language desc)
RAG不需要切块向量化了?通过PageIndex构建Agentic RAG! | kaggle竞赛宝典 | 2025年04月23日 22:30:你是否对长篇专业文档的向量数据库检索准确性感到失望?传统的基于向量的RAG系统依赖于语义相似性而非真正的相关性。
- PageIndex文章转成树结构+LLM Judge;不适合多文档。
- RAG是检索+排序 √
向量数据库:Milvus、Faiss
fastgpt
Fastgpt结合Ragflow构建本地表格知识库,效果拉满!【喂饭级教程】 | 袋鼠帝AI客栈 | 2025年03月15日 00:58:又是一个互补组合
- excel而不是markdown,ragflow
- 合并列,一个分类放在一个块 chunk 中。
- ragflow非常吃资源。内存需求是fastgpt和dify的4倍;CPU是fastgpt和dify的2倍
例子
如何在Java中基于LangChain编写大语言模型应用_编程语言_InfoQ精选文章
概念解释
- 语言模型是自然语言的概率模型,生成一系列单词的概率。
- 用数据和算法训练机器,寻找规律进行预测。用微调(基础)、思维链(多角度慢思考)、提示工程(增强上下文)、rag(词嵌入),提高特定任务的准确度。
- rag 词嵌入,用 word2vec glove等算法,编码单词含义,输出值是实数的向量
- 语言模型可以实现语言翻译、内容摘要、和内容创建,在问答应用中非常有价值。
- 更多:ai-intro
Langchain+DeepSeek R1从入门到精通 | 矩阵空间 | 2025年03月02日 11:40:Langchain+DeepSeek R1从入门到精通,最后FastAPI、Vue3、Flutter,可以打造 AI 助手应用。
- 功能基础案例,有代码
机器学习 | LangChain框架快速入门 | 古月居 | 2024年11月10日 17:20:本文将会介绍LangChain框架,并以python代码示例来解释该框架的作用。
- 功能基础案例,有图
DeepSeek & LangChain:“模型+框架”的AI测试融合实践!超全面 | 51Testing软件测试网 | 2025年03月14日 17:31:来领~书~啦~
- 测试用例格式化
- 自动化:自然语言 -> 大模型 -> Selenium脚本 -> 调用 Selenium 执行
- 日志分析:日志 -> 大模型 -> 异常类型、高频错误关键词、修复建议
基于千问+LangChain构建垂直领域大模型应用:电商场景实际案例 | 编程与架构 | 2025年03月26日 08:04:关注下方公众号,获取更多热点资讯基于千问+LangChain构建垂直领域大模型应用
- 电商客服投诉信息的结构化处理,使用 Pydantic进行数据验证
RunnablePassthrough.assign(text=lambda x: x["text"]) | prompt | model.with_structured_output(schema=Complaint):从字典提取文本;填入模板;调用模型,格式化为Complaint- 可迁移到 医疗问诊信息结构化
# 输入
test_text = """我的订单号ORD202405019876,上周买的充电宝到货后发现外壳有裂痕,几乎要漏液了!
这种危险品必须立刻处理,需要全额退款并赔偿!"""
# 输出:
response = process_complaint(test_text)
{
'success': True,
'data': {
'order_id': 'ORD202405019876',
'issue_type': '商品质量',
'user_request': '全额退款并赔偿',
'urgency_level': 5
}
}
17. 利用LangChain让AI做决策 | 坍缩的奇点 | 2023年06月19日 06:50:Hi,大家好。我是茶桁。在第 11 讲中,我向您介绍了如何将各种资料内容向量化,借助Llama-index建
- 电商领域,导购,在途物流,FAQ,用 LLMChain “分而治之”,让AI选相应的工具,设置AI 最大重试次数,转人工。
- 导购:存储商品信息到 VectorStore(FAISS)中,通过先搜索后问答的方式解决。
- 在途物流:用工具,先自己查订单号,超出次数,向用户询问订单号
那些很火的基于LangChain的优秀AI原生项目 | 山行AI | 2024年08月27日 17:55:本文主要内容是一个LangChain资源库,里面罗列了大大小小很多个基于LangChain框架的优秀项目,包括低代码、服务、代理、模板等工具类,还有像知识管理、聊天机器人等开源项目,还包括像视频、文章等AI学习资源
- 项目集合(略)
收费:日志追踪及系统监控框架LangSmith | Agent笔记 | 2024年08月17日 10:50
- langchain 的日志链路,商用
dify
dify - 飞书云文档:本项目是基于dify开源项目实现的dsl工作流脚本合集.
dify实现分析-rag-文档切割的实现(done) | 大数据架构师修行之路 | 2025年03月01日 08:41:本文介绍了dify中文本分割的几种方式。并对这几种方式的实现进行了分析和比较。文本分割是,RAG框架实现中比较关键的一环,分割质量的好坏直接影响RAG回答的效果。dify中考虑到了文本的长度和语义的连贯性,会对小的分块进行合并,而且又会保证
- 竞品 dify
wan-h/awesome-digital-human-live2d: Awesome Digital Human
- dify 集成数字人。本项目将 dify 看作 agent,接入 difyAgent 实现 LLM 调用
- 浏览器显示的数字人,Live2D制作;语音文字转换(语音2文字叫ASR,文字2语言叫TTS),默认用google的遗弃免费接口。
工具选择:ReAct框架
Agent 使用 ReAct框架(一种 prompt),组合模型推理,实现工具选择。
工具选择,在面对一个功能的系列决策时,增加了自主性,比如,扫地机器人,订外卖。
手把手教你用LangChain打造会思考的AI助手(附代码) | 何三笔记 | 2025年02月22日 16:08:
交互逻辑
Q:
你是一个居家生活小助手,可以回答用户的日常问题。
TOOLS:
------
You have access to the following tools:
[{'name': 'query_fruit_unit_price', 'description': '使用该工具可以查询到指定种类水果的单价', 'parameters': {'type': 'object', 'properties': {'fruit_name': {'type': 'string', 'description': '水果名称'}}, 'required': ['fruit_name']}}]
To use a tool, please use the following format:
\```
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [query_fruit_unit_price]
Action Input: the input to the action
\```
Then wait for Human will response to you the result of action by use Observation.
... (this Thought/Action/Action Input/Observation can repeat N times)
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
\```
Thought: Do I need to use a tool? No
Final Answer: [your response here]
\```
Begin!
New input: 我想买2个苹果和3根香蕉,一共需要多少钱?
A:
Thought: Do I need to use a tool? Yes
Action: query_fruit_unit_price
Action Input: {"fruit_name": "苹果"}
Q:
Observation: 2.8
A:
Thought: Do I need to use a tool? Yes
Action: query_fruit_unit_price
Action Input: {"fruit_name": "香蕉"}
Q:
Observation: 2.1
A:
Thought: Do I need to use a tool? No
Final Answer: 已知苹果单价是2.8元,买2个苹果花费2.8×2 = 5.6元;香蕉单价是2.1元,买3根香蕉花费2.1×3 = 6.3元。所以一共需要5.6 + 6.3 = 11.9元。
示例参考自:DeepSeek + ReAct 实现 Agent | LLM之美 | 2025年03月05日 13:30:本文是一个综合实战,基于DeepSeek模型强大的推理能力,再结合 ReAct 框架的驱动,快速搭建了一个AI Agent。
ReAct的控制逻辑:
法1编码。最多迭代 max_iterations(如10) 次,若连续出错 max_retries(如2) 次则终止。
while max_iterations:
# response = llm.send_msg(messages)
# observation=response.Action_tool(response.Action Input)
messages.append({"role": "user", "content": f"Observation: {observation}"})
except Exception as e:
messages.append(("ERROR", str(e), ""))
if retry_count >= max_retries:
return f"Error: {e}"
与模型的交互过程中,出现异常,记日志
- 网络异常,重试
- 模型回复异常,反馈给模型。如
[错误上下文] 上一步操作失败原因: {error_ctx['reason']} 建议操作方向: {error_ctx['suggestion']} 可用工具列表: {', '.join(self.tools.keys())} - 工具调用异常,如文件不存在,工具不可用,报错(通知用户友好提示)
法2 agent:Agentic RAG:自主AI代理如何改变信息检索 | AI智能践行 | 2025年04月17日 19:30:检索增强生成(RAG)是一种通过外部知识源来增强大语言模型(LLM)输出的方法。 - agent 决定:是否、何时以及如何检索
框架对比
不同的应用框架,有不同的 ReAct 实现方式。
| LangChain | AutoGPT | MetaGPT |
|---|---|---|
| Question: {input} Thought: 我需要{思考步骤} Action: {工具名} Action Input: {工具输入} Observation: {工具返回结果} ...(循环直到得到答案) Final Answer: |
你的目标是:{objective}。你拥有以下能力: 1. 上网搜索 2. 读写文件 3. 执行代码 每次输出格式: THOUGHTS: {当前思考} REASONING: {逻辑推理} PLAN: {下一步计划} CRITICISM: {自我反思} NEXT ACTION: COMMAND={工具名}, ARGS= |
你是一个{角色},任务:{task}。可用工具: - 设计架构 - 生成代码 - 文档编写 输出格式: THINK: {分析任务步骤} USE TOOL: {工具名} WITH INPUT {参数} FEEDBACK: |
延伸:
大模型技术内参:39 种提示工程 在 29 种 NLP 任务精度对比 - 飞书云文档
| 提示方法 | 实现方式 | 改进点 | 适用场景 |
|---|---|---|---|
| 基础/标准/普通提示 | Question: {输入} Answer: |
简单直接,是其他策略基础 | 简单任务或低性能要求场景 |
| 思维链提示 (CoT) | Question: {输入} Thought: 首先我需要{步骤1},然后{步骤2},最后{步骤3} Answer: |
提升复杂推理能力 | 数学/常识/多跳推理任务 |
| 自我一致性 | Question: {输入} Path 1: {推理路径1} Path 2: {推理路径2} Final Answer: |
提升答案一致性 | 需要高准确率的推理任务 |
| 集成精炼 (ER) | Stage 1: {初步答案} Stage 2: 优化后的答案应考虑{因素1}和{因素2} Final Answer: |
分阶段优化回答 | 上下文无关问答 |
| 自动思维链 (Auto-CoT) | Cluster Questions: {相似问题组} Representative Solution: {典型推理链} Answer: |
消除人工示例依赖 | 数学/多跳推理任务 |
| 复杂思维链 (Complex CoT) | Question: {输入} Complex Reasoning: {包含多个中间变量的推理} Answer: |
处理复杂数据关系 | 表格数学问题等 |
| 思维程序 (PoT) | Question: {输入} Python Code: print({计算表达式})Answer: |
精确数值计算 | 数值推理任务 |
| 从简到繁 | SubQ1: {子问题1} SubA1: {答案1} SubQ2: 基于SubA1,{子问题2} Final Answer: |
问题分解策略 | 语言类复杂任务 |
| 符号链 (CoS) | Question: {空间问题} Symbolic Rep: A → B ← C Answer: |
空间关系符号化 | 空间问答任务 |
| 推理与行动 (ReAct) | Question: {输入} Thought: 我需要{思考步骤} Action: {工具名} Action Input: {参数} Observation: {返回结果} ... Final Answer: |
推理与行动交替 | 语言决策任务 |
| 数学提示器 (MathPrompter) | Equation: {代数表达式} Verification: 当x={值}时,左边={结果},右边={结果} Answer: |
数学验证机制 | 数学问题解决 |
| 思维树 (ToT) | Current State: {当前状态} Possible Branches: 1. {分支1} 2. {分支2} Chosen Path: |
树形搜索策略 | 开放域自由问答 |
| 验证链 (CoVe) | Baseline Answer: {初始回答} Verification Q: {验证问题} Revised Answer: |
自我验证机制 | 真实性验证任务 |
| 程序辅助语言模型 (PAL) | NL Steps: {自然语言步骤} Code: {Python代码}Answer: |
自然语言与代码结合 | 逻辑推理任务 |
| 元认知提示 (MP) | Understanding: {文本理解} Analysis: {矛盾点分析} Confidence Level: 高/中/低 |
五阶段认知过程 | 自然语言推理任务 |
| 联邦相同参数自我一致性 (Fed-SP-SC) | Paraphrased Q1: {同义问题1} Answer1: {答案} Paraphrased Q2: {同义问题2} Final Answer: |
同义问题增强 | 数学问题解决 |
| 产婆术提示 | Proposition Tree: - 命题A (置信度80%) ├ 支持论据1 └ 反对论据2 Conclusion: |
命题信任度评估 | 常识推理任务 |
各提示方法的核心prompt结构特征,其中:
- 粗体部分为固定结构标记
- { }内为动态内容占位符
- 特殊符号(如代码块)保留原格式
- 多阶段方法使用分层标记
- 需要工具交互的方法包含明确的Action-Observation循环
这种结构化prompt设计可有效引导LLM遵循特定推理模式,同时保持人类可读性。实际使用时需根据具体任务调整占位符内容和步骤复杂度。
模型从对话到自主
延伸至流行工具:从对话到自主行动:AI应用如何从 Chat 进化为 Agent?开源项目源码深度揭秘|得物技术 | 得物技术 | 2025年03月24日 18:31:告诉AI我们想要的目标或者任务,AI能够理解深度理解并分析我们的意图、自动的进行任务的拆解、自动的寻找可以使用的工具、自动的进行结果数据的汇总过滤、自动的呈现符合任务的展示形式。同时在任务处理过程中,可以自己完成异常的检测和修改。
- agent:调用模型并选择工具
- mcp(通用):获取数据源,工具调用的标准规范。
- 缺点:协议残缺,没有规定大语言模型和MCP的交互模式。
- 10行代码,实现你的OpenAPI MCP Server | 阿里云开发者 | 2025年05月06日 18:00:
- function call(模型定义):模型调用函数获取数据或执行操作
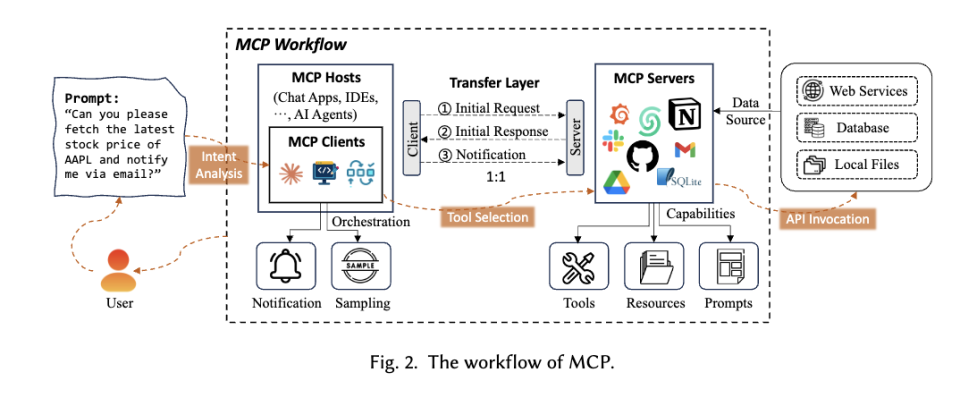
产品
kwindla/qwen3-baseten: qwen3 release day voice AI demo
- speech-to-text: @gladia_io
- llm Qwen 3 32B / SGLang / @basetenco
- bot:pipecat-ai/pipecat: Open Source framework for voice and multimodal conversational AI
- text-to-speech: @cartesia_ai